
国際特許分類[G10L15/04]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 音声認識 (6,879) | セグメンテーション,または語区切れ検出 (272)
国際特許分類[G10L15/04]に分類される特許
11 - 20 / 272
音声記録サーバ装置及び音声記録システム
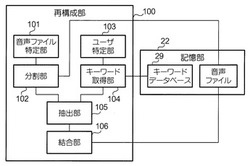
【課題】目的の音声の劣化を抑えつつ不要な音を除去または低減して記録するとともに、ユーザが所望する情報を効率よく提供することを可能とする技術を提供すること。
【解決手段】音声記録サーバ装置(20)は、話者の音声を表す第1音信号を話者の音声以外の音を表す第2音信号に基づいて加工し、第1音信号に含まれる話者の音声以外の音に起因する音信号成分が除去または低減された加工済み音信号を生成する音信号加工部(27)と、加工済み音信号を音声ブロックに分割する分割部(102)と、複数のユーザの各々に対し登録されたキーワードを格納したデータベース(29)から、特定されたユーザに対して登録されたキーワードを取得する取得手段(104)と、取得されたキーワードを含む音声ブロックを抽出する抽出手段(105)と、抽出された音声ブロックを結合して再構成された音信号を生成する結合手段(106)とを有する。
(もっと読む)
話者判別装置、話者判別プログラム及び話者判別方法

【課題】話者の判別を簡易かつ正確に行うことを課題とする。
【解決手段】話者判別装置50は、2人の話者に配置されるマイクから2つの音声データを取得する。さらに、話者判別装置50は、2つの音声データの各々をフレーム化する。さらに、話者判別装置50は、第1の確率モデルに基づいて、フレームが有声音領域又は無声音領域のいずれであるかを識別する。さらに、話者判別装置50は、有声音領域であると識別されたフレームの識別結果を有効又は無効とするかを決定する。このとき、話者判別装置50は、2つの音声データのエネルギー比を複数の確率分布が混合するモデルにモデル化した上でフレーム間のエネルギー比が複数の確率分布のうちいずれに属するかに応じて先の決定を行う。さらに、話者判別装置50は、第2の確率モデルに基づいて、有効又は無効が決定された後のフレームの識別結果から2つの音声データにおける発話領域及び沈黙領域を識別する。
(もっと読む)
音声認識装置、ロボット、及び音声認識方法
【課題】過応答を低減しつつ、音声認識の認識率を高める、ことを目的とする。
【解決手段】音声認識装置40は、被写体を撮像すると共に被写体を示す画像情報をカメラ30によって取得し、該カメラ30による撮像が行われているときに発生している音を示す音情報をマイク32によって取得する。そして、音声認識装置40は、カメラ30によって取得された画像情報に基づいて、人が発話している発話区間を検出し、検出した発話区間において、発話区間が検出されない場合に比べて、音情報に基づいた人の音声認識の感度を上げる。
(もっと読む)
対話装置
【課題】音声認識の認識結果を早期確定して逐次認識結果を出力することができるとともに、早期確定するフレームの間隔を短くした場合であっても、認識率の低下を抑制することができる対話装置を提供する。
【解決手段】対話装置1は、音声認識の認識区間を設定する認識区間設定手段20と、音声認識を行う音声認識手段30と、音声認識の認識結果の中に所定のキーフレーズが含まれる場合、これに対応した応答行動を決定する応答行動決定手段40と、決定された応答行動を実行する応答行動実行手段50と、を備え、認識区間設定手段20が、既に設定された認識区間の認識終了位置を、当該認識終了位置から所定の時間長だけ進んだ位置のフレームに繰り返し更新することで複数の認識区間を設定し、音声認識手段30が、認識終了位置の異なる複数の認識区間のそれぞれについて音声認識を行う。
(もっと読む)
音認識方法及び装置
【課題】雑音環境下における対象音の音区間を検出可能とする音認識方法及び装置の提供。
【解決手段】雑音環境下における周期定常性を持つ対象音の音区間を検出可能とする音認識方法であって、音入力手段によりアナログ音響信号を採取し、フレームによって構成されるデジタル波形信号に変換する第1ステップと、デジタル波形信号をフレーム単位で解析して自己相関関数及び2次自己相関関数を算出する第2ステップと、各フレームについて算出した2次自己相関関数の差分絶対値の和が予め設定した閾値を超える範囲を音区間と判定する第3ステップと、を有することを特徴とする音認識方法およびその装置。
(もっと読む)
音声区間判定装置、音声区間判定方法、及びプログラム
【課題】入力信号の音声区間と非音声区間との判定精度を向上する。
【解決手段】音声区間判定装置100は、入力信号をフレーム単位に分割するフレーム分割部101と、上記フレーム分割部により分割されたフレームについて分析長毎のパワースペクトルを算出するパワースペクトル算出部102と、上記パワースペクトル算出部により算出されたパワースペクトルの強度を増加させるパワースペクトル操作部103と、上記パワースペクトル操作部により強度が増加されたパワースペクトルを用いてスペクトルエントロピーを算出するスペクトルエントロピー算出部104と、上記スペクトルエントロピー算出部により算出されたスペクトルエントロピーの値に基づいて、上記入力信号が音声区間であるか否かを判定する判定部105と、を有する。
(もっと読む)
話者状態検出装置、話者状態検出方法及び話者状態検出用コンピュータプログラム
【課題】対話中の複数の話者のうちの少なくとも一人の状態を、その対話の際の音声に基づいて正確に検出可能な話者状態検出装置を提供する。
【解決手段】話者状態検出装置(1)は、第1の話者の発した第1の音声及び第2の話者の発した第2の音声を取得する音声入力部(2、3)と、第1の音声に含まれる第1の話者の第1の発話区間と、第2の音声に含まれ、第1の発話区間よりも前に開始される第2の話者の第2の発話区間との重畳期間、または第1の発話区間と第2の発話区間の間隔を検出する発話間隔検出部(11)と、第1の発話区間から第1の話者の状態を表す状態情報を抽出する状態情報抽出部(12)と、重畳期間または間隔と状態情報とに基づいて第1の発話区間における第1の話者の状態を検出する状態検出部(13、14、17)とを有する。
(もっと読む)
音声入力装置、通信装置、及び音声入力装置の動作方法
【課題】マイクロフォンの集音状態を的確に通話者に報知することが望まれている。
【解決手段】音声入力装置100は、通話者の発声に伴う音を集音するマイクロフォン10と、マイクロフォン10から供給される音声波形の処理に基づいて、通話者の発声が入力されている期間に対応する音声入力期間を検出し、音声入力期間であるか否かを示す判定信号Sig_RDを出力する音声区間判定部31と、音声区間判定部31の出力に基づいて、音声区間判定部31による音声入力期間の検出状態を通話者に対して報知する報知部(LEDドライバ33及びLED50)と、を備える。
(もっと読む)
子音識別装置、およびプログラム
【課題】オーディオ信号における子音区間を簡単で処理負荷の軽い信号処理で確実に識別することを可能にする。
【解決手段】オーディオ信号の波形を表すサンプル列を所定サンプル数のブロックに区切り、ブロック毎に当該ブロックにおける全周波数成分のエネルギーと当該ブロックにおける所定の周波数帯域に属する周波数成分のエネルギーとを各々算出し、両者の比を算出する。加えて、各ブロックの単位時間当たりのゼロクロス数をカウントする。そして、上記エネルギー比、および隣接するブロック間でのゼロクロス数の変化態様に基づいてブロック毎に当該ブロックが子音区間に含まれるものであるか否かを判定する。
(もっと読む)
音声誤検出判別装置、音声誤検出判別方法、およびプログラム
【課題】様々な雑音環境化において音声認識の精度を向上させることが可能な音声誤検出判別装置、音声誤検出判別システム、音声誤検出判別方法、およびプログラムを提供する。
【解決手段】入力信号取得部は、所定方向の音源からの音声を含む周囲音を複数のマイクによりそれぞれ収音した複数の音声信号を取得する。認識結果取得部は、音声信号に基づく音声認識を行った結果検出された、音声信号の音声区間を示す音声区間情報を含む認識結果を取得する。到来率算出部は、それぞれの複数の音声信号の単位時間毎の信号と所定方向とに基づき、単位時間における所定方向からの音声が周囲音に占める割合を示す音声到来率を算出する。誤り検出部は、認識結果と音声到来率とに基づき、音声区間情報が誤検出でないか否かを検出する。これにより、音声認識による音声区間の誤検出を判別できる。
(もっと読む)
11 - 20 / 272
[ Back to top ]