
Fターム[5B091AA15]の内容
Fターム[5B091AA15]に分類される特許
41 - 60 / 617
文生成装置及びプログラム
【課題】文生成に用いるテンプレートの再利用性を向上させ、条件や参照先の値に応じてきめ細かな文を生成することができる文生成装置及びプログラムを提供する。
【解決手段】本発明の文生成装置は、概念や概念間の関係を示すドメイン知識を体系的に表現したオントロジーと、概念及び概念間の関係に関連付けられたものであって、少なくとも、生成する文の変数とする参照先情報の参照先と所定の文字列とを含む1又は複数の可変部を有する文テンプレートとを格納するオントロジー格納手段と、文を生成する際、オントロジー格納手段から生成する文に関する概念に関連する文テンプレートを選択する文テンプレート選択手段と、選択された文テンプレートの各可変部に含まれている参照先に基づいて取得した参照先情報を展開し、参照先情報の直前及び又は直後に文字列を合成して出力文を生成する文生成手段を備える。
(もっと読む)
質問応答システム

【課題】利用者による質問の焦点を精度良く推定し、回答すること。
【解決手段】質問応答システム10は、利用者が質問を入力する音声入力部11と、入力された質問の構文を解析する音声認識部12と、解析結果に基づき入力された質問の種類を判定する質問タイプ同定部15と、質問タイプ同定部15により入力された質問の種類がYes又はNoで回答できる種類であると判定された場合に、入力された質問の焦点を決定する焦点解析部16と、焦点解析部16により決定された焦点に応じて、適切な回答文を生成する回答文生成部17と、あらかじめ焦点となる文節の位置が設定された解析済み文を記憶する文例データベース18と、を備える。焦点解析部16は、入力された質問文と前記解析済み文との、それぞれの最終文節の働きの比較と、当該最終文節に係る文節の機能語の比較と、当該機能語の出現順とに基づいて、入力された質問の焦点を決定する。
(もっと読む)
テキストを生成する方法及びシステム
【課題】本発明は、全体としてテキストを生成する方法及びシステムに関し、特に、レポート用の構文法的に正しいテキストを生成する方法及びシステムに関する(ただし、これに限定されない)。
【解決手段】データを解釈するエキスパートシステムの能力は、人間の専門家を制限するのと同じ要因、すなわちデータ複雑性によって制限される。したがって、従来のエキスパートシステムは、ますます大量化する複雑なデータを解釈し、そのようなデータを知識に変換する際に制限を受ける。本発明は、複雑なデータを解釈し、そのようなデータをテキストレポート内で表現される知識に変換する手段を提供する。
(もっと読む)
言語モデル学習装置及びコンピュータプログラム
【課題】対象となる分野またはアプリケーションで発せられる可能性のある自然言語文を効率よく生成できる自然言語文生成装置を提供する。
【解決手段】自然言語文生成装置30は、単語列テンプレートを記憶する拡張テンプレート集合記憶部56と、拡張テンプレート集合記憶部56に記憶された単語列テンプレートに合致する単語列パターンをWebコーパス32から抽出するフィルタ60と、予め選択された目的に沿った形式の自然言語の単語列が生成されるように準備された変形規則を記憶する変形規則記憶部64と、変形規則記憶部64に記憶された変形規則に基づいて、フィルタ60により抽出された単語列を変形する変形モジュール66とを含む。
(もっと読む)
単語の文書関連度スコアおよびグラフ構造に基づく文書のキーワード抽出方法および装置
【課題】単語の文書関連度スコアおよび関連する単語間の伝達スコアに基づいて文書のキーワードを抽出する方法および装置が提供される。
【解決手段】本発明の文書のキーワード抽出方法によれば、文書は形態素解析され、解析された結果を用いて単語グラフが生成される。単語の文書関連度スコアは、生成された単語グラフと併合されて単語の重要度を示すキーワードスコアが算出される。算出されたキーワードスコアに応じて単語のうち文書のキーワードが選択される。
(もっと読む)
情報処理装置、方法及びプログラム
【課題】与えられた文脈からは類型が不明な名詞の類型を判定する。
【解決手段】検索エンジンの検索結果における名詞に関する文脈に基づくことにより、与えられた文脈からは類型が不明な名詞についても名詞の類型が判定できるので、判定した類型を、例えば関連検索における関連検索ワードの提示や、ウェブ検索結果のリスト順の制御に反映するなど、ユーザの意図に基づく情報処理結果の最適化に活用可能となる。要約の所定数に対し、類型ごとに、対応するパターンで判定対象の名詞が用いられているなどで判定された数量を集計し、その多いものを優先して判定結果として後処理へ渡すなどの形で出力することにより、複数の類型に該当する名詞についても、最も一般的な類型、又は数番目までの主要な類型を判定結果として利用できるので、多くのユーザの意図に合致する情報処理結果の最適化が可能となる。
(もっと読む)
言語処理パーサーを組み合わせて、組み合わせパーサーを生成する方法、並びにそのコンピュータ及びコンピュータ・プログラム
【課題】形式言語処理パーサーにFP以外の文字列処理関数、例えば、自然言語処理パーサーを組み合わせたパーサーを自動的に生成する手法を提供する。
【解決手段】文法記述は、第1の文法記述(P1)に関連付けられた第1のパーサーを使用して、入力文字列(str)の先頭文字列から第2の文法記述(P2)に関連付けられた第2のパーサーで最初に受理可能な少なくとも1つのstrの直前の入力文字列までをパーズし、P2を使用して、当該第2のパーサーで最初に受理可能な少なくとも1つのstrをパーズする文法記述P1 U P2; P2に関連付けられた第2のパーサーを使用して、当該第2のパーサーで受理可能であり且つstrの先頭文字列を含む少なくとも1つのstrをパーズし、P1に関連付けられた第1のパーサーを使用して、当該パーズされた少なくとも1つのstrをパーズする文法記述P1 F P2である。
(もっと読む)
自動会話制御システム及び自動会話制御方法
【課題】会話文の送受信による自動会話制御システム及び自動会話制御方法に関し、オペレータ介在制御処理を選択制御可能とする。
【解決手段】利用者の端末1からインターネット2を介してWebサイト3へのアクセス時に、アクセスタグにより自動的に会話処理サイト4にアクセスして、ブラウザ画面15に会話ウインドウ16をポップアップさせ、この会話ウインドウ16を介して会話処理サイト4との間で会話文の送受信による自動会話を継続し、会話処理サイト4の会話サーバ10は、会議制御マスター11と会話集12とを参照して会話文による自動会話を継続し、介入マスター13を参照して、オペレータ介入の要否を判定し、オペレータ介入要と判定した時に、オペレータ操作端末へ介入通知を行い、受信会話文に対する応答会話文をオペレータにより入力して送信する。
(もっと読む)
機械翻訳装置及び機械翻訳プログラム
【課題】該当する専門分野の用語に統一を図った訳文を生成することである。
【解決手段】翻訳辞書部の翻訳辞書情報及び専門用語辞書部の対訳情報を用いて第一言語文書の形態素解析を行い形態素の属性情報及び訳語情報を解析情報として求め、訳語情報に基づき訳文を生成する。その際、専門用語辞書の見出し語が使われて構文解析に失敗したときはその見出しを棄却して訳文を得る。専門用語辞書の見出し語の棄却により訳文を得たときは、単語単位に分割した第一言語の見出し語の訳語候補のいずれかが単語単位に分割した見出し語の訳語に一致しているかどうかを判定し、一致しているものがあるときは、文書解析手段で得られた訳文中のその見出し語の訳語に相当する部分をその訳語候補に置き換える。
(もっと読む)
翻訳の品質を定量化するための装置及び方法
【課題】 あらゆるタイプの文書及び資料の翻訳に、客観的な自動品質管理又は品質保証を適用する装置と方法を提供すること
【解決手段】 翻訳の品質評価を自動化するためのシステム(10)。システム(10)は、プロセッサ(14)、及び操作可能な状態で相互に接続されているメモリデバイス(16)を有するコンピュータ(12)を含んでもよい。第1の言語によるソーステキストは、メモリデバイス(16)内に格納されてよい。第2の言語へのソーステキストの翻訳を含むターゲットテキストもメモリデバイス(16)内に格納されてよい。これに加えて、複数の実行ファイルは、メモリデバイス(16)上に格納されるとともに、プロセッサ(14)によって実行されたときに、1つ以上のブロックを含むテストサンプルを単独で認識するように構成されてもよく、前記各ブロックは、ソーステキストから選択されたソース部分とターゲットテキストから選択された対応するターゲット部分とを有する整合されたセットを含む。
(もっと読む)
同義語辞書生成装置、データ解析装置、データ検出装置、同義語辞書生成方法及び同義語辞書生成プログラム
【課題】異なる複数の文章に含まれる単語を用いて同義語を検出することが可能であって、汎用性を有し、幅広く同義語を定義することが可能な同義語辞書生成装置等を提供する。
【解決手段】文書解析システム100は、入力インターフェース110を介して取得した各アンケートデータに対して、評価表現を示す評価表現テキストと当該評価テキストが修飾する被修飾語テキストのセットをテキストセットとして抽出しつつ、評価表現テキスト、カテゴリ情報及び被修飾語テキストの出現頻度数に基づいて同義語を定義するようになっている。
(もっと読む)
相互機械学習装置、相互機械学習方法、及びプログラム
【課題】高精度の機械学習を行う相互機械学習装置を提供する。
【解決手段】第1方法で第1のコーパスから抽出された、意味関係のある語のペア候補の第1関係ペア候補と、第2方法で第2のコーパスから抽出された、意味関係のある語のペア候補の第2関係ペア候補とに共通する共通ペア、第1のコーパスから抽出された、意味関係のない語のペア候補と第2関係ペア候補に共通する共通ペア、第2のコーパスから抽出された、意味関係のない語のペア候補と第1関係ペア候補に共通する共通ペアが記憶される共通ペア記憶部20、共通ペアの関係の有無を、第1及び第2の学習データの学習結果で分類する第1及び第2の分類部23、24、第1及び第2の分類部23、24による確信度が高い共通ペアを第2及び第1の学習データに追加する追加部25を備え、機械学習、分類、学習データの追加を繰り返す。
(もっと読む)
文作成プログラム及び文作成装置
【課題】入力される文字列が文を構成しない場合において、文字列から文を作成する文作成プログラム及び文作成装置を提供する。
【解決手段】文作成装置1は、文字列を受け付ける文字列受付手段100と、受け付けた文字列を単語に分割する文字列分割手段101と、分割された単語を予め定めた方法で拡張する文字列拡張手段102と、意味保存率情報111を用いて、拡張された文字列の意味の保存率を推定する意味保存率推定手段103と、拡張された文字列の構文としての尤もらしさを推定する尤もらしさ推定手段104と、意味保存率及び尤もらしさに基づいて拡張された文字列を生成した文字列拡張手段102の用いた方法の妥当性を評価する拡張文字列評価手段105と、評価結果に基づいて、拡張された文字列を受け付けた文字列から作成された文の候補として出力する文候補出力手段106とを有する。
(もっと読む)
意味的に類似している語対を二項関係に分類する二項関係分類プログラム、方法及び装置
【課題】名詞間関係及び動詞/形容詞間関係を一括して語間関係として扱い、獲得したい語間関係を予め定義することなく、意味的に類似している語対を二項関係に分類することができる二項関係分類プログラム等を提供する。
【解決手段】文章集合蓄積部から所定閾値以上で共起しやすい複数の語対を抽出し、文章集合蓄積部から語対の語毎に共起する係り受け語集合を抽出する。次に、第1の係り受け語集合に出現し且つ第2の係り受け語集合に出現しない係り受け語からなる第1の特徴係り受け語集合と、第2の係り受け語集合に出現し且つ第1の係り受け語集合に出現しない係り受け語からなる第2の特徴係り受け語集合とを抽出する。更に、係り受け語毎に、語と共起する文書集合中の出現頻度とを計数し、ベクトルを導出し、ベクトル間類似度に基づく分割最適化クラスタリングによって、語対クラスタを生成する。
(もっと読む)
意味的に類似している事態対を二項関係に分類する二項関係分類プログラム、方法及び装置
【課題】獲得したい事態間関係を予め定義することなく、意味的に類似している事態対を二項関係に分類することができる二項関係分類プログラム等を提供する。
【解決手段】文章集合蓄積部から所定閾値以上で共起しやすい名詞対を抽出し、文章集合蓄積部から名詞対の名詞毎に共起する述語集合を抽出し、名詞毎の当該述語集合の出現頻度を表すベクトルに基づく当該名詞対の類似度を用いて名詞対をクラスタリングする。次に、抽出された名詞対について、各名詞と当該述語集合の述語とからなる複数の事態対を生成する。次に、複数の事態対から複数の述語対を抽出し、文章集合蓄積部から述語対の述語毎に共起する名詞集合を抽出し、述語毎の当該名詞集合の出現頻度を表すベクトルに基づく当該述語対の類似度を用いて述語対をクラスタリングする。そして、事態対に含まれる名詞対及び述語対の類似度に基づいて、事態対をクラスタリングする。
(もっと読む)
技術基準文書判定プログラム及び技術基準文書判定装置
【課題】
テキスト情報で構成された建築基準などの技術基準文書を、自然言語処理技術を適用し、コンピュータプログラムに自動変換する。
【解決手段】
本発明に係る技術基準文書判定プログラムは、テキスト情報で構成された技術基準文書に対し、形態素解析と係り受け解析とを施す解析処理と、解析処理の解析結果に基づいて、技術基準文書を条件式を作成する変換処理と、変換処理にて変換された条件式を、建築用CADプログラムのCAD情報と照合し、判定結果を出力する判定処理と、をコンピュータに実行させることを特徴としている。
(もっと読む)
学習システム、シミュレーション装置、および学習方法
【課題】ユーザと対話を行う対話装置が文を出力するために必要な重みベクトルを構築するために多大な労力が必要であった。
【解決手段】対話装置から対話文情報を受け付け、対話文情報が有する手法識別子と対話確率情報とを用いて、ユーザ文種類を決定し、対話文情報が有する1以上の決定要因または1以上のスポットのうちの1以上の情報とを用いて1以上の決定要因または1以上のスポットを取得し、ユーザ文種類識別子と1以上の決定要因または1以上のスポットのうちの1以上の情報とを有するユーザ入力情報を対話装置に送付し、ユーザ嗜好ベクトルと、ユーザ入力情報に含まれるスポットの1以上の評価値との合致度を用いて算出した報酬を用いて、対話装置の手法識別子に対応する重みベクトルを更新する学習方法により、ユーザと対話を行う対話装置が文を出力するために必要な重みベクトルを自動的に構築できる。
(もっと読む)
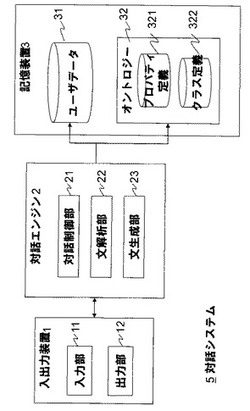
対話装置及びプログラム
【課題】複数ユーザが協調して意思決定を行うことが可能な対話型サービス用データを抽出する。
【解決手段】ユーザとの対話用データを抽出する対話装置100は、ユーザとの対話から抽出されたユーザ毎の個人データを管理する個人データ管理部51と、対象ユーザとの対話において他ユーザに関する個人データの参照の許可/不許可を制御する参照管理部60と、ユーザとの対話対象候補としてのオントロジーを管理するドメイン知識管理部30と、ドメイン知識管理部30により管理されるオントロジーと、個人データ管理部51により管理される対象ユーザの個人データと、参照管理部60により許可された他ユーザの個人データとに基づき、対象ユーザとの対話用データを生成する対話制御部11と、を有する。
(もっと読む)
略称検索装置,方法およびプログラム,ならびに略称検索機能を備えるデータパース装置
【課題】 固有の名称が含まれる文字列から,辞書に未登録の略称を検索できるようにする。
【解決手段】 データパース装置1は,検索対象を入力するデータ入力部13と,辞書記憶部11の辞書をもとに検索対象から法人名称を検索する辞書引き部14と,検索対象に辞書に登録されていない文字列がある場合に,略称を検索する略称検索部15を備える。略称検索部15は,辞書の登録語と部分的に一致する登録語を検索し,検索した登録語から,部分一致する範囲が長く一致の割合が高いものを特定し,特定した登録語と一致する範囲を略称とし,特定した登録語をその正式名称とする。
(もっと読む)
文構造解析装置、文構造解析方法および文構造解析プログラム
【課題】述語項構造解析において、大規模かつ高精度な格フレーム辞書を利用することなく、モデルの複雑さを回避し、計算効率を高める文構造解析装置を提供する。
【解決手段】入力された文章を、形態素を単位とした単語に分割する形態素解析手段と、形態素解析手段によって分割された各単語を基に、複数の文節からなる文節列を生成する文節解析手段と、文節解析手段によって生成された各文節間の係り受け関係を解析する係り受け解析手段と、を備え、係り受け解析手段は、文節解析手段によって生成された文節列から、任意の異なる文節のペアを選択し、選択された文節ペアのそれぞれに対して係り受けスコアを計算してメモリに格納し、所定の閾値以上の係り受けスコアを持つ文節ペアに係り受け関係があると解析する。
(もっと読む)
41 - 60 / 617
[ Back to top ]