
Fターム[5B075QT06]の内容
Fターム[5B075QT06]に分類される特許
1 - 20 / 193
情報処理装置及び情報処理方法及びプログラム
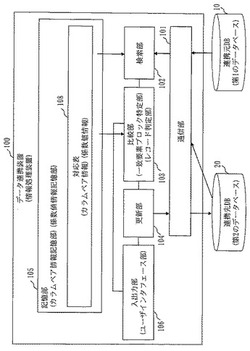
【課題】2つのDBの間でデータ連携を行う場合に、一方のDBにて連携キーに変更があった場合にも、一方のDBのデータを他方のDBに正確に反映させる。
【解決手段】対応表108は、各カラムの類似係数のセットを連携キーの文字列の要素ごとに定義している。検索部102による検索の結果、連携元DB10の連携キーにおいて、連携先DB20の連携キー中の文字列と一部において一致する文字列が抽出された場合に、比較部103は、両文字列において一致する要素に対応する類似係数のセットを対応表108から抽出し、カラムごとに連携元DB10のレコードと連携先DB20のレコードとの一致判定を行い、一致したカラムに対して類似係数を適用して連携元DB10のレコードと連携先DB20のレコードとの類似度を判定し、類似度に基づき、連携元DB10の内容を連携先DB20に正確に反映させる。
(もっと読む)
データ検索装置、方法、及びプログラム

【課題】計算資源が十分に使用できない省資源機器でのデータベース検索において、データ分布の事前解析処理やデータベースファイルの再構築処理が困難な省資源機器においても応答性能を向上させ、検索機能の利便性を高める。
【解決手段】前段の検索で作られたキャッシュが後段の検索で再利用されるようにキャッシュに保持するデータを選定し、検索処理を実行する。検索条件の履歴を解析し、キャッシュのヒット率が高くなるインデックスを選択して保持する。
(もっと読む)
リレーショナルデータベースを使用した世代管理におけるストレージ容量削減方法
【課題】リレーショナルデータベースにおいて世代管理を行う際に、ストレージ容量を削減することができる、リレーショナルデータベースを使用した世代管理におけるストレージ容量削減方法を提供する。
【解決手段】システム304は、ユーザデータが格納される表308に対する削除及び/又は追加処理を行うステップと、データベースに副次インデックス309が存在しない場合は、正インデックス307を更新するステップと、副次インデックス309が存在し、更新した表308の表内位置情報と同じエントリが存在し、エントリの操作種別が追加(UPDATE)であれば、更新前行データを退避しておき、エントリを削除するステップと、同じエントリが存在しなかった場合は、副次インデックス309にエントリを追加し、エントリの操作種別が追加(UPDATE)であれば、退避した更新前行データ又は表の更新前行データを設定するステップとを実行する。
(もっと読む)
分散データベース管理システム、分散データベース管理方法
【課題】分散データベースシステムにおけるデータ検索処理を迅速化する。
【解決手段】表データの分配先を示すスキーマ情報をバックエンドサーバ22,23,24それぞれに対して転送し、各バックエンドサーバ22,23,24に格納された結合キー列に含まれていない項目データがある場合に、この項目データを複製データとして対応するバックエンドサーバに対して補完的に格納するフロントサーバ21を有し、各バックエンドサーバ22,23,24は、検索要求が送り込まれた場合に、バックエンドサーバ内に分散格納されたカラムデータ相互の結合を行うことにより結合キー列から前記検索内容で必要とされる検索用列データを抽出し、この検索列データに対応する結合用データが分配された他のサーバに検索列データを送信して結合を行うことにより中間検索結果を生成する。
(もっと読む)
プログラム開発支援システム及びデータ利用システム
【課題】正規化を極めたテーブルを操作するアプリケーションプログラムの、開発負担を軽減する。
【解決手段】キー項目が一つに限定される制約、Null値、フラグ値及び区分値を格納するためのデータ項目の設定が禁止される制約、データの更新が禁止される制約が設けられたテーブルを複数備えたDBサーバ16に対し、各テーブルに格納されたデータを操作するSQLを発行すると共に、取得したデータを加工するプログラムの開発支援システム60であって、テーブルの設定情報に基づいて、テーブル名、データ項目及び各データ項目のデータ型を定義したクラスを生成し、型格納部66に格納する型生成部64と、クラスを指定したコードが記述されたソースプログラムが入力された際に、型格納部66内のクラスを参照して矛盾の存否を判定し、矛盾がある場合にはエラーメッセージを出力するコンパイラ68を備えた。
(もっと読む)
分散メモリデータベースシステム、フロントデータベースサーバ、データ処理方法およびプログラム
【課題】通信量および処理量を削減して、合計などの集合関数に対する処理を高速に行うことを可能とする分散メモリデータベースシステム等を提供する。
【解決手段】フロントデータベースサーバ10が、外部から入力される表データを分割して複数の値ID表を生成してこれらを各データノードに分散して記憶させるデータ構造変換部113と、外部のクライアントマシンから発行された集合関数を含むクエリーに基づいて各データノードに表データの中の特定の値IDの出現数を問い合わせると共に、これに応じて各データノードから返された特定の値IDの出現数からクエリーに対応する集合関数の値を計算してクライアントマシンに返送する問い合わせ処理部111とを有し、データ構造変換部が、表データの中で集計軸になり得る列としてあらかじめ指定された複数のデータ項目の各々について個別に複数の値ID表を生成する。
(もっと読む)
分散データベース管理装置および分散データベース管理プログラム
【課題】DBサーバ間でテーブルのデータの送信処理を行わずに、複数のテーブルの結合処理を実行することができる、分散データベース管理装置および分散データベース管理プログラムを提供する。
【解決手段】分散データベース管理装置10は、各DBサーバ20に格納されたデータを取得し、データベースのテーブルごとに、そのテーブルの主キーでレコードをソートし分割した主キー分割テーブルと、テーブルごとの主キーおよび外部キーのスキーマを抽出し、その抽出したスキーマのレコードを、外部キーでソートし分割した結合用テーブルを生成する。そして、分散データベース管理装置10は、受け付けた検索要求の実行プランにおいて、テーブル結合条件の外部キーの結合対象となるテーブルを、結合用テーブルに書き換えて、検索処理を実行する。
(もっと読む)
データベース処理方法、データベース処理システム及びデータベースサーバ
【課題】ソートされたデータの抽出を高速化する。
【解決手段】データを格納するデータベースを管理するデータベース管理システムが実行される計算機において、要求されたデータを出力するデータベース処理方法であって、抽出されたデータを指定した順序で出力する問合せ要求を受け付けるステップと、問合せ要求に基づいて、データを抽出する問合せ実行プランを生成するステップと、問合せ実行プランに基づいて要求されたデータを取得するステップと、取得されたデータを含む中間結果を生成するステップと、生成された中間結果を指定された順序に並び替えるステップと、並び替えられた中間結果の順序が確定したか否かを中間結果ごとに判定するステップと、順序が確定した中間結果を問合せ結果として出力するステップとを含む。
(もっと読む)
データ処理装置及びデータ処理方法及びプログラム
【課題】2つの2次元データの間で対応関係にあるカラムを抽出する作業の効率を向上させる。
【解決手段】区切り分割部11が移行元データにおいて解析対象となるカラム対を選択し、相関ルール計算部12が移行先データにおいて解析の対象となるカラム対を選択し、移行元データのカラム対において行ごとに支持度及び確信度を計算し、移行先データの各カラム対について、行ごとに支持度及び確信度を計算する。相関差分値計算部13が、移行元データ内で行間の支持度及び確信度の差分計算を行い、移行先データ内で、カラム対ごとに、行間の支持度及び確信度の差分計算を行い、比較計算部14が、移行元データでの差分値と移行先データでの差分値との差分計算を行い、判定部15が、差分計算の結果に基づき、移行元のカラム対に対応する移行先のカラム対を判定する。
(もっと読む)
検索装置、検索プログラム、および検索方法
【課題】情報検索において、ユーザにとって参考となり得る情報を提供すること。
【解決手段】検索装置100は、第1の検索条件を受け付ける。つぎに、検索装置100は、受け付けた第1の検索条件で指定された対象と同一の属性を有する他の対象を指定する第2の検索条件を作成する。このあと、検索装置100は、作成された第2の検索条件に基づいて、検索対象となるデータ群の中からデータを検索する。また、検索装置100は、受け付けた第1の検索条件に基づいて、検索対象となるデータ群の中からデータを検索する。そして、検索装置100は、検索された検索結果を出力する。
(もっと読む)
情報検索装置、情報検索方法及びプログラム
【課題】データファイルによって情報の保持の仕方が異なる場合であっても、何れのデータファイルでも同じように情報検索を行える情報検索装置、情報検索方法及びプログラムを提供する。
【解決手段】経歴ファイル51と、経歴ファイル51に従属する兼務履歴ファイルを記憶する大容量記憶装置5から、仮想DBを作成し、その仮想DBにおいて日付が同じレコードを1レコードに纏めた検索用データテーブルを作成し、検索用データテーブルから、入力された検索条件に対応するデータを検索する。
(もっと読む)
スキーマ定義生成装置、スキーマ定義生成方法およびスキーマ定義生成プログラム
【課題】スキーマ定義を自動で生成することで、スキーマ定義作成作業の工数を削減し、スキーマ定義を迅速に作成することを課題とする。
【解決手段】スキーマ生成装置1の要素比較作成部2は、管理対象である構成要素を示す構成要素情報を検索するための検索式に含まれる構成要素情報と、リレーショナルデータベース5への問い合わせ履歴情報に含まれるテーブル情報とを比較し、構成要素情報とテーブル情報との対応関係を示す対応関係情報を作成する。関係比較作成部3は、検索式に含まれる構成要素間の関係を示す関係情報と、問い合わせ履歴情報に含まれるとテーブル間の関係を示す情報とを比較し、関係情報と問い合わせ履歴情報との対応関係を示す対応関係情報を作成する。スキーマ生成部4は、要素比較作成部2によって作成された対応関係情報と、関係比較作成部3によって作成された対応関係情報とを用いて、スキーマ定義を作成する。
(もっと読む)
和集合集約処理と等結合処理の組み合わせ方法及びデータベースシステム及びプログラム
【課題】 和集合集約処理と等結合処理を組み合わせて実行するための和集合集約処理と等結合処理の組み合わせ処理において、和集合対象データベースシステムのレコードの結合結果テーブルのどの場所に格納すべきかをソートしなくても決定することを可能にする。
【解決手段】 本発明は、和集合集約処理(X∪Y)と等結合処理(A∩Z)を組み合わせた処理((X∪Y)∩Z)を扱う場合に、(X∩Z)及び(Y∩Z)それぞれでヒットするか否かをZ表基準のフラグで集約する。フラグの和集合(OR)を計算し、Z表基準で順番を付与し、その順番に基づいてデータを集めることで、結合結果テーブルへの格納時にソートを不要にすることが可能となる。
(もっと読む)
同義カラム検出装置及び同義カラム検出方法
【課題】同じような属性をもつ複数のカラムの各々について、同義カラムであるか否かを判定する。
【解決手段】同義カラム検出装置100の同義カラム判定部199は、第1のデータベースの第1カラム群に含まれる各カラムの属性と第2のデータベースの第2カラム群に含まれる各カラムの属性との比較結果に基づき、第1カラム群と第2カラム群との各々から同義カラムの候補を抽出する。第1カラム群から抽出した同義カラムの候補である第1候補と第2カラム群から抽出した同義カラムの候補である第2候補とがそれぞれ2つ以上ある場合、同義カラム判定部199は、第1のデータベースに対するクエリの発行履歴と第2のデータベースに対するクエリの発行履歴との分析結果に基づき、第1候補と第2候補との各々から同義カラムに該当するカラムを判定する。
(もっと読む)
分散メモリデータベースシステム、データベースサーバ、データ処理方法およびそのプログラム
【課題】複数のサーバにまたがる処理を高速化することを可能とする分散メモリデータベースシステム等を提供する。
【解決手段】フロントメモリデータベースサーバ10が、インデックステーブル、フロントインデックス列、およびスキーマ情報を保存する記憶手段102と、クエリを実行して中間データを作成するクエリ実行部111と、スキーマ情報に基づいて実データが記憶されているバックエンドデータベースサーバを特定する表情報管理部112と、実データを照会して取得する実データ照会部113を備え、バックエンドデータベースサーバ21が、インデックス番号に対応する実データを保存する記憶手段202と、インデックス番号に対応する実データを返信するカラムデータ管理部211とを備え、クエリ実行部111が、中間データ中のインデックス番号を取得された実データに置換して出力する。
(もっと読む)
データベース管理方法、データベースシステム、プログラム及びデータベースのデータ構造
【課題】データの読取処理の高速性を維持しつつ、データの追加処理によるパフォーマンスの低下を防ぐ。
【解決手段】データベースは、カラム毎に各シンボル値の順列をデータ識別値により示す順列行列部A1と、データサブセットから構成される一又は複数のカラムデータ部B1と、を備える。各カラムデータ部B1における各データサブセットは、当該データサブセットに含まれる各シンボル値と、各シンボル値のデータ識別値と、当該データサブセットの識別値と、当該データサブセットにおける各前記シンボル値がソート状態か否かを示すフラグと、を含む。データを追記する場合には、追記対象データについて、順列行列部A1とカラムデータ部B1のデータフォーマットに従った各データを生成してデータベースに追記する。
(もっと読む)
データベース変換システム
【課題】汎用機上のアプリケーションのロジックを残しつつ、階層型データベースにアクセスするアプリケーションをリレーショナルデータベースにアクセスするアプリケーションに変換する。
【解決手段】本発明に係るクエリ変換プログラムは、階層型データベースの構造定義データと、COBOLプログラムが階層型データベースにアクセスするときのアクセスパラメータに基づき、階層型データベースを変換したリレーショナルデータベースにアクセスするためのクエリを特定する。また、あらかじめ用意されている、前記リレーショナルデータベースにアクセスするSQL部品のうち、前記クエリに相当するものを選択し、前記アクセスパラメータを引き渡してクエリを実行する。
(もっと読む)
情報管理プログラム、情報管理装置及び情報管理方法
【課題】出力命令に係る文書に関連する文書を適切に出力すること。
【解決手段】情報管理装置は、予め定義された処理命令文又は処理命令文を定義する定義情報から、第一の情報を管理する第一の記憶部と第二の情報を管理する第二の記憶部とを結合する結合情報を抽出する。また、情報管理装置は、抽出された前記結合情報に基づいて、第二の記憶部において第二の情報を一意に識別する主項目が、第一の記憶部に設定された複数の項目のいずれかに含まれるか否かを判定する。また、情報管理装置は、第一の情報に対する出力命令を受け付けた場合に、出力命令に係る第一の情報を出力すると共に、複数の項目に前記主項目が含まれると判定された第二の情報を第一の情報に関連する情報として共に出力する。
(もっと読む)
パフォーマンス分析システム及びパフォーマンス分析プログラム
【課題】SQL文のパフォーマンスの分析を行うこと。
【解決手段】実体テーブル部11に格納したデータの登録数とデータに予め設定されたデータ種数を示す分散数とを入力する分析条件入力部21と、SQL文に含まれる検索条件の項目と項目に対応した分散数とを取得し、前記取得した項目に対して前記入力したデータ登録数を設定した疑似SQL文を生成する疑似テーブル定義作成部22と、前記生成した疑似SQL文を参照し、疑似SQL文に含まれる項目に対応した疑似データを前記入力した分散数だけ生成して疑似テーブル部12に登録する疑似テーブルデータ登録部23と、前記生成した疑似SQL文を用いて疑似テーブル部12に登録した疑似データを検索し、検索結果が予め設定したしきい値を超えると判定したとき、前記しきい値を超えたSQL文を出力するSQL文アクセスプラン分析部25とを備えるパフォーマンス分析システム。
(もっと読む)
データ整理のための方法及びシステム
【課題】データベースシステムでデータを整理するためのシステム及び方法を提供する。
【解決手段】生データは数値の要素を持つベクトルとして表される。一旦生データが数値的に表されれば、特有のベクトルが「純化された」若しくは参照のデータベースにおける他のベクトルとどのように内容が一致するのかを決定するために、相関性機能、パターン認識方法、又は他の類似した数値的方法のような数学的処理が実行されることができる。
(もっと読む)
1 - 20 / 193
[ Back to top ]