
国際特許分類[G10L15/22]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 音声認識 (6,879) | 音声認識処理中の手順,例.マン・マシン対話 (884)
国際特許分類[G10L15/22]に分類される特許
11 - 20 / 884
議事録作成システム、議事録作成装置、議事録作成プログラム、議事録作成端末及び議事録作成端末プログラム
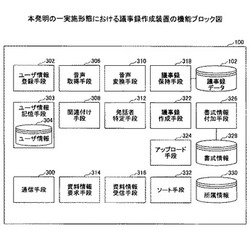
【課題】会議の議事録に記録された発話内容が、どの資料に関連するものであるのかが分かるようにすることを目的とする。
【解決手段】議事録作成装置は、ユーザが発話した場合に、当該発話したユーザが用いる情報端末に資料の情報を要求する資料情報要求手段と、前記ユーザの発話内容と前記資料の情報とを関連付けた議事録を作成する議事録作成手段と、を有し、前記情報端末は、前記資料情報要求手段からの要求を受けつける資料情報要求受付手段と、前記資料情報要求受付手段が前記要求を受け付けた場合に当該端末が表示中の前記資料の情報を取得する資料情報取得手段と、取得された前記資料の情報を前記議事録作成装置に送信する資料情報送信手段と、を有する、議事録作成システムを提供する。
(もっと読む)
対話モデル構築装置、方法、及びプログラム

【課題】3回以上のやりとりが少ない対話データを学習データとして用いた場合でも、精度の良い対話モデルを構築する。
【解決手段】部分集合抽出部12は、2回のやりとりの対話データを複数取得する。辞書データ20から見出し抽出部14が見出し語を抽出し、カテゴリ抽出部16がカテゴリ情報を抽出して、見出し語・カテゴリ情報のペアを作成する。部分集合抽出部12は、取得した対話データ内の各単語に見出し語・カテゴリ情報に基づいてカテゴリ情報を付与し、入力されたキーワードを単語及びカテゴリ情報に含む対話データを部分集合として抽出する。対話モデル学習部18は、部分集合を用いて、学習過程において2回のやりとりから、内容が近い発話データをクラスタリングすることで2回を超えるやりとりを構成しながらHMMを学習し、学習したHMMを対話モデルとして出力する。
(もっと読む)
不動産物件情報提供支援装置
【課題】ゲスト及びホストの音声に基づき、ゲストに提供しようとする不動産物件情報をより正確に検索できるようにする。
【解決手段】H/G判別部41は、異なる位置に着座するホストとゲストの音声を、集音方向を調整自在な指向性マイク22〜25による検出音の強度に基づき識別する。キーワードテーブル45には、質問キーワードと1つ以上の質問キーワードで分類される質問の種類毎の回答キーワードとが登録されている。キーワード判別部44は、識別されたホストの音声に、登録された質問キーワードのどれが含まれているか及び該質問キーワードに基づく質問の種類を判別し、識別されたゲストの音声に、直近の質問の種類に対応した、登録された回答キーワードのどれが含まれているかを判別し、判別した回答キーワードを該質問の種類と対応させて検索用キーワード記憶部46に記憶させる。
(もっと読む)
コミュニケーションロボット
【課題】使用者がロボットに向けて発話するとき、使用者がより話し易く、より親しみを感じることができるコミュニケーションロボットを提供する。
【解決手段】使用者が発する話し言葉を検知する音声検知手段と、所定の応答反応を表出する反応表出手段とを有したコミュニケーションロボットに、使用者の話し言葉に反応して予め定められた複数パターンの応答反応を表出させる。このとき、話し言葉が通常表現であるか否かの判定、話し言葉が同意要求表現であるか否かの判定、話し言葉が断定表現であるか否かの判定の少なくともいずれかの判定を実施し、判定結果に基づいて異なる応答反応を表出させる。
(もっと読む)
音響モデル適応装置、音響モデル適応方法、およびプログラム
【課題】パラメータ修正への寄与が大きく、かつ適応効果を低下させにくいデータを使って音響モデルの適応を行うことができる音響モデル適応装置を提供する。
【解決手段】本発明の音響モデル適応装置10は、音声認識部100が、入力された音声から、適応前音響モデルを用いて、音声認識結果テキストと信頼度を出力する。音声認識結果登録部200が、話者IDと音声と音声認識結果テキストと信頼度からなる音声認識結果を記憶する。苦手話者検出部300が、他の話者よりも音声認識精度が低い苦手話者の話者IDを抽出する。適応用データ選択部400が、話者IDが苦手話者の話者IDであり、かつ、信頼度が予め設定された信頼度閾値以上である音声認識結果を読み込み、適応用データを抽出する。音響モデル適応部500が、予め設定された適応パラメータを用いて、適応後音響モデルを出力する。
(もっと読む)
音声認識装置、方法及びプログラム
【課題】音声認識精度を向上することにある。
【解決手段】一実施形態に係る音声認識装置は、業務推定部、音声認識部及び特徴量抽出部を含む。業務推定部は、利用者の業務に関連する非音声情報を用いて利用者が行っている業務を推定し、該業務の内容を示す業務情報を生成する。音声認識部は、前記業務情報に対応する音声認識手法に従って前記利用者が発した音声情報に対して音声認識を行い、音声認識結果を生成する。特徴量抽出部は、前記音声認識結果から、前記利用者が行っている業務に関連する特徴量を抽出する。前記業務推定部は、少なくとも前記特徴量を用いて前記利用者の業務を再推定し、前記音声認識部は、再推定の結果得られる業務情報に基づいて音声認識を行う。
(もっと読む)
対話装置
【課題】自然な対話を実現することを課題とする。
【解決手段】対話装置は、発話セット記憶部と、発話セット取得部と、第1出力部と、検知部と、第2出力部とを有する。発話セット記憶部は、第1発話と、第1発話に対する応答として想定されるユーザによる発話に対する応答の発話を表す第2発話とを含んだ発話セットを記憶する。発話セット取得部は、発話セットを取得する。第1出力部は、取得された発話セットに含まれる第1発話を出力する。検知部は、第1発話が出力された後のユーザによる発話を検知する。第2出力部は、ユーザによる発話が検知された場合に、取得された発話セットに含まれる第2発話を出力する。
(もっと読む)
対話支援装置、方法及びプログラム
【課題】話者が異なる言語で又は同じ言語で対話をする場合に、対話に応じて知識を補うための情報を提示して対話を支援することを可能にする。
【解決手段】実施形態によれば、入力部、音声認識部、対話履歴データベース、推定部、判定部、生成部、選択部、提示部を含む。入力部は、話者間の対話の音声を入力する。音声認識部は、入力音声を音声認識して、対応するテキスト情報に変換する。対話履歴データベースは、テキスト情報の全部又は一部を対話履歴として記憶する。推定部は、テキスト情報に基づいて、発話行為を推定する。判定部は、推定された発話行為に基づいて、補足情報を提示するかどうか判定する。生成部は、補足情報を提示すると判定された場合に、補足情報の候補を生成する。選択部は、対話履歴を利用して、補足情報の候補のうちから、提示すべきものを選択する。提示部は、選択された補足情報を提示する。
(もっと読む)
音声処理装置及び音声処理装置の検査方法
【課題】実装された状態遷移モデルの評価において、時間などの要件に対するコストバランスを考慮した評価が可能な音声処理装置を提供する。
【解決手段】音声処理装置が、音声認識部と、状態遷移モデルと、前記音声認識部の認識結果を用いて前記状態遷移モデルの状態遷移を制御する第1の制御部と、を含み、前記第1の制御部は、第1の実行モードと第2の実行モードとを有し、前記第1の実行モードは、前記状態遷移モデルにおける分岐ノードの実行が1回であり、前記第2の実行モードは、前記分岐ノードの実行がすべての分岐に対して行われることが可能であることを特徴とする。
(もっと読む)
音声認識装置とその方法とプログラム
【課題】話題境界を跨がない長距離文脈情報を用いて認識スコアを再計算する音声認識装置を提供する。
【解決手段】話題境界検出部が、Nベスト候補列を入力として、当該Nベスト候補列中の現在発話区間を中心として当該現在発話区間から音声文書の冒頭方向にある順位1位の認識結果候補を過去発話単語集合として抽出すると共に、当該現在発話区間を中心として当該現在発話区間から音声文書の末尾方向にある順位1位の認識結果候補を未来発話単語集合として抽出し、過去・未来間関連度平均値と所定の閾値とを比較して音声文書の話題境界を判定する。Nベスト候補スコア再計算部は、話題境界検出部において話題境界と判定されなかった現在発話区間の認識スコアを、過去・現在間関連度合計値と現在・未来間関連度合計値の平均値を用いた値に再計算し、現在発話区間のNベスト候補を並べ替える処理を行う。
(もっと読む)
11 - 20 / 884
[ Back to top ]