
Fターム[5B091AA15]の内容
Fターム[5B091AA15]に分類される特許
81 - 100 / 617
関係情報抽出装置、その方法及びプログラム
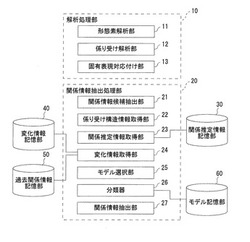
【課題】複数の固有表現間の関係情報を高精度で抽出可能な装置、方法及びプログラムを提供する。
【解決手段】入力された複数の固有表現に関係する情報を抽出する装置であって、前記各固有表現を含むテキストが入力されると、入力テキストを形態素解析するとともに入力テキストを構成する文節の係り受けを解析する解析処理部10と、解析処理部による解析結果を取得すると、入力テキストに含まれる少なくとも一つの自立語を関係情報候補として抽出するとともに、該各固有表現の関係情報として過去に用いられた過去関係情報が該関係情報候補に経時変化したと推定される度合を表す変化情報を、抽出された関係情報候補毎に取得し、解析結果及び変化情報に基づいて関係情報候補から関係情報を抽出する関係情報抽出処理部20とを備えた。
(もっと読む)
解析モデル学習装置、解析モデル学習方法及び解析モデル学習プログラム

【課題】解析モデルの自動学習における処理速度の向上を図ること。
【解決手段】解析モデル学習装置1は、一度に読み込む訓練データ中の記事数を1記事または少数記事とし、それ以前に読み込まれた記事も含めて解析を行い解析結果の初期値を与えるベースライン解析部2と、訓練用データに対する解析結果を保持する解析結果テーブル3と、解析誤りデータからルールテンプレート5に基づいてルール候補を作成するルール候補作成部4と、それを保持するルール候補テーブル7と、ルール候補の中で最も正味の正解の増加数が大きくなるルールを選択するルール選択部6と、選択されたルールを保持する解析モデルテーブル9と、保持されたルールを、前記テーブル3に保持された訓練データに対する解析結果に適用し解析結果を変換するルール適用部8と、解析モデルテーブル9に保持されたルールを解析モデルとして外部に出力する出力部10とを備える。
(もっと読む)
文字列ベクトル変換装置、文字列ベクトル変換方法、プログラム、及びプログラムを格納したコンピュータ読み取り可能な記録媒体
【課題】意味表現として適切な文字列ベクトルを生成することを課題とする。
【解決手段】文字列ベクトルデータベース1と、テキストとを入力とし、前記文字列ベクトルデータベース1の複製である文字列ベクトルデータベース2を生成した後、前記テキスト中の、連続する有限個の単語の列である所定の範囲に存在する、前記文字列ベクトルデータベース1中の文字列A、Bの任意の対に対し、当該文字列Aの前記文字列ベクトルデータベース2中のベクトルに、前記文字列Bの前記文字列ベクトルデータベース1中のベクトルv(B)をスカラー倍したものを加算し、前記文字列Bの前記文字列ベクトルデータベース2中のベクトルに、前記文字列Aの前記文字列ベクトルデータベース1中のベクトルv(A)をスカラー倍したものを加算することを、前記テキスト中の全ての前記所定の範囲にわたって繰り返し、その結果得られた文字列ベクトルデータベース2を出力する。
(もっと読む)
対話装置、対話方法、およびプログラム
【課題】ユーザの意思決定を支援できる対話装置がなかった。
【解決手段】スポットと1以上の決定要因と各決定要因の評価値とを有するスポット情報を2以上格納している知識ベースと、出力する文の文パターン情報と評価情報とを有する2以上の情報推薦手法を格納しており、決定要因に対するユーザの嗜好ベクトルと決定要因に対するユーザの知識ベクトルとを有するユーザ状態情報を格納しており、ユーザから文を受け付ける受付部と、ユーザ状態情報を2以上の各情報推薦手法の評価情報に適用し2以上のスコアを算出するスコア算出部と、スコアが最大の一の情報推薦手法が有する文パターン情報から文を構成する文構成部と、文を出力する文出力部と、受け付けた文や出力文から1以上の決定要因を取得し、ユーザ状態情報を更新するユーザ状態情報更新部とを具備する対話装置により、ユーザの意思決定を支援できる。
(もっと読む)
自動単語対応付け装置とその方法とプログラム
【課題】トピックを導入した同義語辞書モデルを構築させ、その同義語辞書モデルと従来の単語対応付けモデルとを同時に用いた自動単語対応付け装置を提供する。
【解決手段】この発明の自動単語対応付け装置は、訓練データ記憶部と、アライメント確率学習部と、自動対応付け部と、を具備する。訓練データ記憶部は、単語で区切られた原言語と目的言語の対訳文の組みで構成される対訳文コーパスと、上記目的言語の同義語の組の集合である同義語辞書とから成る。アライメント確率学習部は、トピック毎に、対訳文コーパスの対数尤度と同義語辞書の対数尤度との重み付き和を最大にするパラメータを学習する。自動対応付け部は、対象翻訳文とそのパラメータを入力として対象翻訳文の原言語と目的言語の単語間のアライメントを生成する。
(もっと読む)
代表語抽出装置、代表語抽出方法および代表語抽出プログラム
【課題】文書群に含まれる文書の数に依存することなく文書群を代表する単語を抽出すること。
【解決手段】前処理部11は、代表語の抽出対象となる対象文書群を含む文書群を収集し、基準語取得部13は、代表語を抽出する基準となる基準語を取得する。そして、基準文書特定部14は、前処理部11から入力される文書群から基準語を含む基準文書を特定し、単語群抽出部15は、基準文書から基準語と基準語以外の単語とを単語群として抽出する。そして、指標算出部16は、抽出された単語群の各単語に対して、基準語との共起回数の大小に応じて値が増減する指標を算出する。そして、指標補正部17は、抽出された単語群の各単語に対して、全文書群における希少度と対象文書群における希少度とを算出し、算出した2つの希少度を用いて指標算出部16によって算出された指標を補正する。
(もっと読む)
医療用語の曖昧性を判定するシステム、方法およびソフトウェア
【課題】文書の医療的文脈を判別し、前記医療的文脈に基づき文書を別の文書にリンクさせるシステム、方法およびソフトウェアを提供すること。
【解決手段】いくつかの医療用語は、特定の文脈により、非医療用語として用いられることもある。従って、本発明者は、医療情報データベースに記載されている用語が別の情報データベースでも医療用語として使用されているかを判定するシステム、方法およびソフトウェアを発明した。典型的実施例では、用語を受け取ってから医療および非医療情報データベースの言語モデルを基に曖昧性スコアをコンピュータで計算する。上記方法は、用語を受け取るステップと、第一および第二言語モデルに基づく前記用語の曖昧性スコアを判定するステップと、前記曖昧性スコアを出力するステップとを含む。
(もっと読む)
言語解析プログラム
【課題】 外部情報や頻度を用いずに、未知語を正確に抽出する。
【解決手段】 適切性判定部14は、記憶部11内の形態素解析結果に未知語タグが含まれる場合、未知語タグが付与された単語を文節拡張部15に送出する。文節拡張部15は、送出された単語に区切り文字が含まれるか否かに応じて、右側及び左側の拡張文節、又は拡張文節を記憶部11に書き込む。形態素解析部13は、記憶部11内の拡張文節を形態素解析し、形態素解析結果を記憶部11に書き込む。適切性判定部14は、拡張文節の形態素解析結果に未知語タグが含まれる場合、拡張文節の形態素解析結果と、前回の形態素解析結果のうちの未知語タグが付与された単語とが一致するか否かを判定する。一致する場合、解析結果出力部16は、前回の形態素解析結果を出力する。
(もっと読む)
不具合を示す述語表現を抽出するための不具合述語表現抽出装置、不具合述語表現抽出方法及び不具合述語表現抽出プログラム
【課題】不具合を示す述語表現を自動で抽出することのできる技術を提供する。
【解決手段】不具合述語表現抽出装置100は、突然性を示す連用修飾表現または再現性を示す連用修飾語のいずれか一方の近傍に現れる述語表現を、不具合を示す述語表現の候補として抽出し、また、常性を示す連用修飾表現の近傍に現れる述語表現を、正常を示す述語表現として抽出し、不具合を示す述語表現の候補のリストから、正常を示す述語表現を取り除いて、不具合を示す述語表現を抽出する。
(もっと読む)
テキストコーパスにおける2つのエンティティ間の関係抽出方法及び装置
【課題】テキストコーパスから2つのエンティティ間の関係抽出を行う。
【解決手段】
複数のエンティティペア、複数の語彙パターンのいずれか一方を行、他方を列として、各エンティティペアと各語彙パターンとを関連付ける頻度を要素とする第1共起行列を作成するステップと、第1共起行列において、前記複数のエンティティペア、前記複数の語彙パターンをそれぞれ頻度が大きい順にソートして第2共起行列を作成するステップと、第2共起行列において、複数のエンティティペア、複数の語彙パターンをクラスタリングして、エンティティペアのクラスタ、語彙パターンのクラスタを取得し、取得したエンティティペアのクラスタ、語彙パターンのクラスタのいずれか一方を行、他方を列とし、クラスタリングにより加算された頻度を要素とする第3共起行列を作成するクラスタリングステップと、を備える。
(もっと読む)
多言語文法解析装置、多言語文法解析方法および多言語文法解析プログラム
【課題】複数の言語で記述された文集合から個別言語の文法と共に言語共通の文法を推定する技術を提供すること。
【解決手段】多言語文法解析装置1は、個別文法パラメータ集合46と、共通文法パラメータ集合45と、入力多言語データ44とを記憶する記憶手段4と、言語毎に、記憶されている情報に基づいて、構文木確率を推定する処理と、記憶されている情報および推定された構文木確率に基づいて、個別文法のパラメータを推定して更新する処理とを交互に実行することで、各言語の文法を推定する個別文法推定部21と、更新された各言語の個別文法のパラメータと、記憶されている共通文法パラメータとに基づいて、新たな共通文法パラメータを推定して更新する共通文法推定部22と、各言語の文法を推定する処理と、言語共通の文法を推定する処理とを終了条件が満たされるまで交互に繰り返し実行させる推定処理制御部23とを備える。
(もっと読む)
対話システム、対話フローの更新方法およびプログラム
【課題】実際のユーザの発話に適した分類カテゴリの設定が比較的容易に行えるようなメンテナンス性の高い対話システム、対話フローの更新方法およびプログラムを提供する。
【解決手段】音声対話システム10は、入力された入力データを複数のカテゴリのいずれかに分類する発話意図分類部12と、分類されたカテゴリを起点とする状態遷移を、ユーザとの対話形式で進行して最終状態に導く対話管理部13と、入力データと、進行された状態遷移と、を対にした対話対を登録する対話状態遷移情報記憶部14と、登録された複数の対話対から新たなカテゴリの候補である新規カテゴリを抽出する新規カテゴリ抽出部15と、を備える。発話意図分類部12は、抽出された新規カテゴリを、分類可能なカテゴリに追加する。
(もっと読む)
類推方法、類推システム及び類推プログラム
【課題】構造写像理論に基づく類推方式によって精度良くある程度正しい解を得る。
【解決手段】類推システムは、類推に用いられる知識情報が蓄積されたコーパス10と、写像対象となるベース1,2との関係Rを抽出する関係抽出モジュール20と、抽出された関係Rをターゲットに写像する関係写像モジュール30とを備える。そして、コーパス10からベース1,2が同時に出現する文を抽出し、抽出された文から関係Rを表す単語riを抽出する。また、ターゲットに関係Rを写像して、ターゲットと単語riとが同時に出現する文をコーパス10から抽出し、抽出された文から関係Rに基づく解Xの候補となる単語xjを抽出することを、全ての単語riについて行う。そして、算出された所属度gradeX(xj)の値が高い所定数の単語xjを解Xに含まれるターゲットに関係する候補語として抽出する。
(もっと読む)
情報管理システム、サーバ装置およびプログラム
【課題】複数の相手から同一の文章情報が与えられた場合においても、画一的にならない文章情報を作成できるようにする。
【解決手段】サーバ装置20の制御部21は、ホスト利用者とゲスト利用者のアクセス数を算出する。次に、制御部21は、ホスト利用者とゲスト利用者の親密度を特定する。次に、制御部21は、ホスト利用者の投稿した日記情報を解析して話題を特定する。次に、制御部21は、ホスト利用者の投稿した日記情報に応じた嗜好度を特定する。この嗜好度とは、コメント投稿者が日記投稿者の投稿した日記情報に対して示す興味の程度を示すものであり、日記情報が属する話題と、コメント投稿者と日記投稿者の親密度とで一意に決まるものである。次に、制御部21は、嗜好度に応じた字句の表現を特定する。以上により、サーバ装置20の制御部21は、特定した嗜好度に応じて語句の表現を異ならせた応答情報を投稿することが可能となる。
(もっと読む)
属性抽出装置および方法
【課題】 非構造化テキストから新規属性を抽出するための装置および方法であって、属性相関知識に基づいて、シード属性と同じ出現パターンを有さない新規属性を抽出することのできる装置および方法を提供する。
【解決手段】 この属性抽出装置は、入力された1つのインスタンスと少なくとも1つのシード属性とから、属性相関知識データベースに基づいて1つ以上の構文に合致するクエリを作成するクエリ作成ユニットと、当該クエリを使用して非構造化テキストデータベース内の非構造化テキストを検索するテキスト検索ユニットと、検索されたテキストに対して上記の構文に従ってテキスト照合を実行することにより、当該インスタンスの他の属性を抽出するテキスト照合ユニットとを備える。
(もっと読む)
文の配列に基づく文書感情分類システムおよび方法
【課題】 文書を文の配列として解釈し、かつ文ベースの感情配列を考慮する配列解析を使用して、文書の感情極性を判定するための方法およびシステムを提案する。
【解決手段】 本発明の文書感情分類システムは、入力された文書から特徴語を抽出するための特徴語抽出手段と、特徴語抽出手段によって抽出された特徴語の感情極性と感情強度の少なくとも1つに基づいて、入力された文書に含まれる個々の文の感情極性と感情強度の少なくとも1つを判定するための文感情判定手段と、文感情判定手段によって判定された個々の文の感情極性と感情強度の少なくとも1つに基づいて、文の感情極性の配列を有する文書入力を形成するための文書入力形成手段と、トレーニング済み文書感情判定モデルを使用して、文書入力形成手段によって形成された文書入力を処理することにより、入力された文書の感情極性を判定するための文書感情判定手段とを備える。本発明によれば、文書感情分類の精度を向上させることができる。
(もっと読む)
文書コレクション上にトピックレベルのプライバシ保護を実装する方法およびシステム
【課題】 文書コレクション上にトピックレベルのプライバシ保護を実装するための方法およびシステムを提案する。
【解決手段】 この方法は、文書コレクションと、プライバシ保護を必要とする1つ以上のトピック語を含むトピックレベルのプライバシポリシーとを入力するステップと、トピック語を拡張して1つ以上の秘密語を生成するステップと、生成された秘密語に基づいて文書コレクションから秘密文書を識別するステップとを含む。トレーニング文書を使わなくてもシステムの効率性、柔軟性、実用性を実現できるので、本発明のシステムは大量なプライバシポリシーを同時に処理できるほか、プライバシポリシーの動的な変更をサポートするため利便性にも優れる。
(もっと読む)
自然言語解析装置、方法及びプログラム
【課題】解析対象の文を文末まで形態素解析しなくても、文字ごとの係り受け関係を決定することが可能な自然言語解析装置、方法及びプログラムを提供すること。
【解決手段】自然言語解析装置10は、解析対象の文を構成する文字を文字単位で取得し、取得した文字ごとの依存関係を決定する。そして、自然言語解析装置10は、当該解析対象の文の先頭文字から順にこの文字ごとの依存関係を決定する過程で、係り先が未確定の文字を依存先未決スタック107にスタックしていき、依存関係の判定により文字の係り先が決定した後に、依存先未決スタック107に蓄積された文字の依存関係の決定を行って文字の係り受けを決定する。
(もっと読む)
固有表現抽出装置、文字列−固有表現クラス対データベース作成装置、固有表現抽出方法、文字列−固有表現クラス対データベース作成方法、プログラム
【課題】固有表現を正しくかつ詳細に分類することを可能とする固有表現抽出装置、固有表現抽出方法、固有表現抽出プログラムを提供する。
【解決手段】テキストを入力とし、形態素と係り受け解析結果と固有表現を出力するテキスト解析部1100と、形態素と固有表現を入力とし、トピックを抽出するトピック抽出部1210と、係り受け解析結果を入力とし、文構造を出力する文構造抽出部1220と、固有表現クラスを判定して出力するクラス判定部1230と、シソーラス1240と、文字列−固有表現クラス対データベース1250と、トピックと文構造と固有表現クラスを入力とし、ラベルスコアを出力とするラベルスコア計算部1300と、ラベルごとのラベルスコア計算に用いられるラベル判定モデル1310と、ラベルスコア最大値からラベルを判定するラベル判定部1400と、前記判定されたラベルと固有表現の組を出力する出力部1500とを備える。
(もっと読む)
スパムブログ判定装置及び方法
【課題】管理者による作業を容易にしてスパムブログを判定するスパムブログ判定装置及び方法を提供する。
【解決手段】スパムブログ判定装置1は、登録指定を受け付けた所定キーワードを所定キーワードDB21に記憶する所定キーワード記憶制御手段12と、判定対象のブログ記事を受け付けたことに応じて、所定キーワードDB21に記憶した所定キーワードを素性として用いてブログ記事がスパムブログであるか否かを機械学習により判定する機械学習手段14と、機械学習手段14による判定対象のブログ記事のうち、所定キーワードDB21に記憶された所定キーワードを含むブログ記事と、スパムブログであるか否かの機械学習による判定結果とを対応付けて出力するスパム判定結果出力手段15と、所定キーワードの削除指定を受け付けたことに応じて、所定キーワードDB21に記憶された所定キーワードを削除する調整戻し手段17とを備える。
(もっと読む)
81 - 100 / 617
[ Back to top ]