
国際特許分類[G10L15/04]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 音声認識 (6,879) | セグメンテーション,または語区切れ検出 (272)
国際特許分類[G10L15/04]に分類される特許
81 - 90 / 272
自動音声テキスト変換のためのシステムと方法

音声認識が、近い実時間に実行されてかつイベントかつイベント・シーケンスを利用して、ブーストされたクラシファイヤ、アンサンブル、検出器かつカスケードを含んでいる機械学習技術を利用し、かつ、知覚クラスタを使用することによって改善される。音声認識も、縦並びに処理するものを使用して改善される。自動句読点挿入器は、認識されたテキスト・ストリームに句読点を挿入する。 (もっと読む)
音声認識による機器制御装置

【課題】
離れた場所から電気機器の制御を行う際に、リモコンを使う方法では、咄嗟のときにリモコンが見つからないという不便があり、またスイッチを使わずに音声認識を行う方法では、雑音などに誤反応することが多く煩わしい。
【解決手段】
最初にリモコン等を用いる手動モードで音声認識を行い、同時に音声認識の対象とすべき音入力データと、そうでない音入力データとを教師信号データベース120に蓄積する。蓄積された教師信号データをもとに、自動の判定パラメータ学習122を実行して判定パラメータデータベース124を作成し、十分に高い精度が得られるようになったら自動モードに移り、音入力データの音声・非音声自動判定114を実行する。
(もっと読む)
目的信号区間推定装置、目的信号区間推定方法、目的信号区間推定プログラム及び記録媒体
【課題】方向性の雑音や拡散性の雑音が含まれる環境であっても、信号の音源数や到来方向を事前に知ることなく、精度よく目的信号区間を推定する。
【解決手段】複数のセンサで観測された各信号を所定の時間区間であるフレーム毎に切り出し、切り出された各センサについての各フレームの信号を周波数領域に変換し、周波数領域信号を各センサについて生成する。また、基準センサに対応する周波数領域信号を基準として、当該基準センサ以外のセンサに対応する各周波数領域信号を正規化し、信号の到来方向に対応する正規化信号値を生成し、それを用いて量子化された到来方向ごとの空間パワー分布値を求め、その統計的性質の時間変化に基づいて各フレームが目的信号区間に対応するか否かを判定する。
(もっと読む)
システム制御方法及び信号処理システム
システム制御方法は、ユーザの環境において入力装置(14-16)を介してユーザにより通信された情報を表す少なくとも1つの信号を取得し、第1のソース(1,2)からの信号は、環境において認知できる形式で利用可能であり、第1のソース(1,2)から生じる情報とユーザから生じる情報との間の遷移が生じることが想定される時点を少なくとも推定し、予想時間に関してシステムによる機能の実行をタイミング調整することを含む。 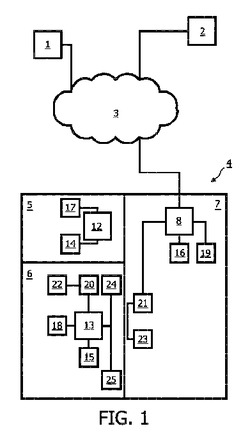 (もっと読む)
(もっと読む)
画像処理装置、画像処理プログラム及び画像処理方法
【課題】動画データや音声データにおけるキーワードの位置まで検索することができる画像処理装置、画像処理プログラム及び画像処理方法を提供する。
【解決手段】文書データに係る音声データについて、予め音声認識によってテキストデータを作成すると共に、テキストデータと音声データとを対応する位置において区切る区切り位置を決定しておく。キーワード検索時にテキストデータにキーワードが検出されたら、そのキーワードの直前の区切り位置から音声データを再生する。
(もっと読む)
複数信号区間推定装置、複数信号区間推定方法、そのプログラムおよび記録媒体
【課題】音声の収録中に話者位置の移動が生じても、同一話者には同一インデックスを付与することを可能とする。
【解決手段】周波数領域変換部110が観測信号を所定長のフレームに順次切り出して当該フレームごとに周波数領域に変換し、音声区間推定部120が周波数領域の観測信号に基づき、各フレームが音声区間に該当するか否かを推定し、到来方向推定部130が周波数領域の観測信号に基づき、当該周波数領域の観測信号の到来方向を各フレームごとに推定し、到来方向分類部140が音声区間に該当すると推定された各フレームを、到来方向の類似性に基づき話者ごとのクラスタに分類する。そして、話者同定部250が所定の時刻までに同一クラスタに分類された各フレームの周波数領域の観測信号に基づき、当該クラスタに係る話者のモデルをクラスタごとに作成し、当該所定の時刻以降の観測信号の話者を各話者のモデルに基づき推定する。
(もっと読む)
録音装置
【課題】出席者の発言区間や非発言区間を区分して表示するとともに、各区間の雰囲気を一覧表示することができる録音装置を提供する。
【解決手段】録音端末1では、収音部10が収音した音声を、解析部11が会議出席者の発言ごとの区間に区分するとともに、各区間の情況を解析する。再生端末2では、各発言者の発言区間および非発言区間をタイムチャート形式で表示するとともに、各区間の情況を示すマークを表示し、そのマークに基づいて区間を選択して個別に再生できるようにする。
(もっと読む)
目的信号区間推定装置、目的信号区間推定方法、目的信号区間推定プログラム及び記録媒体
【課題】雑音環境下であって、なおかつ、目的信号の到来方向を正確に知ることが出来ない状況において、少ない計算量で精度よく目的信号区間を推定する。
【解決手段】複数のセンサで観測された各信号を所定の時間区間であるフレーム毎に切り出し、切り出された各センサについての各フレームの信号を周波数領域に変換し、時間周波数ビン毎の周波数領域信号を各センサについて生成する。また、基本周波数を推定し、基本周波数又はその倍音成分近傍のグリッドのみについて、基準センサに対応する周波数領域信号を基準として、当該基準センサ以外のセンサに対応する各周波数領域信号を正規化し、時間周波数ビン毎の正規化信号値を生成する。そして、グリッド毎に正規化信号値の偏在性を示す偏在値を求め、それらを用いてフレーム毎の偏在性を示す偏在性指標値を算出し、当該偏在性指標値を指標とし、各フレームが目的信号区間に対応するか否かを判定する。
(もっと読む)
字幕出力装置、字幕出力方法及びプログラム
【課題】リアルタイム放送において、少ない遅延で字幕を出力することができる字幕出力装置、字幕出力方法及びプログラムを提供する。
【解決手段】字幕単位文生成部14は、入力されたテキスト文を字幕の出力単位に分割することにより、複数の字幕単位文を生成する。音声認識単位文生成部13は、入力されたテキスト文を音声認識の処理単位に分割することにより、複数の音声認識単位文を生成する。ビタビネットワーク生成部15は、各音声認識単位文の音声認識用のビタビネットワークと、字幕先頭検出用ネットワークとを生成する。音声認識部16は、テキスト文が発声された音声とビタビネットワークを構成する各認識候補文節とを逐次照合を行うことにより音声認識処理を行う。字幕単位文出力部17は、字幕先頭検出用ネットワークを構成する認識候補文節全体の音声認識処理が終了した時点で、対応する字幕単位文を出力する。
(もっと読む)
発話区間検出装置
【課題】複数のマイクが不要で、単チャネルの音声に対しても適用可能な発話区間検出装置を提供する。
【解決手段】発話区間検出装置22は、音響データを所定時間ごとにフレームに分割するフレーム分割部23と、フレーム分割部23により分割された音響データをフレームごとに高速フーリエ変換する高速フーリエ変換部14と、高速フーリエ変換部24によりフーリエ変換された音響データを微分して微分係数を算出する微分部25と、微分部25により算出された微分係数の度数分布に基づいて音声を含む音声フレームを判定する音声フレーム判定部26とを備える。
(もっと読む)
81 - 90 / 272
[ Back to top ]