
国際特許分類[G10L15/04]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 音声認識 (6,879) | セグメンテーション,または語区切れ検出 (272)
国際特許分類[G10L15/04]に分類される特許
21 - 30 / 272
情報処理装置、情報処理方法、情報処理システム、およびプログラム
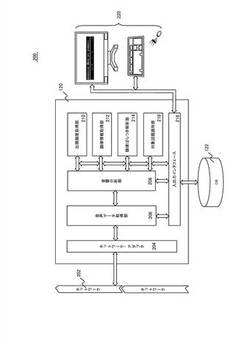
【課題】言語では明示的に認識されない情報を反映する語句を分析するための情報処理装置、情報処理方法、情報処理システム、およびプログラムを提供する。
【解決手段】情報処理装置120は、会話を記録した音声データから当該音声データにおける言語では明示されない情報を識別しており、音声データを音響データを使用して音響分析するための音響分析部208と、音声データの前後がポーズで分離された領域を識別し、識別された領域の音響分析により前記識別された領域の語句を識別し、当該語句の韻律特徴値を要素とする当該語句の1以上の韻律特徴値を生成する韻律情報取得部212と、音響分析部208が取得した語句の音声データにおける出現頻度を取得する出現頻度取得部210と、出現頻度の高い語句の韻律特徴値の前記音声データ中におけるばらつき度を計算し、特徴語句を決定する韻律ばらつき解析部214とを含む。
(もっと読む)
状況認知型音声認識方法

【課題】 小型情報機器で使用される埋込型システム上で音声認識の前処理によって音声入力データの動的状況認知パラメータDIPを推定して音声が認識できる耐雑音化技術が不可欠である。
【解決手段】
本発明による音声認識方法は、図1の状況認知前処理部S1によるA/D変換部の出力になる音声入力データに対して動的状況認知パラメータDIPを算出、算出された動的状況認知パラメータDIPの情報により次の処理部分を決定するインタープリターと、可変雑音処理基準パラメータRTHを算出する状況認知変数推定部を構成しておく。動的状況認知パラメータDIPの基準で状況認知変数IPを生成する状況認知生成部と可変雑音処理基準パラメータRTHと状況認知変数IPを比較する分配部を軽由、音声区間を抽出して音声区間以外部分の雑音を減少/除去する音声抽出処理や騒音やデバイス雑音を除去する雑音処理を使用して音声認識前処理を行う。
(もっと読む)
出力オーディオ信号が生ずる間に入力音声信号を処理する方法および装置
【課題】入力音声信号を処理する方法および装置を提供すること。
入力音声信号の開始は、決定される(701)際の出力オーディオ信号に対する、出力オーディオ信号と入力開始時間との生成の間に検出される。入力開始時間は、次に、入力音声信号に応答するのに使用されるために提供される(704)。入力音声信号が、出力オーディオ信号が生ずる間に検出されるとき、出力オーディオ信号の識別は、入力音声信号に応答するのに使用されるために提供される。データおよび/または制御信号を備えている情報の信号(705)は、少なくとも提供されるコンテキスト上の情報、すなわち、入力開始時間および/または出力オーディオ信号の識別に応じて提供される。本発明は、基礎をなす通信システムの遅延特性にかかわらず、出力オーディオ信号に対する入力音声信号のコンテキストを精密に確立する。
(もっと読む)
発話抽出プログラム、発話抽出方法、発話抽出装置
【課題】対話時の発話から特定の発話を抽出する発話抽出プログラム、発話抽出方法、発話抽出装置を提供する。
【解決手段】第1の話者および第2の話者の発話区間を抽出して、日時または経過時間に関連付けて記録させる処理と、特徴操作記憶部を参照して、対話中に機器を第1の話者が操作した機器の状態を、日時または経過時間に関連付けて記録した操作情報から、特徴操作テーブルに合致する操作情報を抽出し、抽出した操作情報の発生した日時または経過時間を示す特徴操作時刻情報を取得させる処理と、発話抽出条件を参照して、発話抽出条件に合致する区間を、第1の話者および第2の話者の抽出した発話区間と抽出した特徴操作時刻情報を用いて抽出し、抽出した合致する区間から発話抽出条件に関連付けられている時間範囲に存在する第1の話者の発話区間に対応する発話を抽出させる処理と、をコンピュータに実行させる発話抽出プログラム。
(もっと読む)
音声判定装置および音声判定方法
【課題】ノイズレベルに拘らず、入力信号の音声区間を検出する。
【解決手段】音声判定装置100は、入力信号をフレーム単位で切り出し、フレーム化入力信号を生成するフレーム化部120と、フレーム化入力信号を変換して、周波数毎のスペクトルを集めたスペクトルパターンを生成するスペクトル生成部122と、スペクトルパターンの各スペクトルのエネルギーと、分割周波数帯域のうちスペクトルが含まれる分割周波数帯域における帯域別エネルギーとのエネルギー比が第1閾値を超えるか否かを判定するピーク検出部132と、判定結果に基づいて、フレーム化入力信号が音声であるか否かを判定する音声判定部134と、スペクトルパターンの各分割周波数帯域におけるスペクトルの周波数方向の平均エネルギーを導出する周波数平均部126と、分割周波数帯域毎に、平均エネルギーの時間方向の平均である帯域別エネルギーを導出する時間平均部130とを備える。
(もっと読む)
情報処理装置およびその動作方法
【課題】 予め動画像の撮影者の声を登録することなく、動画像の撮影者の声を決定する。
【解決手段】 本発明に係る情報処理装置は、複数の音声区間に対応する音声を表す第1のデータストリームから、該音声に対応する動画像の撮影者の声を決定する情報処理装置であって、前記第1のデータストリームと、複数の画像からなる前記動画像を表す第2のデータストリームとを取得し、前記複数の画像のうち、人物を示すオブジェクトが含まれない画像を特定し、特定された画像に対応する前記音声区間のうち、声に相当する区間における音に基づいて、前記動画像の撮影者の声を決定する。
(もっと読む)
抽出装置、抽出方法、プログラム、及びプログラムを配信する情報処理装置
【課題】複数の単語を連続的に音声として入力した場合においても、ユーザの利便性を低下することなく、より適切な区切りの位置を抽出できる抽出装置を提供すること。
【解決手段】入力された音声について適切な単語の区切りを抽出する抽出装置100であって、入力された音声に基づく音声データ150について対応する発音記号を生成する発音記号生成部111と、ユーザにより入力された検索クエリ170に基づく文字列を記憶する検索クエリDB105と、発音記号に対応する文字列を、検索クエリDB105から抽出する抽出部113と、を備える。
(もっと読む)
音声認識装置及び音声認識方法
【課題】会話のような比較的長い音声データから特定のキーワードを認識する精度を向上できる音声認識装置を提供する。
【解決手段】音声認識装置1は、音声データの一部が分類される複数の区分の何れかに対応する複数の単語辞書を記憶する記憶部3と、処理部4とを有する。処理部4は、音声データから複数の会話区間を検出する会話区間検出機能11と、音声データから複数の発声区間を検出する発声区間検出機能12と、複数の発声区間のそれぞれを、複数の会話区間のうちのその発声区間が属する会話区間の順序に応じて複数の区分の何れかに分類する区間分類機能13と、少なくとも一つの発声区間について、複数の単語辞書のうち、発声区間が分類された区分に対応する単語辞書を記憶部から取得する単語辞書選択機能14と、発声区間の少なくとも一つから、その発声区間について取得された単語辞書を用いて特定のキーワードを検出する検出機能15とを実現する。
(もっと読む)
音声区間検出方法、音声認識方法、音声区間検出装置、音声認識装置、そのプログラム及び記録媒体
【課題】雑音や対象とする人以外の音声を含むような音信号から、対象とする人の音声区間を正確に検出する音声区間検出方法及び装置を提供することを目的とする。
【解決手段】音信号を所定の長さのフレームごとに取り出し、そのフレームの音信号を解析し、そのフレームの音信号に対象とする話者の音声が含まれるか否かを判定し、判定結果を音声/非音声判定値として求め、音信号の中に含まれる認識単位の系列と、各認識単位の発話時間情報とを求め、音声/非音声判定ステップにおいて得られるフレームごとの音声/非音声判定値と、音声認識ステップにおいて得られる認識単位の系列及び各認識単位の発話時間情報とを受け取って、認識単位の発話時間に対応するフレームの音声/非音声判定値の集計値の大小に基づいて、認識単位ごとに対象とする話者によって発話されたか否かを判定する。
(もっと読む)
マーカー設定方法およびマーカー設定装置
【課題】オーディオ情報の再生スタート時点を選択できるようにするためのマーカー指定に関し、誤って挿入されたマーカーの位置をユーザの意図する位置と一致するように修正する。
【解決手段】マーカー設定方法は、複数の無声領域および有声領域を含むオーディオ情報を受信するステップと、選択されたマーカー挿入時点に対する選択を受信するステップと、受信された選択および受信されたオーディオ情報に基づいて、選択されたマーカー挿入時点が有声領域に存在するかを判断するステップと、選択されたマーカー挿入時点が前記有声領域上に存在すると、受信されたオーディオ信号内の複数の無声領域の中で無声領域の時刻を決定し、決定された無声領域の時刻に対応するようにマーカーを設定するステップとを含む。
(もっと読む)
21 - 30 / 272
[ Back to top ]