
Fターム[5B091EA17]の内容
Fターム[5B091EA17]に分類される特許
1 - 20 / 27
形態素の構成文字種を利用して文書の対象者を判定する情報処理装置及びプログラム
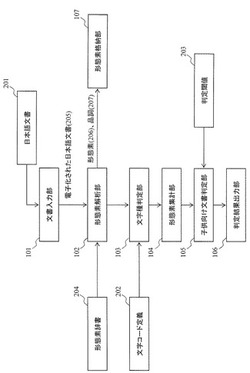
【課題】日本語で記述された文書を、その記述形態に依存することなく、文書の対象者(例えば子供向けか大人向けか)を判定できるようにする。
【解決手段】日本語で記述された文書を形態素で分割する。次に、各形態素を平仮名のみで構成される形態素と平仮名以外を含む形態素に分類し、各分類の出現頻度を集計する。その後、平仮名のみで構成される形態素の出現割合に基づいて、前記文書の対象者を判定する。
(もっと読む)
辞書作成装置、辞書作成方法、およびプログラム

【課題】効率的に言語解析用の辞書を作成する辞書作成装置等を提供する。
【解決手段】未知語判定プログラム25は、記憶部から書籍のOCRデータを入力し、書誌情報データベース21と照合して作者及びジャンルを特定するとともに、処理対象の語句が、未知語か否かを判定する。未知語の語句については、辞書登録プログラム26に処理を引き渡す。辞書登録プログラム26は、作者別辞書登録プログラム26A、ジャンル別辞書登録プログラム26Bを含み、作者別辞書データベース22、ジャンル別辞書データベース23、および標準辞書データベース24に未知語を登録する。
(もっと読む)
単語帳作成装置及び単語帳作成プログラム
【課題】学習効率を低下させずに容易に単語帳データを作成する。
【解決手段】電子辞書1は、複数の見出し語を有する辞書データベース820を複数記憶するフラッシュROM80と、科目毎に、辞書データベース820の何れかを検索対象辞書データベース820Tとして記憶する科目別検索条件テーブル87と、外部からテキストデータ851を取得するとともに、当該テキストデータ851の科目を検知するCPU20とを備える。CPU20は、テキストデータ851に含まれる各単語を検出するとともに、テキストデータ851の科目に対応する検索対象辞書データベース820Tを検出し、検出された単語から、当該検索対象辞書データベース820Tに見出し語として存在する単語を抽出する。単語帳テーブル86は、CPU20により抽出された単語と、テキストデータ851の科目とを対応づけて記憶する。
(もっと読む)
テキスト・データに含まれる固有表現又は専門用語から用語辞書を作成するためのコンピュータ・システム、並びにその方法及びコンピュータ・プログラム
【課題】単語カテゴリの用語辞書を構築する場合に、新規追加されたテキストから、登録すべき単語を漏れなく見つけ、且つ作業を効率的に行う。
【解決手段】テキスト・データの形態素解析を行い、トークン列データを取得する形態素解析部と、上記トークン列データの各トークンをカテゴリ辞書を用いて判別し、未カテゴリ語を抽出するカテゴリ判別部と、抽出した未カテゴリ語を未カテゴリ語照合ルールと照合し、該未カテゴリ語照合ルールに合致する未カテゴリ語を登録候補語として抽出する未カテゴリ語照合部と、上記未カテゴリ照合部と、上記トークン列データのトークン列をトークン列照合ルールと照合し、該トークン列照合ルールに合致するトークン列を登録候補語として抽出するトークン列照合部とを含み、上記カテゴリ辞書に上記登録候補語を登録するかどうかの選択をユーザに許す許可部とで構成されるコンピュータシステム。
(もっと読む)
位置支援翻訳のための方法、装置及びシステム
【課題】
方法、装置及びシステムは、移動式装置上で起動される翻訳アプリケーションからの翻訳結果を向上させ得る。
【解決手段】
一実施形態によれば、装置上あるいは装置に結合された位置認識又は位置検出方式(例えばグローバル・ポジショニング・システム(GPS)、WiFi及び/又は3G)が位置データを自動的に特定する。一実施形態に従った強化された翻訳方式が位置データを使用し、装置の具体的な物理的地理的位置を突き止める。その後、方言まで細に含む増強現地語辞書が存在する場合、装置はそれをダウンロードする。ユーザが単語及び/又はフレーズの翻訳を望むとき、装置はダウンロードした増強現地語辞書で意味を調べ、翻訳がその地理的位置に特有のものとなることを確保する。ユーザが位置を移るとき、同一語に対して有意に異なる意味を有する地域間でユーザが移動する場合にも語を正しく翻訳し得るよう、装置は更なる“現地”語辞書をダウンロードし得る。
(もっと読む)
情報処理装置、表示データ翻訳方法、及びプログラム
【課題】予め登録された文字情報は勿論のこと、予め登録されていない文字情報を含め、表示データをそれぞれ同義の異なる表示形式で表示する情報処理装置等を提供する。
【解決手段】文字情報を翻訳する汎用翻訳手段と、表示データとして予め登録された静的文字情報に特化して翻訳する専用翻訳手段とを有し、要求された言語形式に応じた表示データを生成する情報処理装置であって、第一の言語形式で文字情報を含む表示データを生成する表示データ生成手段と、生成された表示データの中から、専用翻訳手段で翻訳可能な静的文字情報と、専用翻訳手段で翻訳不可能な動的文字情報とを分別して取得する分別取得手段とを有し、専用翻訳手段は静的文字情報を、汎用翻訳手段は動的文字情報を要求された第二の言語形式に翻訳し、第二の言語形式に翻訳された静的文字情報及び動的文字情報による前記表示データを生成する。
(もっと読む)
翻訳支援方法、翻訳支援装置及びコンピュータプログラム
【課題】翻訳メモリを共有メモリとして用いて翻訳効率を改善すると共に、翻訳メモリの機密性を効果的に維持することができる翻訳支援方法、翻訳支援装置及びコンピュータプログラムを提供する。
【解決手段】原文情報、翻訳文情報及び翻訳に係る局面に関する局面情報を含む付随情報の入力を受け付け、入力を受け付けた局面情報と既に翻訳メモリに記憶されている局面情報との類似度である局面類似度を算出する。算出された局面類似度が所定の閾値より小さい局面情報が存在する場合、局面情報に対応する翻訳文情報についてのみ、入力を受け付けた翻訳文情報との類似度である訳文類似度を算出する。算出された訳文類似度が所定の閾値より大きい翻訳文情報が存在する場合、入力を受け付けた原文情報、翻訳文情報及び付随情報を共有メモリへ複写する。
(もっと読む)
機械翻訳装置及び機械翻訳プログラム
【課題】原文の翻訳の際に原文とは異なる意味を表す訳文が生成されてしまうことを抑制できる機械翻訳装置を提供することである。
【解決手段】第1言語の語句とそれに対応する第2言語の語句を対にして記録する翻訳辞書28と、翻訳に必要な知識・規則及び第1言語の語句の分野情報における第2言語の訳語候補の点数を蓄積した機械翻訳知識データベース29とを有し、翻訳辞書検索部27は翻訳辞書部28及び機械翻訳知識データベース29を参照して第2原語の訳文を作成し、訳語候補検証部30は翻訳辞書28から得た第2言語の訳文に含まれる各語について存在検索単語データベース31を参照して点数により各語の確からしさを調べ、その結果がある一定の基準に達しないときには、翻訳辞書検索部27を再起動して第1言語の原文を解析し直し、これに含まれる第2言語の語句についても確からしさを調べることを繰り返す。
(もっと読む)
情報処理装置、情報処理方法、及びプログラム
【課題】大規模なコーパスから、性能を担保しながら小規模なコーパスを選択する。
【解決手段】情報処理装置1は、コーパスが記憶されるコーパス記憶部11と、サブコーパスが複数記憶される13サブコーパス記憶部と、コーパス記憶部11で記憶されているコーパスを文クラスタリングすることによりサブコーパスに分割し、サブコーパス記憶部13に蓄積するコーパス分割部12と、基準コーパスが記憶される基準コーパス記憶部14と、基準コーパスと、複数のサブコーパスとの類似性に関する情報である類似情報をそれぞれ算出する類似情報算出部15と、類似情報算出部15が算出した類似情報を用いて、基準コーパスと類似性の高い1または2以上のサブコーパスを選択する選択部16と、を備える。
(もっと読む)
翻訳システム、翻訳方法、辞書管理システム及び辞書管理方法
【課題】多人数ユーザの翻訳システムの運用環境に即した組織的で効率的な辞書構築、翻訳環境の整備を行うことである。
【解決手段】ユーザのプロファイルを保持するユーザプロファイル部8と、個々の翻訳要求がどのユーザの発信であるかを識別するユーザ情報同定手段6aと、翻訳要求された自然言語文書中から、辞書部4の知識情報を使って辞書部4に未登録の語句を抽出する未登録語句抽出手段3aと、未登録語句抽出手段3aにより抽出された語句をユーザ情報同定手段6aにより識別されたユーザ情報とユーザプロファイル部8との照合によりユーザプロファイル部8に定義されている内容に応じて分類をし分類情報付きの辞書登録候補語句を出力する辞書作成支援手段とを有する。
(もっと読む)
文書処理装置、文書処理方法およびプログラム
【課題】多言語の文書を効率的に処理する文書処理装置を提供する。
【解決手段】複数の項目に分類された翻訳資源を有する翻訳辞書部102と;翻訳資源の分類項目の少なくともいずれかに関連付けられて利用者により登録される分類小項目のいずれかに対応するように原文書を分類するための分類情報と、原文書の作成言語を区別するための言語情報と、原文書とを含む入力データを、通信回線網20を介して受信するためのデータ受信部106と;入力データ中の分類情報に対応する分類項目に関連する翻訳資源を翻訳辞書部から選択するための辞書選択部122と;選択された翻訳資源に基づいて入力データ中の原文書を他の言語に翻訳するための翻訳部124と;利用者端末10からの操作指令に応じて、入力データ中の原文書および翻訳部により翻訳された原文書の翻訳文書の少なくともいずれかを含む出力データを作成するためのデータ作成部106と、を備える。
(もっと読む)
訳語検索システム、方法及びプログラム
【課題】 ユーザにとって、使い易く分かり易い訳語検索システムを提供する。
【解決手段】 本発明の訳語検索システムは、分野別の辞書が階層構造を構築している分野別辞書データベースを有する。また、ユーザに、検索文字列と検索対象分野とを指定させる検索対象情報取込手段と、検索対象情報取込手段が取り込んだ検索文字列の訳語を、分野別辞書データベースにおける、検索対象情報取込手段が取り込んだ検索対象分野について検索すると共に、検索できない場合には、階層構造上でその上位の検索対象分野について訳語を検索し、検索できない限り、検索対象分野を上位に移行させて訳語を検索する検索手段と、検索手段による検索結果をユーザに提示させる検索結果提示手段とを有する。
(もっと読む)
音声自動翻訳装置、音声自動翻訳方法、音声自動翻訳プログラム
【課題】処理能力の低い装置にも適用することができる翻訳の高速化方法等を提供すること
【解決手段】音声自動翻訳装置1は、単語または語句を話題別にグループ分けして登録した翻訳ライブラリ31と標準翻訳時間32を記憶する記憶部30と、入力された音声情報を音声認識してテキストを生成する音声認識手段21と、グループに設定された検索優先順に従って翻訳ライブラリを検索し、テキストを翻訳する翻訳手段22と、翻訳テキストを翻訳音声情報に変換する音声合成手段23により音声を自動的に翻訳する。検索優先順序変更手段24は、翻訳手段による翻訳に要した翻訳時間を複数回計測し、複数の翻訳時間と標準翻訳時間とを比較し、その比較結果が所定の条件を満たす場合に入力音声の話題を判定し、その判定結果に対応するグループの検索優先順を上げる方向に変更する。
(もっと読む)
分野選択支援装置,分野選択支援方法,およびコンピュータプログラム
【課題】 ユーザが容易かつ適切に翻訳対象文書の分野を選択することができるように支援することの可能な分野選択支援装置を提供する。
【解決手段】 分野選択支援装置110は,翻訳装置120から渡された文書に含まれる語とその語に対する分野毎の訳語を,翻訳装置から抽出する訳語抽出部111と,訳語抽出部により抽出された語と訳語の組に基づいて,ユーザに提示する語と訳語の組を決定する提示語決定部112と,提示語決定部により決定された語と訳語の組をユーザに提示し,ユーザにより選択された訳語が属する分野を翻訳装置に渡す分野選択部130と,を備えたことを特徴とする。分野の違いが訳語に現れている語を抽出して,ユーザが分野を選択するのに有効な語としてユーザに提示することで,ユーザが容易に適切に分野を選択することができるように支援することが可能である。
(もっと読む)
翻訳装置
【課題】翻訳装置において、翻訳される原言語のもつ曖昧性を補正し、原言語の状況に合った精度の高い翻訳を可能とする翻訳装置を提供することを目的とする。
【解決手段】基本辞書24を有する翻訳装置1に、時間を計時する内蔵時計8と、前記内蔵時計8によって計時された時間に応じて異なる表現がなされる第2言語の単語を対象として時間に応じた前記異なる表現の各々と時間とを対応させて記憶する時間依存単語辞書25とを備え、前記基本辞書24に加え、前記時間依存単語辞書25を参照して第1言語を第2言語に翻訳する時間依存翻訳手段と、前記時間依存翻訳手段によって翻訳された翻訳文を出力する出力手段と、を備えた。
(もっと読む)
通信翻訳装置および記録媒体
【課題】インターネットを用いて相互に情報を授受するに際して言語上の違いによる障害を確実に除去することにある。
【解決手段】ネットワーク1上の情報提供装置21〜2nから提供される情報を翻訳処理する通信翻訳装置において、要求元の第1のデータに関連付けられるネットワーク1上の情報提供装置21〜2nから第2のデータを要求するデータ要求手段と、前記要求元の第1のデータの文字列から分野を判定する要求元リンク文字列分野判定手段41と、前記データ要求手段の要求に基づいて受信される第2のデータを前記判定手段41で判定された分野のもとに翻訳処理する翻訳処理手段42とを備えた通信翻訳装置である。
(もっと読む)
機械翻訳装置、機械翻訳方法及び機械翻訳プログラム
【課題】 簡易に翻訳対象文に適した辞書データを用いた翻訳が可能な機械翻訳装置、機械翻訳方法及び機械翻訳プログラムを提供する。
【解決手段】 特徴ベクトル作成部10は、翻訳対象文の特徴を表す翻訳対象特徴ベクトルを作成するとともに、特徴ベクトル作成部20は、専門分野文の特徴を表す専門分野特徴ベクトルを作成する。カテゴリ分類器50は、これらに基づいて、翻訳対象文の各専門分野への帰属可能性を推定し、専門辞書選択部60は、その推定の結果に基づいて、翻訳対象文の翻訳に適した専門辞書データを選択する。
(もっと読む)
対訳語句提示プログラム、対訳語句提示方法および対訳語句提示装置
【課題】ウェブ検索技術及びデータマイニング技術を用いて語句の目的言語における正確な訳を得ること。
【解決手段】語句を入力する入力装置と、語句が入力された後に回答される電子文書及びウェブページによって候補訳を設定し、候補訳の境界を見出し、候補訳の特性をカウンティングする候補訳カウンティング装置と、候補訳のカウンティング装置によって生成されたノイズを識別して処理する候補訳ノイズ処理装置と、候補訳のカウンティング装置から取得した候補訳の特性によってすべてのあり得る候補訳を評価して順位付けする候補訳評価装置と、候補訳の典型的な例示文章をウェブ上でマイニングし、これを典型性の程度によって順位付けする候補訳典型例示文章マイニング装置と、他の言語で重み値に応じた順に配列された語句の候補訳リスト及び典型的な例示文章を出力する出力装置と、を備える。
(もっと読む)
翻訳システム
【課題】 機械翻訳により生成された翻訳文に対して人が行なう校正作業の効率を向上させる。
【解決手段】 入力された原文を構成している各語句に対応する複数の訳語から各々ひとつずつ訳語を選択し、該選択された訳語を組み合わせることによって該原文についての翻訳文を作成する翻訳手段1と、入力された音声に対応する語を、上記語句に対応する訳語であって翻訳手段1によって選択されなかった該訳語から選択し、該選択された訳語を該音声の認識の結果として出力する音声認識手段2と、翻訳手段1により作成された翻訳文を、音声認識手段2から出力された訳語を用いて修正する修正手段3と有するシステムを提供する。
(もっと読む)
翻訳システム
【課題】 機械翻訳により生成された翻訳文に対して人が行なう校正作業の効率を向上させる。
【解決手段】 入力された原文を構成している各語句に対応する複数の訳語から各々ひとつずつ訳語を選択し、該選択された訳語を組み合わせることによって該原文についての翻訳文を作成する翻訳手段1と、入力された音声に対応する語を、上記語句に対応する訳語であって翻訳手段1によって選択されなかった該訳語から選択し、該選択された訳語を該音声の認識の結果として出力する音声認識手段2と、翻訳手段1により作成された翻訳文を、音声認識手段2から出力された訳語を用いて修正する修正手段3と有するシステムを提供する。
(もっと読む)
1 - 20 / 27
[ Back to top ]