
Fターム[5B091BA05]の内容
Fターム[5B091BA05]に分類される特許
1 - 20 / 45
文生成装置及びプログラム
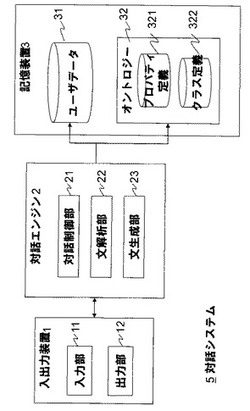
【課題】文生成に用いるテンプレートの再利用性を向上させ、条件や参照先の値に応じてきめ細かな文を生成することができる文生成装置及びプログラムを提供する。
【解決手段】本発明の文生成装置は、概念や概念間の関係を示すドメイン知識を体系的に表現したオントロジーと、概念及び概念間の関係に関連付けられたものであって、少なくとも、生成する文の変数とする参照先情報の参照先と所定の文字列とを含む1又は複数の可変部を有する文テンプレートとを格納するオントロジー格納手段と、文を生成する際、オントロジー格納手段から生成する文に関する概念に関連する文テンプレートを選択する文テンプレート選択手段と、選択された文テンプレートの各可変部に含まれている参照先に基づいて取得した参照先情報を展開し、参照先情報の直前及び又は直後に文字列を合成して出力文を生成する文生成手段を備える。
(もっと読む)
翻訳装置、翻訳方法、及び翻訳プログラム

【課題】正確な翻訳文を得るととともに、表現可能な範囲の拡張性を確保した翻訳技術を提供する。
【解決手段】第1の言語で記述された第1の例文と、当該第1の例文を第2の言語で記述した第2の例文とを格納する例文格納手段を備えた翻訳装置において、複数の候補例文の中から利用者により選択された前記第1の例文と、当該第1の例文における所定の構成部に埋め込まれる文字列として利用者により入力された文字列とを取得する制御手段と、前記文字列を前記第2の言語の文字列に翻訳するとともに、前記第1の例文に対応する前記第2の例文を前記例文格納手段から読み出し、前記所定の構成部に対応する前記第2の例文における構成部に、前記第2の言語の文字列を埋め込むことにより翻訳文を生成し、当該翻訳文を出力する翻訳手段と、を備える。
(もっと読む)
情報処理装置、表示制御方法、およびプログラム
【課題】ユーザが選択した原文の範囲と対応関係にある翻訳文の範囲を、ユーザが確認可能な翻訳装置を提供する。
【解決手段】対訳テンプレートを用いて第1言語による第1文を第2言語による第2文に翻訳する翻訳装置1であって、第1文と第2文とを出力部11に表示させる表示制御部25と、第1文に含まれる1つまたは複数の語句が選択されたことを検知する検知部32と、少なくとも対訳テンプレートに基づいて、第2文に含まれる、選択された語句に対応する複数の対応語句を特定する特定部33とを備え、表示制御部25は、対応語句が特定されたことに基づき、当該対応語句の表示態様を変更する。
(もっと読む)
翻訳支援装置及び翻訳支援プログラム
【課題】 翻訳対象となる文の構造の正確さを損なわないように翻訳支援する翻訳支援装置及び翻訳支援プログラムを提供することを目的とする。
【解決手段】 入力画面上の表示欄に表示された翻訳対象を、分解に関する第1の指示に基づいて、文の骨格をなす主構造と文の構成要素をなす副構造とに分解する分解手段110と、主構造及び副構造を、翻訳に関する第2の指示に基づいて、それぞれ翻訳する翻訳手段120と、翻訳手段によって翻訳された主構造及び副構造を、合成に関する第3の指示に基づいて、合成する合成手段150と、合成手段により合成された主構造及び副構造を表示装置に表示させる表示制御手段160と、を有する。
(もっと読む)
検索結果出力プログラム、検索結果出力装置、および検索結果出力方法
【課題】例文の検索結果を適切な順序で提示可能な検索結果出力装置を提供することを目的とする。
【解決手段】検索結果出力装置100は、評価手段100aが入力例文110aを基準に検索例文110bを評価して抽出例文110dを得る。そして、抽出例文110dの評価110cに寄与した部分を除外した入力例文110aの一部を再評価対象部分110eとして選択する。再評価手段100dは、再評価対象部分110eを基準に検索例文110bを評価(再評価)する。これにより、検索結果出力装置100は、評価110cの高評価と再評価110fの高評価とが必ずしも一致せず、同じ評価基準による同じような検索結果が連続することを好適に避けることができる。
(もっと読む)
翻訳プログラム、翻訳システム、翻訳システムの製造方法及び対訳データ生成方法
【課題】処理負荷が小さく、かつ、翻訳精度の高い翻訳システム及び翻訳プログラムを提供する。
【解決手段】第1言語で表現された原文データ13を受け取り、翻訳処理部40は、前記原文データに基づいて第1の対訳データ記憶部32に記憶されたいずれかの第1言語単文データを翻訳対象として選択する翻訳対象選択処理部44と、翻訳対象として選択された第1言語単文データと対訳関係を有する第2言語単文データを第1の対訳データ記憶部34から読み出して、読み出した第2言語単文データに基づき訳文データを出力する対訳出力処理部48とを含む。前記第1言語単文データの語句にキーワード情報が設定され、前記キーワード情報に基づき前記原文データと前記第1言語単文データとを比較して、比較結果に基づき前記第1の対訳データ記憶部からいずれかの第1言語単文データを翻訳対象として選択する。
(もっと読む)
音声翻訳装置および方法
【課題】翻訳したい発話内容に目的言語の固有名詞が含まれる場合であっても、当該発話内容を音声入力する必要のある利用者の負担を軽減させることができる音声翻訳装置おび方法を提供する。
【解決手段】固有名詞抽出部は、文書から目的言語の固有名詞と意味クラスを抽出して検索情報記憶部に記憶させ、入力受付部は、原言語の音声発話の入力を受け付け、認識部は、受け付けられた音声発話を認識して文字列を生成し、一般名詞抽出部は、生成された文字列から一般名詞と意味クラスを抽出し、検索部は、抽出された一般名詞が属する意味クラスに属する固有名詞を検索情報記憶部から検索し、表示制御部は、検索された固有名詞を表示させ、選択受付部は、翻訳に用いる固有名詞の選択を受け付け、翻訳部は、生成された原言語の文字列を、翻訳に用いる固有名詞を用いて目的言語に翻訳し、出力制御部は、翻訳結果を出力させる。
(もっと読む)
情報処理装置および情報処理方法
【課題】同様の翻訳を効率よく実行する。
【解決手段】第1の言語の第1の候補単語に入替え可能な可変部を有する第1の例文と、対応する第1の候補単語を第2の言語で記述した第2の候補単語に入替え可能な第2の可変部を有する第2の例文とを対応付けるテンプレートが格納され、複数キーワードから選択キーワードが指定され、それを第1の候補単語として入替え可能な可変部を持つ第1の例文が1つまたは複数抽出され、その可変部に選択キーワードを入れた第1の例文が表示され、それらから1つが選択され、その第1の例文のテンプレートの内容を特定可能なテンプレート特定情報が格納され(S5812)そのテンプレート特定情報で特定される第1の例文が表示され(S5821〜3)それらから1つの第1の例文が選択され(S5831)テンプレート特定情報で特定される選択された第1の例文に対応する第2の例文が表示される(S5832)。
(もっと読む)
情報処理装置および情報処理方法
【課題】ユーザが例文に含まれる可変部の単語を容易に変更できる装置を提供する。
【解決手段】例文選択部444は、入力部410が受け付けた指示に基づいて、テンプレートデータベースから例文を選択する。訳文出力部446は、例文選択部444が選択した例文、および、例文の訳文を表示部462に表示する。さらに、訳文出力部446は、例文選択部444が選択した例文の可変部に対応付けて、可変部を指定する指定記号を表示部462に表示する。また、訳文出力部446は、入力部410が指定記号に対応する文字入力を受け付けると、入力された文字に対応する可変部に入替え可能な単語候補を、表示部462に表示する。
(もっと読む)
情報処理装置および情報処理方法
【課題】ユーザが、所望するコンテンツを容易に検索できる装置を提供する。
【解決手段】会話アシスト装置100は、入力部410と記憶部420と処理部440と出力部460とを備える。記憶部422に格納されているテンプレートデータベース422は、複数のテンプレート500からなる。各テンプレート500は、複数の言語のカテゴリ文と、キーワードとを対応付けている。キーワードは、1つのキーワードの表記と、1つまたは複数の文字入力(キーワードの読み)とで指定される。入力部410が複数の文字入力のいずれかを受け付けると、例文選択部440は、入力された文字入力に対応するキーワードをもつテンプレート500を抽出する。
(もっと読む)
情報処理装置および情報処理方法
【課題】ユーザが所望の例文および訳文を容易に検索できる装置を提供する。
【解決手段】キーワード選択部442は、予測キーワードリスト428に基づき、入力部410が受け付けた文字入力に対応するキーワードを表示部462に表示する。例文選択部444は、入力部410が受け付けた指示に基づいて表示されたキーワードの中から選択キーワードを決定する。そして、例文選択部444は、選択キーワードに関連する例文を、テンプレートデータベース422およびインデックスデータ424に基づいて取得し、表示部462に表示する。訳文出力部446は、入力部410が受け付けた指示に基づいて表示されたキーワードの中から1つの例文を選択し、選択された例文の訳文を、テンプレートデータベース422および辞書423に基づいて取得する。そして、訳文出力部446は、取得した訳文を出力部460に出力させる。
(もっと読む)
翻訳プログラム、翻訳システム及び対訳データ生成方法
【課題】処理負荷が小さく、かつ、翻訳精度の高い翻訳システム及び翻訳プログラム、並びに、対訳データ生成方法を提供すること。
【解決手段】翻訳システム1は、第1言語で表現された複数の第1言語単文データと、第2言語で表現された複数の第2言語単文データとを含み、対訳関係を有する前記第1言語単文データと前記第2言語単文データとが関連付けられて記憶された第1の対訳データ記憶部32と、前記第1言語で表現された原文データを受け取り、前記原文データの訳文データを出力する翻訳処理部40とを含む。前記翻訳処理部40は、前記原文データに基づいて前記第1の対訳データ記憶部に記憶されたいずれかの第1言語単文データを翻訳対象として選択する翻訳対象選択処理部44と、翻訳対象として選択された第1言語単文データと対訳関係を有する第2言語単文データを前記第1の対訳データ記憶部から読み出して、読み出した第2言語単文データに基づき前記訳文データを出力する対訳出力処理部48とを含む。
(もっと読む)
音訳モデル作成装置、音訳装置、及びそれらのためのコンピュータプログラム
【課題】言語の実情に即した音訳モデルを生成し、その音訳モデルを利用して言語間の音訳を信頼性高く行なうことが可能な音訳装置を提供する。
【解決手段】音訳装置20は、第1及び第2の言語の単語の音訳対を記憶する音訳対記憶装置30と、それら音訳対の各々について、第1の言語と第2の言語の単語又は単語列を構成する文字又は文字列を互いに対応付け、互いに対応付けられた音訳対の各々の第1の言語の文字及び第2の言語の文字を互いの訳語とみなして翻訳モデル48を作成し、音訳モデルとして出力する翻訳モデル作成部44と、第2の言語の文字を単位とするNグラム言語モデル50を作成言語モデル昨西部46と、第1の言語の入力単語52が与えられると、翻訳モデル48をと言語モデル50とを用いた統計的自動翻訳により入力単語52を第2の言語の単語56に音訳して出力する自動翻訳装置54とを含む。
(もっと読む)
電子機器、その制御方法およびコンピュータプログラム
【課題】翻訳文書を出力する電子機器において利便性を向上させる。
【解決手段】携帯型翻訳機1では、プロファイルデータ記憶部133に「体型(洋服のサイズ)」等のプロファイル項目に関連付けられてユーザの特性を示す値が記憶されており、ユーザに提示される返答例にプロファイル項目に関連した値が挿入される。また、携帯型翻訳機1では、入力された会話文からプロファイル項目の値の候補となる値が抽出され、当該値がプロファイル項目とともに更新用情報記憶部136Aに記憶され、プロファイルデータ記憶部133に記憶されるプロファイルデータの更新に利用される。
(もっと読む)
原言語文を目的言語文に機械翻訳する装置、方法およびプログラム
【課題】用例ベースの翻訳方式の翻訳精度を向上させる機械翻訳装置を提供する。
【解決手段】原言語による入力文を受付ける受付部101と、入力文と一致または類似する原言語の用例に対応する目的言語の用例に基づいて、入力文を目的言語に翻訳した用例翻訳候補と、用例翻訳候補の確からしさを表す第1尤度とを求める用例翻訳部102と、用例翻訳部102による処理と異なる処理により入力文を目的言語に翻訳し、入力文の単語それぞれに対する翻訳結果の候補のうち、第2尤度が第1閾値以上である候補を表す訳語候補を生成する生成部103と、用例翻訳候補それぞれについて、用例翻訳候補に含まれる訳語が訳語候補に存在しない場合に、第1尤度を所定値だけ下げる変更部105aと、用例翻訳候補から第1尤度が最大の用例翻訳候補を選択する選択部105bと、を備えた。
(もっと読む)
翻訳システム及び翻訳プログラム、並びに、対訳データ生成方法
【課題】処理負荷が小さく、かつ、翻訳精度の高い翻訳システム及び翻訳プログラム、並びに、対訳データ生成方法を提供する。
【解決手段】翻訳システムは、複数の第1言語単文データと、複数の第2言語単文データとが、対応する第1言語単文と第2言語単文とが対訳となるように関連付けられて記憶された対訳データ記憶部32と、所与の原語単文に対応する原語単文データに基づいて、原語単文の対訳となる訳語単文に対応する訳語単文データを出力する訳語単文データ出力処理部40と、を含む。訳語単文データ出力処理部40は、第1言語原語単文データを受け付けて、受け付けた第1言語原語単文データに基づいて対訳データ記憶部に記憶された第1言語単文データのいずれかを選択し、選択された第1言語単文データに関連付けられた第2言語単文データを、訳語単文データとして出力する。
(もっと読む)
翻訳装置、方法及びプログラム
【課題】多言語話者間での効率的な対話を可能にする。
【解決手段】第1の言語の例文に含まれている複数の単語及び句のそれぞれを意味的に抽象化した複数のクラス情報の構文木を蓄積する例文蓄積部と、第1の言語の文に含まれている複数の単語及び句のそれぞれを意味的に抽象化して、複数のクラス情報を特定する意味的抽象化部と、例文蓄積部に蓄積された例文の構文木と、特定されたクラス情報の構文木とが類似する場合に、特定されたクラス情報の構文木の抽象化前の複数の単語及び句の出力単位で分割する分割部と、第1の言語の単語及び句の出力単位と意味的に対応する、第2の言語の単語及び句の出力単位を生成する翻訳出力単位生成部と、第1の言語の単語及び句の出力単位と、生成された第2の言語の単語及び句の出力単位とを、対応する意味同士で対応付ける対応付部と、を備える。
(もっと読む)
音声を翻訳する装置、方法およびプログラム
【課題】音声翻訳時の認識精度を向上させる音声翻訳装置を提供する。
【解決手段】原言語の用例と目的言語の用例とを記憶する用例記憶部121と、音声を受付ける音声受付部101と、音声を認識して原言語の発話文字列となりうる複数の候補と尤度とを生成する認識部103と、候補と類似する用例を用例記憶部121から取得する用例取得部104と、用例中で候補との間の差異部分に相当する差異語句と、候補中で用例との差異部分に相当する代替語句とを検出する検出部105と、差異語句の意味属性と同一の意味属性に対応づけられた代替語句を取得する語句取得部106と、尤度が最大の候補の代替語句を、取得された代替語句で置き換えて訂正した候補をさらに生成する生成部107と、訂正された候補に対応する目的言語の用例を用例記憶部121から取得することにより、候補を目的言語に翻訳する翻訳部108と、を備えた。
(もっと読む)
翻訳装置及び翻訳プログラム
【課題】入力文に含まれる基本的な情報を翻訳文に確実に反映させることができると共に、入力文と類似する用例や入力文と一致するパターンがなくても、当該入力文を自然な翻訳文にして出力することができる翻訳装置及び翻訳プログラムを提供する。
【解決手段】翻訳装置1は、入力された集合文章から話題を特定して、この話題を特定した集合文章に含まれる第一言語の文章である入力文を、第二言語の文章である翻訳文にして出力するものであって、集合文章話題分類手段3と、キーワードデータベース5と、基本情報取得手段7と、基本情報データベース9と、基本情報値抽出手段11と、基本情報値抽出規則データベース13と、基本情報値翻訳変換手段15と、対訳変換データベース17と、翻訳文出力手段19と、テンプレートデータベース21とを備える構成とした。
(もっと読む)
機械翻訳装置、置換辞書生成装置、機械翻訳方法、置換辞書生成方法、及びプログラム
【課題】機械翻訳情報に含まれない単語の対訳関係を示す対訳辞書情報を適切に追加することができる機械翻訳装置を提供する。
【解決手段】翻訳対象フレーズを受け付ける翻訳対象フレーズ受付部16、翻訳対象フレーズにおいて対訳辞書情報に含まれる未知単語を検出する未知単語検出部17、検出された未知単語を、機械翻訳情報に含まれる単語の対訳関係を示す置換辞書情報に含まれる原言語の単語に置換する置換部18、置換後の翻訳対象フレーズを、機械翻訳情報を用いて機械翻訳する機械翻訳部19、翻訳後フレーズにおいて、置換部18が置換した原言語の単語に対応する目的言語の単語である置換単語を検出する置換単語検出部20、置換単語を未知単語に対訳辞書情報によって対応付けられる目的言語の単語に置換する逆置換部21、その置換後の翻訳後フレーズを出力する出力部22を備える。
(もっと読む)
1 - 20 / 45
[ Back to top ]