
Fターム[5D015BB01]の内容
Fターム[5D015BB01]に分類される特許
1 - 20 / 38
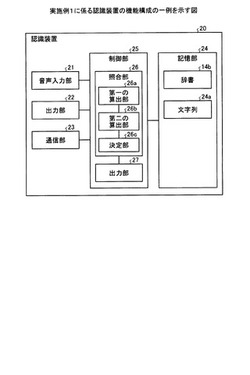
認識装置、認識プログラム、認識方法、生成装置、生成プログラムおよび生成方法
【課題】精度良く音声の認識を行うこと。
【解決手段】認識装置20は、記憶部24と、第一の算出部26aと、第二の算出部26bと、決定部26cとを有する。記憶部24は、文章に含まれる単語と単語の文章内の位置を示す位置情報とを記憶する。第一の算出部26aは、入力された音声信号と、記憶部24に記憶された複数の単語を接続した文字列の読み情報とを比較して、類似度を算出する。第二の算出部26bは、記憶部24に記憶された各単語の位置情報に基づいて、接続した複数の単語間の近さを示す接続スコアを算出する。決定部26cは、類似度および接続スコアに基づいて、音声信号に対応する文字列を決定する。
(もっと読む)
音声認識装置

【課題】ロバスト性が高く、誤認識率を低減させた音声認識装置を提供すること。
【解決手段】音声認識装置は、音素系列のパターンに制限を与える言語モデル22と、音素ラベルを記憶する単語音素ラベル辞書21と、音素ラベルを変換するルールを記憶するラベル変換ルール辞書23と、標準音声パターンを生成する音響モデル24と、を有し、音声を特徴量化する音響特徴量変換部12と、音響特徴量変換部により特徴量化された音声について、言語モデル22と、単語音素ラベル辞書21と、ラベル変換ルール辞書23とを参照して音素ラベルに変換する音素ラベル変換部13と、音素ラベル変換部13で変換された音素ラベルを、音響モデル24により標準音声パターンに変換し、音響特徴量変換部12で特徴量化された音声との類似度を計算する類似度計算部14と、類似度計算部14による計算結果から入力文章を判定する最尤文法決定部15と、を備える。
(もっと読む)
単語関連度テーブル作成装置とその方法と音声認識装置とプログラム
【課題】単語ペアの単語間の関連度の計算を改善した関連度を計算する単語関連度テーブル作成装置と、その単語関連度テーブルを用いた音声認識装置の提供。
【解決手段】単語関連度計算部は、生起回数補正手段と、検定値計算手段と、補正関連度計算手段と備え、単語ペア(wi,wj)の生起回数がr-1回の生起回数を、0では無い小さな値(r-1)Nr/Nr-1に補正すると共に、単語ペア(wi,wj)が共起する回数と各単語が単独で発生する回数との積の差を統計的に検定するt値を求め、t値が大きな単語ペア(wi,wj)の関連度を、補正した生起回数に基づいて再計算する。その結果、共起する回数の少ない単語ペアの関連度は小さな値、共起する回数の多い単語ペアの関連度は大きな値とすることが出来る。
(もっと読む)
音声対話装置および音声対話方法
【課題】
正確な情報であるシステム応答文中の自立語と認識結果中の自立語を用いて共起を生成することで、システム応答文の生成に利用される共起の信頼度を向上させることである。
【解決手段】
実施形態の音声対話装置は、第1のシステム応答文に対するユーザの発声を認識する音声認識手段と、前記音声認識手段で得られた認識結果を形態素解析する形態素解析手段と、前記形態素解析手段で得られた前記認識結果中の自立語と前記第1のシステム応答文中の自立語の共起を生成する共起生成手段と、自立語の共起および当該共起の共起スコアを記憶した共起辞書と、前記共起辞書を用いて、前記共起生成手段で生成された共起に共起スコアを付与する共起スコア付与手段と、前記共起スコア付与手段で付与された共起スコアを利用して、第2のシステム応答文を生成する応答文生成手段とを備える。
(もっと読む)
音声認識装置および音声認識方法
【課題】
単語同士が共起可能か否かを判定して、判定結果を言語制約として使用することにより、発話自由度の高い音声認識装置を得ることを目的とする。
【解決手段】
この発明に係る音声認識装置は、入力音声に対して音声認識処理を行い、複数の認識結果候補を出力する音声認識手段13と、音声認識対象となる単語列を記憶する単語列記憶手段20と、認識結果候補を構成する単語が音声認識対象となる単語列に含まれる数をカウントするカウント手段15と、カウント手段におけるカウント数に基づいて複数の認識結果候補から認識結果を決定する認識結果決定手段17と、を備える。
(もっと読む)
発音辞書を構築するための方法およびシステム
【課題】この発明の実施の形態は、アラインされていないエントリをアラインされたエントリに変換することによって発音辞書を構築するための方法およびシステムを開示する。
【解決手段】アラインされていないエントリおよびアラインされたエントリは、単語のセットと、単語のセットに対応する発音のセットとを含む。上記方法は、単語ごとに、単語と発音予測との間に1対1の対応が存在するように、発音予測を求め、各発音予測を発音のサブセットにマッピングして、各発音予測が発音のサブセットにアラインされた予測−発音マップを作成し、単語と発音予測との1対1の対応を使用して、予測−発音マップに基づいてアラインされたエントリを求めることによって、アラインされたエントリ内の各単語を、発音のサブセットとアラインする。
(もっと読む)
統計的言語モデルへの適応
長期および短期記憶に適切な制約を適用することによって、単語の予期せぬ出現を抑制するアーキテクチャ。適応の迅速性も、制約を活用することによって実現される。本アーキテクチャは、変換結果を出力する変換プロセスによる音声列の変換のためにユーザ入力履歴を処理する履歴コンポーネントと、変換プロセス中に、単語出現に影響する、短期記憶に適用される制約に基づいてユーザ入力履歴に変換プロセスを適応させる適応コンポーネントとを含む。本アーキテクチャは、文脈依存確率の相違に基づく確率上昇(短期記憶)、ならびに長期記憶と単語の先行文脈の頻度に基づくベースライン言語モデルとの間の動的線形補間(長期記憶)を実施する。  (もっと読む)
(もっと読む)
音響信号変換装置、方法、及びプログラム
【課題】
SNR閾値を用いた発話区間検出に関し、話者とマイクロホンの距離が一定ではない環境では、認識性能と誤認識のトレードオフが存在するため、前記SNR閾値の設定が一般に容易ではない。
【解決手段】
音源から発せられる音響信号を電気信号に変換する変換手段と、前記音源からの音響信号が発せられたことを前記電気信号に基づいて検出する音響信号検出手段とを有する音響信号変換装置であって、音響信号を発する音源と当該音響信号を電気信号に変換する変換手段との距離を検出する距離検出手段を有し、前記音源からの音響信号が発せられたことを前記電気信号に基づいて検出する音響信号検出手段の音響信号検出の閾値を前記距離検出手段により検出した距離に応じて変化させる。
(もっと読む)
音声認識方法、携帯端末及びプログラム。
【課題】ユーザーが音声辞書を切り替えるための操作を意識的に行う必要がなく、自動的に最適な音声辞書を選択することができる音声辞書選択方法、携帯端末及びプログラムを提供すること。
【解決手段】作業者Aが携帯する作業者用端末2の現在の位置情報を取得する位置情報取得ステップS22と、作業者用端末2が記憶している位置情報に関連した音声認識辞書を複数備える音声認識辞書テーブル260から、取得した位置情報に対応する音声認識辞書を選択する選択ステップS23と、集音器から音を取得し、音声認識し音声情報を取得する音声情報取得ステップS24と、音声情報及び選択された音声認識辞書に基づき、音声情報を確定する確定ステップS25と、を含む。
(もっと読む)
音声認識装置及び方法
【課題】入力音声における言い直し部分及びその対象部分を推定可能な音声認識装置を提供する。
【解決手段】入力音声を認識辞書に登録されている第1の単語列に順次置き換えた第1の音声認識結果を生成する音声認識部102と、第1の単語列の各々について、第1の単語列の不完全な発声に相当する第2の単語列を順次生成する生成部105と、第1の単語列の各々に相当する部分の前方に隣接する区間音声を入力音声から順次抽出する制御部104と、区間音声を第2の単語列のいずれかに置き換えた第2の音声認識結果を順次生成する音声認識部107と、第2の音声認識結果の各々と、第1の音声認識結果のうち区間音声の各々に相当する部分とを比較し、区間音声が不完全な発声であるか否かを順次判定する判定部108とを具備する。
(もっと読む)
音声認識装置及びコンピュータプログラム
【課題】話者が発声した音声に基づく音声データに対して音節等の発音単位で認識処理を行い、更に語句データベースに記録されている語句と照合するワードスポッティング法等の方法にて認識を行う際に、少ない音節にて構成される語句との照合により生じる誤認識を削減することが可能な音声認識装置及びコンピュータプログラムを提供する。
【解決手段】音声認識装置1は、発音単位で認識処理を行った結果に対し、語句の前方及び/又は後方に付加語句を付加した拡張語句と照合する認識処理を行う。
(もっと読む)
入力装置
【課題】 種々の情報を容易かつ迅速に入力することができる入力装置を提供する。
【解決手段】本発明の目的は、種々の情報を容易かつ迅速に入力することができる入力装置を提供することである。手書き文字入力手段11では、手書き文字入力部14であるタッチパネル10から文字が手書き入力され、この文字が手書き文字認識部15として機能する制御部7によって認識される。音声指示入力手段12では、音声指示入力部16である音声入力部4から指示が音声入力され、この指示が音声指示認識部17として機能する制御部7によって認識される。選択手段13としても機能する制御部7は、手書き文字入力手段11および音声指示入力手段12を選択的に動作させる。
(もっと読む)
書き起こし内容確認方法、書き起こし内容確認装置、コンピュータプログラム
【課題】不正行為や入力ミスの防止を容易に行える書き起こし内容確認装置を提供する。
【解決手段】音声データ、音声データを元に書き起こされたテキストデータ、及び音節の標準的な時間を表す標準音節時間データから、書き起こし内容を確認する。音声データとテキストデータとから導出される当該音声データの音節時間を標準音節時間データと比較して、その比較結果によりテキストデータの妥当性を判断する音節時間比較部14と、音声データを平仮名単位で音声認識して得られる音節認識対数尤度及び音声データの音声認識の結果としてテキストデータと同一の認識結果を1つ得るような音声認識により得られる単語認識対数尤度から導出される、音声データとテキストデータとの合致度合を定量的に表す類似度を所定の値と比較してテキストデータの妥当性を判断する類似度比較部16と、を備える。
(もっと読む)
音声チャットシステム、情報処理装置、音声認識方法およびプログラム
【課題】音声チャットにおける会話中に存在するキーワードを高精度で認識することが可能な、音声チャットシステム、情報処理装置、音声認識方法およびプログラムを提供する。
【解決手段】音声認識を行ないつつ音声チャットを行なう複数の情報処理装置と、複数の情報処理装置と通信網を介して接続された検索サーバと、から構成される音声チャットシステムにおいて、検索サーバが、当該検索サーバにおいて検索が行なわれた検索キーワードを記載した検索キーワードリストを、少なくとも1つの情報処理装置に対して開示するとともに、少なくとも1つの情報処理装置に、検索サーバから検索キーワードリストを取得して、音声認識に利用する単語が記載される認識単語辞書を生成する認識単語辞書生成部と、音声チャットでの会話を音声データとし、認識単語辞書を含む認識用データベースを参照して、音声データを音声認識する音声認識部と、を設ける。
(もっと読む)
言語処理装置
【課題】 未知語もしくは誤解析と判定される用語を含むテキストを、利用者に対して了解性の高いテキストへ変換し得る言語処理方法を提供することを目的としている。
【解決手段】 テキストを解析する言語処理装置において、テキストを解析するテキスト解析手段と、解析結果に未知語が含まれているか否かを判定する未知語判定手段と、解析結果に予め定められた用語が含まれているか否かを判定する特定用語判定手段と、特定用語を別の単語列に変換する単語列変換テーブルと、解析結果に未知語と特定用語が存在する場合に、前記単語列変換テーブルを参照して未知語と特定用語を別の単語列に変換する単語列変換手段とを備える。
(もっと読む)
音声認識装置
【解決課題】認識処理時間を短縮することができるようにする。
【解決手段】音声が入力されると、音節認識手法などを用いて入力音声の先頭から3音節分の音節区間を切り出し、切り出された音節区間を音声認識し(102)、参照用インデックスを参照して、音声認識された3音節分の音節列に対応する辞書識別情報を取得し、音声認識処理で用いる小語彙単語辞書データベースとして、辞書識別情報が示す小語彙単語辞書データベースを選択する(104)。そして、選択された小語彙単語辞書データベースを読み込み、作業用メモリに格納させ(106)、作業用メモリに格納された小語彙単語辞書データベースに格納された全ての語彙単語を逐次探索し、入力された音声が示す単語を音声認識する(108)。
(もっと読む)
音声認識信頼度推定装置、その方法、およびプログラム
【課題】単語や音節などの短区間よりも発話や文単位などの長区間での認識結果の信頼度を求める。
【解決手段】音声認識部6で、発話ごとの単語系列50への分割のほか、各単語の品詞情報52、音響尤度スコア54、言語尤度スコア55、単語尤度スコア56、単語継続時間長58、音素数60、音素継続時間長62を各単語に付与して、情報変換部20で、54、55、56、58、60、62の発話単位での平均値、分散値などの各統計値と品詞情報52を用いたクラス分けによる判定値を要素とする発話単位ごとの発話特徴量ベクトルに変換し、信頼度付与部22で、上記ベクトルと予め学習により求めた識別モデルを用いて推定された認識度に基いて信頼度を求める。
(もっと読む)
楽曲再生装置、プログラム及び楽曲選曲方法
【課題】車載オーディオセットに好適なユーザインタフェースの提供。
【解決手段】楽曲再生装置は、サビやイントロ等のユーザの指定の楽曲の特徴部分が登録されている楽曲を、該楽曲の検索キーワードとともにメドレー状に再生する動作を繰り返す特徴部分連続再生モードにて、発話ボタンの押下待ち状態となる。発話ボタンが押下され、ユーザにより「OK」との発話内容が認識されると、当該時点で再生中の楽曲がHDDより読み出され、該楽曲の先頭から再生される。選択された楽曲の再生後は、再度、上記特徴部分連続再生モードに移行するため、ユーザは、所望のタイミングで「OK」と発話するだけで、次々に再生を行うことが可能となる。
(もっと読む)
音声理解装置、音声理解方法、単語・意味表現組データベースの作成方法、そのプログラムおよび記憶媒体
【課題】 精度の高い音声理解装置を提供する。
【解決手段】 音声理解装置100において、音声理解結果探索部61が、単語・意味表現組N−グラムモデルDB20を用いて音声理解を行う構成とした。また、音声理解装置100は、単語と意味表現との明確な対応付けがされていない言語コーパス10から、単語・意味表現組のN−グラムモデルである単語・意味表現組N−グラムモデルDB20を作成する単語・意味組N−グラムモデル作成部30を備える構成とした。
(もっと読む)
医療音声情報処理装置、及び医療音声情報処理プログラム
【課題】 治療室内で交わされる会話や指示等から、特定の言語表現等を検出し、治療行為に対応するイベントを検出可能な医療音声情報処理装置を提供することを課題とする。
【解決手段】 音声処理装置1は、医療音声情報3の記録等の処理を行う処理装置本体4と、発生した音声を音声情報5として取得するための複数のマイク6と、治療行為提示情報21を提示するための液晶ディスプレイ8及びスピーカ9とによって主に構成されている。そして、マイク6によって取得された音声情報5から、言語データベース28に記憶された治療行為に対する特徴的な言語表現25が所定の時間幅で検出され、治療行為の要部を示すイベントが検出される。これにより、連続的に実施される治療行為で発生する各種イベントをリアルタイムで検出し、イベントインデックス2に記録することができる。
(もっと読む)
1 - 20 / 38
[ Back to top ]