
Fターム[5B091AB11]の内容
Fターム[5B091AB11]に分類される特許
1 - 20 / 33
複合語概念分析システム、方法およびプログラム
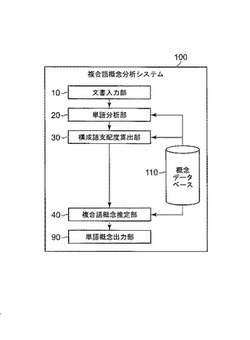
【課題】専門領域での複合語の多い文書中の複合語の概念を推定すること。
【解決手段】複合語を構成語に分割し、同一の構成語を持つ複合語間の共起ベクトルの距離に基づく集約度を構成語支配度として算出し、構成語支配度に基づき各構成語の概念に重み付けを行った合成概念として未知の複合語の概念を抽出することで、専門領域での複合語の多い文書中の複合語の概念を推定する。
(もっと読む)
同義語抽出システム、方法およびプログラム

【課題】情報システム構築に関する提案書や仕様書等、所定の案件に関する文書で、意義は同じで語形が異なる同義語のある文章の曖昧さを改善する。
【解決手段】文章に使用されている各単語毎の品詞や格、組み合される助詞、単語間の係り受け関係に関する単語情報の抽出を行う単語分析部と、任意の単語を基軸単語として選択し、基軸単語と共起関係にある共起語とその共起数に基づく基軸単語共起ベクトルを全基軸単語についてまとめた基軸単語共起表を作成する基軸単語共起表作成部と、単語の一般概念情報を概念データベースに問い合わせ、各基軸単語共起ベクトルの各共起語を概念に変換した基軸単語概念ベクトルを全基軸単語についてまとめた基軸単語概念表を作成する単語概念推定部と、各基軸単語概念ベクトル間の類似性を判定し、類似性が高い基軸単語の組合せを同義語候補として抽出する同義語候補推定部と、同義語候補を出力する同義語候補出力部とを備える。
(もっと読む)
特徴語抽出装置、プログラム及び方法
【課題】テキストマイニングの対象となる文書のデータに対して適切な語の区切りを自動的に設定する。
【解決手段】本特徴語抽出装置は、複数の文書のデータが格納されている文書格納部と、当該複数の文書のデータのうち第1の文書のデータにおける文節の各々を、区切り位置及び区切りの数を変化させつつ分割し、当該分割により得られた文字列をデータ格納部に格納する生成部と、データ格納部に格納されている文字列の各々について、当該文字列が第1の文書のデータに出現する回数と文書格納部に格納されている複数の文書のデータのうち当該文字列が出現する文書のデータの件数とを用いて特徴度を算出する算出部と、第1の文書のデータにおける文節の各々について、当該文節についての文字列のうち特徴度が最も高い文字列を特定し、特徴語格納部に格納する特定部とを有する。
(もっと読む)
情報処理装置、複合語抽出方法、及び複合語抽出プログラム
【課題】大規模データから出現頻度の高い複合語を抽出できる情報処理装置、複合語抽出方法、及び複合語抽出プログラムを提供する。
【解決手段】情報処理装置100は、大規模データから複合語を抽出する装置であって、大規模データに対して形態素解析を行い、解析結果として得た形態素及び/又は形態素の集合である形態素列の出現頻度値を算出し、算出した出現頻度値に基づき、複合語の候補となる文字群を抽出する候補抽出手段14と、抽出された文字群を所定の記憶領域に保持する文字群保持手段42と、文字群保持手段42に保持された文字群から、有効な複合語を判定するための条件を満たす文字群を、出現頻度の高い文字群として抽出する複合語抽出手段21と、を有することを特徴とする。
(もっと読む)
機械翻訳装置及び機械翻訳プログラム
【課題】該当する専門分野の用語に統一を図った訳文を生成することである。
【解決手段】翻訳辞書部の翻訳辞書情報及び専門用語辞書部の対訳情報を用いて第一言語文書の形態素解析を行い形態素の属性情報及び訳語情報を解析情報として求め、訳語情報に基づき訳文を生成する。その際、専門用語辞書の見出し語が使われて構文解析に失敗したときはその見出しを棄却して訳文を得る。専門用語辞書の見出し語の棄却により訳文を得たときは、単語単位に分割した第一言語の見出し語の訳語候補のいずれかが単語単位に分割した見出し語の訳語に一致しているかどうかを判定し、一致しているものがあるときは、文書解析手段で得られた訳文中のその見出し語の訳語に相当する部分をその訳語候補に置き換える。
(もっと読む)
音声合成装置、音声合成プログラムおよび音声合成方法
【課題】テキストの読み上げ精度を向上させ、聞き手が判りやすい自然な読み上げ音声を生成することのできる音声合成装置を提供する。
【解決手段】音声合成装置1は、任意の対象についての情報を示す第1のテキストを形態素解析して第1の解析結果を出力する第1解析部5と、前記第1のテキストが示す情報と同一の対象について表現が異なる情報を示す第2のテキストを形態素解析し、前記第1の解析結果を参照して第2の解析結果を出力する第2解析部6と、前記第2の解析結果に基づいて、前記第2のテキストに関する合成音声を生成するための表音文字列を生成する表音文字列生成部8とを備える。
(もっと読む)
翻訳支援装置、方法及びプログラム
【課題】翻訳者の訳語決定作業を適切に支援する。
【解決手段】本装置は、第1言語の単語と当該単語に対する第2言語の訳語とを格納する訳語格納部と、第2言語による例文を格納するコーパス格納部と、第1言語の複合語の入力を受け付けた際、当該複合語に含まれる各単語について、訳語格納部から当該単語に対する訳語を取得する取得部と、取得した訳語の組み合わせで表される第1訳語列の一部分である第2訳語列を生成する訳語列生成部と、第1訳語列に含まれ且つ第2訳語列には含まれない単語である差分単語の代わりとしてワイルドカード検索のための所定のデータを第2訳語列に付して検索キーを生成するキー生成部と、検索キーを用いてコーパス格納部を検索し、当該検索キーにて検出された単語列から第2訳語列以外の単語である代替訳語を抽出する抽出部と、第1訳語列と共に、差分単語の該当部分に対応付けて、抽出された代替訳語を列挙して提示する出力部とを有する。
(もっと読む)
複合語分割
複合語を脱複合語化する、コンピュータ記憶媒体上で符号化されたコンピュータプログラムを含む、方法、システム及び装置が開示される。ある態様では、方法は、文字のシーケンスを含むトークンを取得するステップと、前記トークンの構成要素である2つ又はそれ以上の候補部分語と、前記部分語を前記トークンに変換するために必要な1つ又はそれ以上の形態素演算とを識別するステップであって、前記形態素演算の少なくとも1つは、辞書にない単語の使用を含む、ステップと、各々の部分語に関するコスト及び各々の形態素演算に関するコストを決定するステップとを含んでいる。  (もっと読む)
(もっと読む)
漢字複合語分割方法及び漢字複合語分割装置
【課題】 日本語文書に含まれる連続する漢字列で構成された漢字複合語を超高精度で正しく分割することができ、分割した各漢字列の信頼性が実用化することができる程度まで高められた、漢字複合語分割方法及び漢字複合語分割装置を提供する。
【解決手段】 連続する漢字列で構成された漢字複合語を分割する場合の基となる基本単語と基本単語に該当する品詞を関連付けて記録した日本語辞書と、漢字複合語を分割した後に構成される各漢字列の字数の配列を示した分割パターンと漢字複合語を分割した後に構成される各漢字列に該当する品詞の配列を表した品詞列パターンのうち当該分割パターンに存在するものを関連付け、漢字複合語の字数毎に分類して記録した単語分割パターン辞書とを参照して、分割対象の漢字複合語を分割する漢字複合語分割方法などにより課題を解決した。
(もっと読む)
複合名詞抽出装置
【課題】 事前に複合名詞リストや詳細なルールを記述することなく、適切な複合名詞を抽出することが可能な複合名詞抽出装置を提供する。
【解決手段】 文書データを形態素解析した後、形態素の品詞情報で品詞結合規則を参照し、連続する形態素が結合規則に適合する場合に、その連続する形態素を複合名詞候補として、複合名詞候補データ150を得る。そして、複合名詞候補を構成する先頭の形態素、末尾の形態素それぞれについて、文字列頻度データを参照して先頭の形態素の前方スコア、末尾の形態素の後方スコアを取得し、両スコアがともにスコア設定値より大きい場合に、先頭の形態素から末尾の形態素までの文字列を複合名詞として抽出する。
(もっと読む)
機械翻訳装置、方法及びプログラム
【課題】原文データ中の特定の用語に対してその語の略語が併記されている場合、用語の複数ある翻訳候補から生成した略語と、文中に記載された略語とが一致する翻訳候補を選択して翻訳を行うことである。
【解決手段】用語・略語抽出部26は、原文解析・翻訳部25が辞書部31を参照して入力部22で受け付けた原文データを解析した解析結果を参照して、原文から略語とそれに対応する展開表記の用語とを抽出し、生成略語選択部28は、略語生成部27によって生成された生成略語と用語・略語抽出部26が原文データから抽出した抽出略語とを比較して一致度が100%の生成略語を選択し、原文解析・翻訳部25は、略語生成部27が生成の元とした第二言語の翻訳候補を翻訳結果に使用する。
(もっと読む)
言語処理システムおよびプログラム
【課題】入力文の記号論理式レベルの文への単純化、記号論理式レベルの単純な文を用いた推論、及び記号論理式レベルの文に基づく出力文の生成の統一的、単純な方法による実現、並びに同様な方法による論理又は言語表現の自動的学習の実現。
【解決手段】従来記号論理式によって行われている推論処理を、記号論理式と同レベルの単純さの自然言語文を用いて行い、それにより入力文から出力文への変換処理を統一する。また、入力文から記号論理式レベルの文への言い換えを逆用して、出力文生成を実現する。さらに、同様の言い換えを利用して、単純化された論理又は言語表現を抽出する。
(もっと読む)
語分割装置および方法
【課題】形態素解析器では分割できないような新語や造語であっても、語分割することが可能となる。
【解決手段】文字列の入力を受け付け入力文字列を得る入力手段101と、入力文字列の全ての文字間で入力文字列を2分割し、前半文字列と後半文字列とからなる分割文字列を得る分割手段102と、入力文字列が出現した度数を示す数である第1頻度と、前半文字列が出現した度数を示す数である第2頻度と、後半文字列が出現した度数を示す数である第3頻度を取得する取得手段103と、第1頻度の値と、第2頻度の値および第3頻度の値のうちの小さい方の値との比により、複数の分割文字列のうちの比が最小となる分割文字列を最適分割文字列として判定する第1判定手段104と、最適分割文字列に含まれる最適前半文字列および最適後半文字列の少なくとも1つが、停止条件を満たす場合は、基本語として判定する第2判定手段105と、を具備する。
(もっと読む)
機械翻訳装置及び機械翻訳プログラム
【課題】ユーザにより辞書登録または訳語学習された語句の関連語の辞書登録/訳語学習を何度も行う手間を省き、翻訳処理の効率を上げることである。
【解決手段】ユーザによって指定された第一言語の原文中の辞書登録または訳語学習の対象となる原文語句、その原文語句に対応する訳文語句及び訳文語句の訳語情報を辞書登録/訳語学習指定部26aで受け付け、登録見出し語・訳語対応付け部26bで原文語句の構成語と訳文語句の構成語との対応付けを行い、関連表現パターン展開部27aは、関連表現パターン定義格納部27cに格納された関連表現パターンに基づいて辞書登録または訳語学習の対象となる原文語句の関連表現を展開し原文語句から派生する関連語句を作成し、訳出パターン作成部27bは関連表現パターン展開部27aで作成された関連語句に対して関連語句の訳語を作成する。
(もっと読む)
電子機器、形態素複合方法及びそのプログラム
【課題】より一般化され網羅性がある形態素複合ルールを生成すること。
【解決手段】形態素複合ルール生成エンジン22は、サンプル文章から形態素解析された形態素と、その形態素の品詞との基本組み合わせ及びその部分集合の組み合わせを算出し、全組み合わせのうち、出現比率が所定の閾値以上である組み合わせを複合ルール候補として抽出する。形態素複合ルール生成エンジン22は、形態素解析後の他のサンプル文章に複合ルール候補を適用して形態素を複合し、その複合語の、インターネット上の検索エンジンによる完全一致検索数が所定数以上である場合に、その複合ルール候補を正式複合ルールとして確定する。
(もっと読む)
複合語の区切り位置を推定する複合語区切り推定装置、方法、およびプログラム
【課題】予め辞書に登録されている語のみならず、登録されていない語についても複合語であるか否かの推定を行い、また、複合語である場合には適切な区切り位置を推定する複合語区切り推定装置、方法、およびプログラムを提供すること。
【解決手段】予め、複数の語について、語が複数の形態素で構成される複合語であるか否かの情報、および複合語である場合には複合語を構成する複数の形態素間の区切り位置を記憶する学習データ記憶部と、ベクトル処理部にて、語が含む文字それぞれの特徴量を用いてベクトル化した、未知語のベクトルと複数の学習データ記憶部に記憶されている既知語のベクトルそれぞれとの類似度を計算する類似度計算部と、類似度に基づいて、未知語が複合語であるか否かの推定および複合語である未知語の形態素間の区切り位置を推定する推定部と、を備えた複合語区切り推定装置。
(もっと読む)
言語処理システムおよびプログラム
【課題】入力文の記号論理式レベルの文への単純化、記号論理式レベルの単純な文を用いた推論、及び記号論理式レベルの文に基づく出力文の生成の統一的、単純な方法による実現、並びに同様な方法による論理又は言い換え表現の自動的学習の実現。
【解決手段】従来記号論理によって行われている推論処理を、記号論理式と同レベルの単純さの自然言語文を用いて行い、それにより入力文から出力文への変換処理を統一する。また、入力文から記号論理式レベルの単純さの文への言い換えを逆用して、記号論理式レベルの単純さの文に基づく出力文生成を実現する。さらに、同様の言い換えを利用して、単純化された論理又は言い換え表現を抽出して利用する。
(もっと読む)
情報処理装置および情報処理方法、プログラム、並びに、記録媒体
【課題】辞書に登録されていない複合語を検出する。
【解決手段】複合語処理規則の例の最初の規則では、表記の規定がない名詞と表記が「株式会社」である単語との2つの単語が隣接する場合は、双方を結合して品詞を固有名詞とするルールが記述されている。そして、2つ目の規則では、表記の規定がない名詞と表記が「社長」である単語との2つの単語が隣接する場合は、双方を結合して品詞を固有名詞とするルールが記述されている。そして、3つ目の規則では、表記の規定がない名詞と表記が「一塁手」である単語との2つの単語が隣接する場合は、双方を結合して品詞を固有名詞とするルールが記述されている。複合語処理部は、形態素解析部の制御に基づいて、形態素解析情報を取得し、複合語処理規則データベースに登録されている複合語処理規則を参照して、形態素解析情報を複合語解析情報に変換する。本発明は、パーソナルコンピュータに適用できる。
(もっと読む)
タグ付きデータを有する完全形式レキシコンおよびタグ付きデータを構成し使用する方法
【課題】コンピュータ可読媒体に格納され、言語処理システムによって使用されるレキシコンを提供すること。
【解決手段】レキシコンは、単語情報を、入力された各単語に関連づけられた複数のデータフィールドに格納することができる。データフィールドは、スペルおよび文法についての情報と、品詞と、入力された単語が別の単語に変形されることができるステップと、単語の記述と、複合語に関するセグメンテーションとを含むことができる。レキシコンに格納されることができない情報は、中間索引テーブルに格納されることができる。レキシコンを構成し、更新し、使用するための、関連する方法が提示される。
(もっと読む)
音声出力装置及び音声出力プログラム
【課題】各複合語を正確に音声出力する。
【解決手段】電子辞書1は、各複合語に音声データを対応付けて記憶する音声データベース83と、テキストを表示する表示部40と、表示部40に表示されたテキスト中の何れかの単語を、ユーザ操作に基づき指定単語として指定する入力部30と、指定単語を先頭として表示部40によりテキスト中に表示されており、かつ、音声データベース83により音声データの記憶されている複合語を検出するCPU20と、CPU20によって検出された複合語に対応する音声データを音声出力する音声出力部50と、を備える。
(もっと読む)
1 - 20 / 33
[ Back to top ]