
Fターム[5B064EA20]の内容
文字認識 (8,173) | 後処理 (1,120) | 修正、確定 (961) | 文字列の解析によるもの (315) | 構文、文法 (30)
Fターム[5B064EA20]に分類される特許
1 - 20 / 30
文字認識装置、文字認識結果処理システム及びプログラム
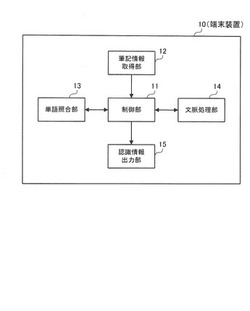
【課題】文字認識結果の候補を定義した情報を用いた文字認識で文字認識結果が得られなかった場合でも文字認識結果を得ることができ、誤認識の可能性があることを知らせることを可能にする。
【解決手段】端末装置10において、制御部11は、単語照合による文字認識を行うよう単語照合部13を制御し、単語照合部13から文字認識結果が返された場合には、その尤度が閾値以上であれば、文字認識結果を正しい結果として出力するよう認識情報出力部15を制御し、その尤度が閾値以下であれば、文字認識結果を誤認識の可能性がある結果として出力するよう認識情報出力部15を制御し、単語照合部13から文字認識結果が返されなかった場合には、文脈処理による文字認識を行うよう文脈処理部14を制御し、その尤度に関わらず、文字認識結果を誤認識の可能性がある結果として出力するよう認識情報出力部15を制御する。
(もっと読む)
文書処理装置

【課題】OCRにより誤認識された文字列を、正しい文字列に補正するための置換辞書を自動的に作成する。
【解決手段】業務文書を画像化したサンプル電子文書データから切り分けた正解文字列と、前記サンプル電子文書データに対してOCRを行った結果得られるOCR後サンプル文書データから切り分けたOCR後文字列と、を比較単位とし、誤認識の判定を行うマッチング処理部と、前記正解文字列を所定の単語単位に切り分け、該切り分けた単語のうち前記マッチング処理部で誤認識と判定された文字を含む単語を誤認識パターン候補として登録する解析処理部と、記憶装置に格納された日本語の単語が登録された日本語辞書データ及び業務で使用される単語が登録された業務単語辞書データに含まれる単語と部分一致または完全一致する単語を前記誤認識パターン候補から削除してフィルタリングし、該フィルタリング後の誤認識パターン候補を誤認識パターンとして前記記憶装置へ格納するフィルタリング処理部と、を備える。
(もっと読む)
走査された及びリアルタイムの手書き文字の識別を行う文字認識システム
【課題】言語的プロセッサを提供すること。
【解決手段】本発明によると、手書き文字認識システムにおいて用いられ、シーケンシャルな文字アレーを受け取り、文書の手書き文字の最も蓋然的な解釈を表す出力ストリングを発生する言語的プロセッサ(266)が提供される。本発明による言語的プロセッサは、文字ストリングの言語的な解析を実行する言語的アナライザ(274)と、文字ストリングのそれぞれの文字の最も蓋然的な意味を決定する字句アナライザ(290)と、から構成される。本発明による言語的プロセッサは、低レベル認識プロセッサの出力に接続され、文書の手書き文字の最も蓋然性のある解釈を表す出力ストリングを発生することができる。
(もっと読む)
テキスト処理装置及びプログラム
【課題】操作者が修正文字列を含む任意の文字列を修正用文字列として入力した場合に、その修正用文字列から修正文字列を自動抽出できるようにする。
【解決手段】被修正文字列指定部16は、入力操作部15を用いた操作者の入力操作に基づき入力テキスト中の修正されるべき文字列を被修正文字列として指定する。修正用文字列入力部17は、操作者の入力操作に基づき文字列の修正に用いられる修正文字列を含む修正用文字列を入力する。修正文字列抽出部20は、被修正文字列指定部16によって指定された被修正文字列と修正用文字列入力部17によって入力された修正用文字列とを比較することにより、当該修正用文字列の中から指定された被修正文字列と最も類似した文字列を修正文字列として抽出する。修正部21は、入力テキスト中の指定された被修正文字列を抽出された修正文字列に置き換えることで当該被修正文字列を修正する。
(もっと読む)
レセプト処理装置
【課題】 レセプトの傷病名欄から読み取られた記載傷病名が、傷病名単語辞書部に登録されている傷病名単語と一致しない場合も、確実にコード化可能なレセプト処理装置を提供する。
【解決手段】 文字認識部及び傷病名単語辞書部を備えるレセプト処理装置において、記載傷病名が傷病名単語辞書部に登録されているか否かを判断する登録判断部と、登録されていないと判断されると、該記載傷病名から接続語を検出する接続語検出部と、記載傷病名において、検出された接続語の前後に含まれる第1傷病名及び第2傷病名を抽出する抽出部とを設け、登録判断部は、更に第1傷病名及び第2傷病名の何れか一つが、傷病名単語辞書部に登録されているか否かを判断し、登録されていると判断されると、対応する疾病分類コードを傷病名単語辞書部から読み出すコード読出部と、該疾病分類コードを記載傷病名に付与して、認識結果として出力する出力部とを更に設ける。
(もっと読む)
文字認識方法、文字認識プログラム及び文字認識プログラムを記録したコンピュータ読み取り可能な記録媒体
【課題】枠なしで手書き入力された文字に対するより自由度の高い、筆記方向に依存しない枠なし文字認識(自由筆記文字列認識)を行う。
【解決手段】入力文字列パターン入力部5により枠なしで自由な方向で入力された文字列のパターンが入力される。入力された文字列パターンに含まれる各文字は、文字サイズ推定処理部11により、文字サイズを推定される。つぎに、文字切出し処理部12は、例えば、改行、筆記方向変化点に基づいて文字列の筆記方向の推定を行う。さらに、文字切出し処理部12は、推定された筆記方向に基づいて仮分割及び仮分割修正を行う。つぎに、最尤文字列探索処理部13では、文字切出しの行われた文字列に対して、認識エンジン部14及び最尤文字列探索部15により文字認識を行うと共に、この文字認識の結果を認識結果出力部6に出力する。認識結果出力部6は、この認識結果をアプリケーション3の表示画面上に表示するために出力する。
(もっと読む)
文字認識方法、文字認識プログラム及び文字認識プログラムを記録したコンピュータ読み取り可能な記録媒体
【課題】枠なしで手書き入力された文字に対するより自由度の高い、筆記方向に依存しない枠なし文字認識(自由筆記文字列認識)を行う。
【解決手段】入力文字列パターン入力部5により枠なしで自由な方向で入力された文字列のパターンが入力される。入力された文字列パターンに含まれる各文字は、文字サイズ推定処理部11により、文字サイズを推定される。つぎに、文字切出し処理部12は、例えば、改行、筆記方向変化点に基づいて文字列の筆記方向の推定を行う。さらに、文字切出し処理部12は、推定された筆記方向に基づいて仮分割及び仮分割修正を行う。つぎに、最尤文字列探索処理部13では、文字切出しの行われた文字列に対して、認識エンジン部14及び最尤文字列探索部15により文字認識を行うと共に、この文字認識の結果を認識結果出力部6に出力する。認識結果出力部6は、この認識結果をアプリケーション3の表示画面上に表示するために出力する。
(もっと読む)
文字認識方法、文字認識プログラム及び文字認識プログラムを記録したコンピュータ読み取り可能な記録媒体
【課題】枠なしで手書き入力された文字に対するより自由度の高い、筆記方向に依存しない枠なし文字認識(自由筆記文字列認識)を行う。
【解決手段】入力文字列パターン入力部5により枠なしで自由な方向で入力された文字列のパターンが入力される。入力された文字列パターンに含まれる各文字は、文字サイズ推定処理部11により、文字サイズを推定される。つぎに、文字切出し処理部12は、例えば、改行、筆記方向変化点に基づいて文字列の筆記方向の推定を行う。さらに、文字切出し処理部12は、推定された筆記方向に基づいて仮分割及び仮分割修正を行う。つぎに、最尤文字列探索処理部13では、文字切出しの行われた文字列に対して、認識エンジン部14及び最尤文字列探索部15により文字認識を行うと共に、この文字認識の結果を認識結果出力部6に出力する。認識結果出力部6は、この認識結果をアプリケーション3の表示画面上に表示するために出力する。
(もっと読む)
処方箋受付装置
【課題】薬品名の特殊性に着目して文字列置換テーブルへの設定や追加が容易かつ適切に行えるようにする。
【解決手段】薬品マスターに含まれている数値含有薬品名「ケフラーカプセル250mg」については、非数値部「ケフラーカプセル」と数値「250」と単位部「mg」との順を数値部と単位部と非数値部の順に並べ替えることにより自動で並替薬品名「250mgケフラーカプセル」を生成し、それらを自動で文字列置換テーブルに設定する。また、数値含有薬品名やその並替薬品名から非数値部の後尾の文字を省いた略式薬品名「ケフラーカプセ250mg」,「250mgケフラーカプセ」についても、自動で文字列置換テーブルに設定する。そして、文字認識処理の後処理で、文字列置換テーブルで対応付けに基づき並替薬品名や略式薬品名を薬品マスター規定の適切な薬品名に変換することにより、文字認識率や受付作業能率を向上させる。
(もっと読む)
ショートハンド・オン・キーボード・インタフェースにおいてテキスト入力を改善するためのシステム、コンピュータ・プログラムおよび方法(キーボード上のショートハンド・オン・キーボード・インタフェースにおけるテキスト入力の改良)
【課題】 ショートハンド・オン・キーボード・インタフェースを介して入力されるテキスト入力を改善する。
【解決手段】 単語認識システムは、ショートハンド・オン・キーボード・インタフェースを介して入力されるテキスト入力を改善する。コア辞書は、ある言語において一般的に用いられる単語を含む。拡張辞書は、コア辞書に含まれない単語を含む。このシステムは、コア辞書からの単語のみを直接出力する。拡張辞書からの候補単語は、ユーザによって選択されると出力され、同時にコア辞書に載ることができる。連結モジュールによって、ユーザは、長い単語の部分を別個に入力することができる。複合単語モジュールは、連結によって1つの長い単語を形成する2つの一般的な短い単語を組み合わせる。
(もっと読む)
文字認識装置および文字認識方法
【課題】デジタルビデオレコーダにおいて番組のテロップ認識を行う際の文字認識精度を向上する。
【解決手段】デジタルビデオレコーダ1は、単語がジャンル毎に分類して記憶された知識辞書11と、知識辞書11および外部から取得した情報を用いて単語照合処理に用いる照合用辞書13を作成する照合用辞書作成部12と、テロップ認識部14により認識された認識結果の文字列に対して照合用辞書13を用いて知識処理(単語照合処理)を行うことで認識結果を評価し、知識辞書11更新のための更新用情報17を作成する単語照合処理部15と、更新用情報17を用いて知識辞書11を更新(修正)する知識辞書更新部16とを備える。
(もっと読む)
文書管理装置、文書管理システムおよび文書管理方法
【課題】 電子文書の画像情報のうち、文字に装飾が施されていたり、イメージとして文字画像が画像情報に貼り付けられたりした場合であっても、この部分の文字に対応した文字コード情報を適切に取得する。
【解決手段】 本発明に係る管理サーバでは、イメージ化した画像情報(図6中の中央)を得る。文字認識処理により、図6中の右側に示す11文字の文字コードを得る。アプリケーションソフトF1の場合には、22文字の文字コードが文字コード情報として割り当てられる。そこで、この22文字を11文字の文字コードに置き換えて文字コード情報を作成する。これにより、影付き文字であっても、正確な文字コードが割り当てられる。
(もっと読む)
手書き数式の認識装置及び認識方法
【課題】
確率的なアプローチを採用することで、手書き数式を認識することを目的とする。ストローク認識と構造認識とが密接に関連しているという立場に立脚して、手書き数式を認識する。
【解決手段】
手書き数式を読み込む入力手段と、数式を構成するストローク候補のストローク尤度を算出する手段と、入力された数式を、複数のストローク候補から構成される複数の数式候補で表現する手段と、入力された手書き数式を構成する数式部品間の位置関係に関する構造尤度を、確率文脈自由文法を用いて算出する手段と、算出されたストローク尤度及び構造尤度を用いて各数式候補の尤度を算出する手段と、算出された各数式候補の尤度に基づいて数式を決定する手段と、からなる。
(もっと読む)
機械翻訳装置および機械翻訳プログラム
【課題】原文から翻訳対象の入力原文を取得した際に欠如した文字または誤入力された文字のある単語を、入力原文の取得元の特性を基に訂正することで、他言語への翻訳の際に未知語や非文の発生を低減し、翻訳精度を向上すると共に作業効率を向上する。
【解決手段】翻訳原文推定装置は、Webページより取得した文字列を単語の単位に分割した複数の単語のうち先頭単語の先頭文字が小文字が大文字かを判定し、先頭文字が小文字の場合、先頭単語の先頭に大文字のアルファベットを付加した複数の先頭単語置き換え単語を生成する形態素解析部14と、生成された複数の先頭単語置き換え単語について辞書部10の辞書データを基に選出された辞書部10に存在する先頭単語置き換え候補を原文の先頭単語と置き換えた1つ以上の文について辞書部10の辞書データを基に構文解析を行う構文解析部15と、その中から文法的に正しい原文候補を選出し翻訳部18へ出力する構文解析制御部16とを備える。
(もっと読む)
キー文字抽出プログラム、キー文字抽出装置、キー文字抽出方法、一括地名認識プログラム、一括地名認識装置および一括地名認識方法
【課題】効率よく、高い精度で、信頼性ある住所認識を行うこと。
【解決手段】住所認識装置、住所認識方法および住所認識プログラムである。当該住所認識処理は、文字分離処理と、キー文字抽出処理と、一括地名認識処理と、住所決定処理とを含む。キー文字抽出処理は、複数の単一文字領域からキー文字を抽出する。単一文字領域の各々に対するキー文字抽出処理は、単一文字領域に対応する画像から特徴ベクトルを抽出する特徴ベクトル抽出処理と、特徴ベクトル抽出処理により抽出された特徴ベクトルと、すべてのあり得るキー文字を記憶したキー文字辞書におけるキー文字の特徴ベクトルとを照合し、すべてのあり得るキー文字候補を検索する照合処理と、照合処理により検索された1つ以上のキー文字候補をそれぞれ有する複数の単一文字領域を認識する場合に、正当なキー文字パスを決定するキー文字パス決定処理と、を含む。
(もっと読む)
ラスタ画像表示用ハイブリッドデータ構造生成方法及び装置
【課題】 レーザプリンタやコンピュータモニタ等のラスタディスプレイ装置上に画像を表示する改良した装置及び方法を提供する。
【解決手段】 本発明によれば、データ構造から派生されるラスタ画像を発生するシステム(10)が提供され、該システムは、データ処理装置と、該データ処理装置に対して入力ビットマップに関し認識処理を実行し入力ビットマップ内における識別可能なオブジェクトを検知する認識器と、識別可能なオブジェクト及び識別不可能なオブジェクトに対応するコード化データ及び入力ビットマップを包含するハイブリッドデータ構造を発生するメカニズムと、ハイブリッドデータ構造内の入力ビットマップから派生される視覚的に知覚可能なラスタ画像を発生することの可能な出力装置とを有することを特徴としている。
(もっと読む)
文書読取システム
【課題】 読み取った文書を極めて高精度に解析して正確な文字認識を行う。
【解決手段】 読み取った画像データからなる文書をテキストデータに変換するOCR処理部2と、このOCR処理部2にて変換されたテキストデータに対して、構文意味解析処理を施し、少なくともテキストデータの格構造及び時制情報からなる構文意味解析情報を抽出する文書意味解析処理部3と、構文意味解析情報を参照してテキストデータのエラーを検出し、このエラーを修正する変換処理部4とを備える。
(もっと読む)
文書検索装置及び方法と記憶媒体
【課題】 従来の検索技術では、依然として無関係なヒットが発生してしまう。
【解決手段】 検索クエリと当該検索クエリの展開クエリとを基に、検索対象の文書データを検索して前記検索クエリ及び前記展開クエリに一致する文字列を抽出し(S13)、その抽出された文字列が、未知語領域を含むか否かを判定し、未知語領域を含まないと判定された場合に、抽出された文字列の類似度を低下させるように調整し(S14)、その調整された類似度に応じた順番で文字列を検索結果として出力する(S16)。
(もっと読む)
走査された及びリアルタイムの手書き文字の識別を行う文字認識システム
【課題】手書き文字認識システムを提供する。
【解決手段】低レベル認識プロセッサ(34)が、時間順序誘導プロセッサから接続されており、順序付きのクラスタ・アレーを受け取り、それぞれの順序付きのクラスタ・アレーに対する文字リストを含むシーケンシャルな文字アレーを発生し、それぞれの文字リストには、対応する順序付きのクラスタ・アレーの可能性のある解釈を表す少なくとも1つの文字識別が含まれる。言語的なポスト・プロセッサ(36)が、低レベル認識プロセッサから接続されており、シーケンシャルな文字アレーを受け取り、文書の手書き文字の最も蓋然性のある解釈を表す出力ストリングを発生する。
(もっと読む)
翻訳装置
【課題】 文字認識率の向上を図ると共に、使用者の負荷を軽減することで実用性の高い翻訳装置を実現すること。
【解決手段】 画像処理部30は、撮影部10により測定された被写体までの距離に基づいて、静止画像データにパララックス補正を行う。そして、当該補正後の静止画像データから文字列を抽出し、当該抽出に失敗した場合は、静止画像データに対してエッジ強調や階調補正といった画像処理を施して、再度文字抽出を行う。言語処理部40は、画像処理部30により抽出された文字列を翻訳エンジン60に伝送する。翻訳エンジン60は、翻訳エンジン60から言語処理部40から入力された文字列の訳語を検索して、言語処理部40に返す。言語処理部40は、翻訳エンジン60から返された訳語を表示部70に表示させる。このとき、訳語の光学像がホログラフィック光学素子に投射されて、回折反射により使用者の眼に導かれる。
(もっと読む)
1 - 20 / 30
[ Back to top ]