
国際特許分類[G10L15/22]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 音声認識 (6,879) | 音声認識処理中の手順,例.マン・マシン対話 (884)
国際特許分類[G10L15/22]に分類される特許
51 - 60 / 884
音認識装置
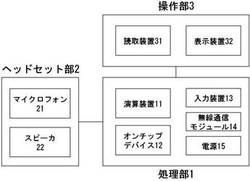
【課題】両手がふさがった状態でも、正解文字列と実際に記載されている文字列との照合作業を音声により行うことを可能とする音認識装置の提供。
【解決手段】装着者の音声を検出するマイクロフォンと、装着者に音声情報を伝達するスピーカと、正解文字列を読み取るための読取装置と、処理装置と、を備えるハンズフリー型の音声認識装置であって、処理装置が、装着者の読み上げた文字列を音声認識処理し、読取装置で読み取った正解文字列とのマッチングを行い、マッチングの判定結果を出力することを特徴とする音声認識装置。
(もっと読む)
音声認識装置、音声認識方法及び音声認識プログラム

【課題】音声認識結果における認識の誤りがある区間の認識及び修正を容易にする。
【解決手段】音声認識装置1は、音声認識処理結果における区間ごとに保留指定の入力を受け付ける指定受付部16と、保留指定された保留区間をその他の区間と識別可能に表示する保留区間表示部18とを有するので、音声認識処理結果において修正を要する区間の認識が容易となる。そして、音声認識装置1は、保留区間の語句を編集可能に制御する編集制御部19と、当該保留区間に対する文字列の入力を受け付ける修正入力受付部20とを更に備えるので、保留区間の語句の修正が実施される。従って、保留区間の修正が容易となる。
(もっと読む)
音声命令語処理装置及びその方法
【課題】使用者との相互作用(Interaction)に基づき音声命令語テーブルを更新することにより、別の音声命令語を入力する過程を必要とせずに、音声認識率を高める音声命令語処理装置及びその方法を提供する。
【解決手段】
本発明は、音声命令語テーブルを格納している格納手段、使用者から音声命令語の入力を受ける音声命令語入力手段、前記音声命令語テーブルに基づき、前記音声命令語入力手段を介して入力された音声命令語を認識する音声命令語認識手段、及び前記音声命令語認識手段が非正常音声命令語と認識した場合、前記入力された音声命令語に係る類似命令語を前記使用者に提供し、前記使用者から選択された類似命令語に前記入力された音声命令語をリンクさせ、前記音声命令語テーブルを更新する音声命令語処理手段を含むことを特徴とする。
(もっと読む)
入出力デバイス情報を考慮したマルチモーダル対話プログラム、システム及び方法
【課題】1つの対話シナリオを設計するだけで、様々な入出力デバイスを搭載した端末毎に、異なる対話シナリオを進行させるマルチモーダル対話プログラムを提供する。
【解決手段】状態sで可用な各デバイス行動aにおけるデバイス行動確率r(sd0,ad0)を蓄積したデバイス行動確率蓄積手段と、デバイス種別の有無を取得するデバイス種別取得手段と、端末のデバイス種別の有無とr(sd0,ad0)とを乗算し、デバイス可用報酬値r(sd,ad)を算出するデバイス可用報酬値算出手段と、状態sに、行動aを実行した際に得られる報酬期待値r(s0,a0)に対して、r(sd,ad)を重み付けた報酬期待値r(s,a)を算出する報酬期待値算出手段と、報酬期待値rを用いて、報酬Vtが最大となるように、状態sにおける行動aを決定する部分観測マルコフ決定過程POMDP手段と、行動aに基づく対話シナリオを端末へ送信する対話シナリオ送信手段とを有する。
(もっと読む)
音声認識装置及び音声認識方法
【課題】本装置を含む機器本体の動き又は状態の少なくとも一方を検出して、容易にかつ確実に動作モード切替えを行える音声認識装置を提供する。
【解決手段】実施形態によれば、音声入力部11と、加速度センサを備え、機器本体の動き又は状態もしくはその両方を検出する状態検出部12と、予め定めた機器本体の動き又は状態の動き・状態パターンモデルとそのモデルに対応する予め定めた複数の音声認識処理パターンとを記憶する保持部13と、状態検出部からの機器本体の動きまたは状態もしくはその両方と、保持部13に記憶された動き・状態パターンモデルとがマッチングするか否かを検出し、そのマッチングしたモデルに対応した音声認識処理パターンを検出するパターン検出部14と、検出された音声認識処理パターンに従い、音声入力部からのデジタル信号に対して音声認識処理を実行する音声認識処理実行部15と、を具備する。
(もっと読む)
音声誤検出判別装置、音声誤検出判別方法、およびプログラム
【課題】様々な雑音環境化において音声認識の精度を向上させることが可能な音声誤検出判別装置、音声誤検出判別システム、音声誤検出判別方法、およびプログラムを提供する。
【解決手段】入力信号取得部は、所定方向の音源からの音声を含む周囲音を複数のマイクによりそれぞれ収音した複数の音声信号を取得する。認識結果取得部は、音声信号に基づく音声認識を行った結果検出された、音声信号の音声区間を示す音声区間情報を含む認識結果を取得する。到来率算出部は、それぞれの複数の音声信号の単位時間毎の信号と所定方向とに基づき、単位時間における所定方向からの音声が周囲音に占める割合を示す音声到来率を算出する。誤り検出部は、認識結果と音声到来率とに基づき、音声区間情報が誤検出でないか否かを検出する。これにより、音声認識による音声区間の誤検出を判別できる。
(もっと読む)
自動音声応答装置、音声応答処理システム及び自動音声応答方法
【課題】自動的な応答処理をより確実に機能させる。
【解決手段】実施の形態の自動音声応答装置は、音声認識部、応答処理実行部及び管理情報更新部を備える。音声認識部は、入力された音声を音声認識して文字データを取り出す。応答処理実行部は、応答処理の内容と文字データとを予め関連付けて登録した管理情報に基づいて、音声認識の結果に対応した応答処理を実行する。管理情報更新部は、音声認識により得られた文字データが管理情報中に未登録であった場合、管理情報中に登録済みの応答処理の内容のいずれかを未登録の文字データと新たに関連付ける。
(もっと読む)
音声認識装置及び音声認識処理方法
【課題】 音声認識処理を行う場合に、優先度に応じて音声認識処理を行うことができる音声認識装置及び音声認識処理方法を提供することを目的とする。
【解決手段】 音声認識装置300は、音声データを外部から取得し、取得した音声データを一次出力データベース303へ記録し、一次出力データベース303に記録される音声データを、処理すべき優先度に応じた条件を記憶する優先度メモリ305に記憶される条件と比較し、条件に一致した音声データをその条件の優先度に応じて音声認識処理を行わせる。音声認識処理された音声認識結果は、音声認識結果データベース300Dへ格納される。
(もっと読む)
音声記録装置、方法及びプログラム
【課題】音声信号を記録する音声記録装置において、ユーザの作業負荷を軽減することができる音声記録装置、方法及びプログラムを提供する。
【解決手段】音声記録装置は、音声信号を記憶する音声記憶部と、音声信号について音声認識する音声認識部と、音声記憶部に記憶された音声信号に対する編集内容として、音声信号の並べ替えと補完と削除の少なくとも一つを音声認識を用いて推定する編集内容推定部と、編集内容推定部によって推定された編集内容に従って、音声記憶部に記憶された音声信号を編集し、編集結果を記録する音声編集部を備える。
(もっと読む)
音声認識装置、端末装置、音声認識システム、音声認識方法、入力方法及びプログラム
【課題】音声認識技術を利用してウェブページの入力フォームへの入力を支援する技術において、音声認識の精度を高める。
【解決手段】文字列とその読みがなとその属性情報とを対応付けた音声認識辞書を保持する辞書保持部11と、入力フォームに入力される情報の範囲を属性情報を用いて規定する複数の入力ルール各々を、ルール識別情報と対応付けて保持するルール保持部12と、複数の端末装置30各々から、ルール識別情報と音声データとを対応付けて受信する受信部13と、ルール識別情報をキーとしてルール保持部12を検索し、入力ルールを取得するルール取得部15と、取得した入力ルールに含まれる属性情報をキーとして音声認識辞書を検索し、読みがなを抽出する検索部16と、検索部16が抽出した読みがな、ルール取得部15が取得した入力ルールを利用して、音声データを文字列データに変換する変換部14とを有する音声認識装置10。
(もっと読む)
51 - 60 / 884
[ Back to top ]