
Fターム[5D015DD03]の内容
Fターム[5D015DD03]の下位に属するFターム
Fターム[5D015DD03]に分類される特許
1 - 20 / 144
発話区間検出装置及びプログラム
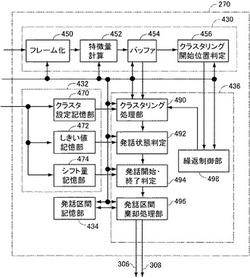
【課題】非定常な雑音環境下でも精度良く発話区間を検出できるようにする。
【解決手段】発話区間検出装置270は、音声信号のシーケンス中で発話開始位置である可能性の高いフレームを検出するクラスタリング開始位置判定部456と、クラスタリング開始位置が検出された後、その位置のフレームよりプレロール時間だけ前のフレームから最新に受信したフレームまでを音声パワーの値に基づき10ミリ秒ごとにクラスタリングする処理を開始して各フレームのクラスタレベルを算出するクラスタリング処理部490と、各フレームについて算出されたクラスタレベルのシーケンスに基づいて、50ミリ秒ごとに発話開始位置及び発話終了位置を検出する処理を繰返し行なう発話状態判定部492及び発話開始・終了判定部494とを含む。
(もっと読む)
音声認識装置とその方法とプログラム

【課題】音声認識処理を並列に行うことで音声認識処理を高速にした音声認識装置を提供する。
【解決手段】この発明の音声認識装置は、音声分割部と、音声記憶部と、分割音声分配部と、音声認識処理群と、音声認識結果統合部と、を具備する。音声分割部は、音声信号を入力として、当該音声信号の音声・非音声判別を行い非音声区間の区間長が非音声分割区間長閾値Tp以上の場合に音声区間を分割し、上記音声信号を発話区間単位に分割した分割済み音声を出力する。そして、分割音声分配部は、分割済み音声記憶部に記憶された発話区間を、複数の音声認識部で構成された音声認識処理群に分配する。音声認識結果統合部は、音声認識処理群が出力する複数の音声認識結果を時間順に結合して、音声信号に対する音声認識結果を出力する。
(もっと読む)
音声認識装置および音声認識装置における電源供給制御方法
【目的】
本発明は、音声認識装置において、電源制御機構にリセット信号処理を追加することにより、無駄な電源投入を避け、簡単に、かつ大幅に電源の消費電力の低減を図ることを目的とする。
【構成】
本発明は、音声認識装置において、マイコンにリセット信号出力機構を設け、リセット信号が入力されると一定時間内であっても信号の保持を停止するリセット入力機構を延長回路に設け、
音声認識装置の動作、行動、制御完了後にマイコンからリセット信号を出力し、
リセット信号を入力された延長回路が一定時間待つことなくすぐに音声信号制御回路の電源を遮断することで、無駄な電源投入を避け、簡単に、かつ大幅に電源の消費電力の低減を図る電源制御機構を特長とする。
(もっと読む)
音響モデル生成装置、音響モデル生成方法、プログラム
【課題】識別対象となるデータに含まれる非音声区間に影響を受けずに男女識別を行うことができる音響モデル生成装置を提供する。
【解決手段】男性音声データと、女性音声データと、非音声データとを音響モデルの生成に用いる音響モデル生成装置100であって、音響モデルの生成に用いられるデータから特徴量を抽出する特徴量抽出部930と、男性音声データから抽出された特徴量から男性音声区間モデルを、女性音声データから抽出された特徴量から女性音声区間モデルを、非音声データから抽出された特徴量から非音声区間モデルを学習するモデル学習部940と、男性音声区間モデルと非音声区間モデルを統合して男声音響モデルを生成し、女性音声区間モデルと非音声区間モデルを統合して女声音響モデルを生成するモデル統合部150とを備える。
(もっと読む)
音響処理装置およびそのプログラム
【課題】受信した放送コンテンツ等の音声信号を元に、異相成分と同相成分の混合ゲインを適切に調整する音響処理装置およびそのプログラムを提供する。
【解決手段】背景音分離部は、入力音声信号に基づき、スピーチ音声信号と背景音信号とを推定し、入力音声信号を推定スピーチ音声信号と推定背景音信号とに分離する。音声区間判断部は、入力音声信号に基づき、または入力音声信号に関連する信号に基づき、音声区間であるか非音声区間であるかを判断し判断結果を出力する。混合比調整部は、音声区間判断部による判断結果が音声区間であるか非音声区間であるかに応じた方法で、信号の混合比を決定する。混合部は、入力音声信号と推定スピーチ音声信号と推定背景音信号との少なくともいずれかを、混合比調整部によって決定された混合比に基づいて混合し、出力音声信号として出力する。
(もっと読む)
対話装置
【課題】音声認識の認識結果を早期確定して逐次認識結果を出力することができるとともに、早期確定するフレームの間隔を短くした場合であっても、認識率の低下を抑制することができる対話装置を提供する。
【解決手段】対話装置1は、音声認識の認識区間を設定する認識区間設定手段20と、音声認識を行う音声認識手段30と、音声認識の認識結果の中に所定のキーフレーズが含まれる場合、これに対応した応答行動を決定する応答行動決定手段40と、決定された応答行動を実行する応答行動実行手段50と、を備え、認識区間設定手段20が、既に設定された認識区間の認識終了位置を、当該認識終了位置から所定の時間長だけ進んだ位置のフレームに繰り返し更新することで複数の認識区間を設定し、音声認識手段30が、認識終了位置の異なる複数の認識区間のそれぞれについて音声認識を行う。
(もっと読む)
音認識方法及び装置
【課題】雑音環境下における対象音の音区間を検出可能とする音認識方法及び装置の提供。
【解決手段】雑音環境下における周期定常性を持つ対象音の音区間を検出可能とする音認識方法であって、音入力手段によりアナログ音響信号を採取し、フレームによって構成されるデジタル波形信号に変換する第1ステップと、デジタル波形信号をフレーム単位で解析して自己相関関数及び2次自己相関関数を算出する第2ステップと、各フレームについて算出した2次自己相関関数の差分絶対値の和が予め設定した閾値を超える範囲を音区間と判定する第3ステップと、を有することを特徴とする音認識方法およびその装置。
(もっと読む)
入力された発話の関連性を判定するための装置および方法
【課題】オーディオまたはビジュアルの向きを用いて入力された発話の関連性を判定する。
【解決手段】ある時間間隔における発話中のユーザの顔の存在を特定する。時間間隔の間のユーザの顔に関連づけられた顔の向きの特徴を取得する。ある場合には、入力された音に対する向きの特徴を判定する。顔の向きの特徴にもとづいて時間間隔の間のユーザの発話の関連性を特徴付ける。
(もっと読む)
音声区間判定装置、音声区間判定方法、及びプログラム
【課題】入力信号の音声区間と非音声区間との判定精度を向上する。
【解決手段】音声区間判定装置100は、入力信号をフレーム単位に分割するフレーム分割部101と、上記フレーム分割部により分割されたフレームについて分析長毎のパワースペクトルを算出するパワースペクトル算出部102と、上記パワースペクトル算出部により算出されたパワースペクトルの強度を増加させるパワースペクトル操作部103と、上記パワースペクトル操作部により強度が増加されたパワースペクトルを用いてスペクトルエントロピーを算出するスペクトルエントロピー算出部104と、上記スペクトルエントロピー算出部により算出されたスペクトルエントロピーの値に基づいて、上記入力信号が音声区間であるか否かを判定する判定部105と、を有する。
(もっと読む)
子音区間検出装置および子音区間検出方法
【課題】比較的高いノイズレベルの環境下においても精度よく子音区間を検出する。
【解決手段】子音区間検出装置110は、入力信号を予め定められたフレーム単位で切り出し、フレーム化入力信号を生成するフレーム化部120と、フレーム化入力信号を、時間領域から周波数領域に変換して、スペクトルパターンを生成するスペクトル生成部122と、スペクトルパターンにおける、連接する予め定められた帯域幅毎の平均エネルギーである帯域別平均エネルギーを導出する平均導出部126と、導出された帯域別平均エネルギー同士を比較し、第1の周波数帯域の帯域別平均エネルギーが、第1の周波数帯域より低い周波数帯域である第2の周波数帯域の帯域別エネルギーより高いことを検出することによりフレーム化入力信号に子音が含まれるかどうかを判定する子音判定部128とを備える。
(もっと読む)
発話抽出プログラム、発話抽出方法、発話抽出装置
【課題】対話時の発話から特定の発話を抽出する発話抽出プログラム、発話抽出方法、発話抽出装置を提供する。
【解決手段】第1の話者および第2の話者の発話区間を抽出して、日時または経過時間に関連付けて記録させる処理と、特徴操作記憶部を参照して、対話中に機器を第1の話者が操作した機器の状態を、日時または経過時間に関連付けて記録した操作情報から、特徴操作テーブルに合致する操作情報を抽出し、抽出した操作情報の発生した日時または経過時間を示す特徴操作時刻情報を取得させる処理と、発話抽出条件を参照して、発話抽出条件に合致する区間を、第1の話者および第2の話者の抽出した発話区間と抽出した特徴操作時刻情報を用いて抽出し、抽出した合致する区間から発話抽出条件に関連付けられている時間範囲に存在する第1の話者の発話区間に対応する発話を抽出させる処理と、をコンピュータに実行させる発話抽出プログラム。
(もっと読む)
音声判定装置および音声判定方法
【課題】ノイズレベルに拘らず、入力信号の音声区間を検出する。
【解決手段】音声判定装置100は、入力信号をフレーム単位で切り出し、フレーム化入力信号を生成するフレーム化部120と、フレーム化入力信号を変換して、周波数毎のスペクトルを集めたスペクトルパターンを生成するスペクトル生成部122と、スペクトルパターンの各スペクトルのエネルギーと、分割周波数帯域のうちスペクトルが含まれる分割周波数帯域における帯域別エネルギーとのエネルギー比が第1閾値を超えるか否かを判定するピーク検出部132と、判定結果に基づいて、フレーム化入力信号が音声であるか否かを判定する音声判定部134と、スペクトルパターンの各分割周波数帯域におけるスペクトルの周波数方向の平均エネルギーを導出する周波数平均部126と、分割周波数帯域毎に、平均エネルギーの時間方向の平均である帯域別エネルギーを導出する時間平均部130とを備える。
(もっと読む)
音声認識装置、ピッキング用の音声認識装置及び音声認識方法
【構成】
単語辞書の記憶部と、音声認識部と、発話者に対する音声出力もしくは画像出力を制御するためのインターフェースと、前記音声認識部と前記インターフェースとを制御する制御部とを備えた音声認識装置により、発話者の発話音声を認識する。単語辞書は数字を含む単語を記憶し、音声認識部により、発話区間の長さを認識すると共に、発話音声を認識し、音声認識部が発話音声の全体を認識できず、かつ発話区間の長さが閾値以上の際に、インターフェースを介して、発話者に複数の単語に区切って発話することを指示する。
【効果】 短い単語のみの辞書を備えた音声認識装置に、複数の短い単語が区切られずに入力された際に、発話者に単語を区切って再発話するように誘導できる。
(もっと読む)
音声に含まれる吸気音を検出する装置、方法、及びプログラム
【課題】音声信号における吸気音を、高い検出率で、かつ、精度よく検出することのできる技術を提供する。
【解決手段】吸気音検出装置は、吸気音及び非吸気音の各音響モデルを参照して吸気音候補を決定し、吸気音候補単体の情報である単体情報とコンテキスト情報とを要素とする特徴ベクトルを生成する。コンテキスト情報は、吸気音候補と該吸気音候補を含む発話区間との関係、吸気音候補と該吸気音候補の前後の吸気音候補との関係又はその両方に関する情報である。吸気音検出装置は、特徴ベクトルを入力として機械学習することにより、吸気音候補を吸気音と非吸気音とのいずれか一方に分類するための分類基準情報を求め、該分類基準情報に基づき、吸気音候補を吸気音と非吸気音のいずれか一方に分類する。
(もっと読む)
情報処理装置、情報処理方法、およびプログラム
【課題】動画像上の被写体が動作区間を精度よく速やかに判別する。
【解決手段】本実施の形態においては、順次入力される各フレームの唇画像に順次注目し、注目した唇画像tを基準として、その前後それぞれのNフレームから成る合計2N+1枚の唇画像を所定の位置に配置して1枚の合成画像を生成する。この生成された1枚の合成画像に対して、ピクセル差分特徴量が演算される。本発明は、例えば、動画像の被写体である人物の発話区間を精度よく検出する場合に適用することができる。
(もっと読む)
音声認識装置
【課題】音声入力時の操作性に優れた音声認識装置を提供する。
【解決手段】音声を記録する音声記録手段16と、音声に基づいて音声認識処理を行う音声認識手段33と、入力の開始または入力の終了を検出する入力手段14と、入力手段14が入力の開始を検出した場合に音声の記録を開始し、入力手段14が入力の開始を検出した後所定時間以内に入力の終了を検出した場合、その後再度入力の開始を検出した場合に音声の記録を終了させる第1の集音モードに制御し、入力手段14が入力の開始を検出したまま所定時間経過した場合、入力の終了を検出した場合に音声の記録を終了させる第2の集音モードに制御する集音モード制御手段30とを備えた。
(もっと読む)
音声データ区分方法、音声データ区分装置、及びプログラム
【課題】音声データを自動的に音声素片ごとに精度よく区分する。
【解決手段】音声データが表す音声を構成する各音声素片の境界時間の推定値である素片境界によって区分された各区分時間区間をそれぞれ1以上の状態境界で区分した複数の状態時間区間を求め、隣接する2つの区分時間区間からなる処理時間区間ごとに、当該処理時間区間に含まれる隣接した状態時間区間からなる組の集合の中から、当該組をなす隣接した状態時間区間それぞれの音声データの代表値の距離が最大となる組を選択し、選択した当該組をなす隣接した状態時間区間の状態境界又は素片境界を、当該処理時間区間での修正された素片境界とする。
(もっと読む)
2つのスイッチオフ規準を持つ音声検出装置
【課題】十分に良好な信号対雑音比を有する音声信号を検出すると共に、音声タイムスロットを決定する。
【解決手段】受信信号のエネルギ量が第1エネルギ閾値を越える場合に第1検出情報を送出するスイッチオン閾検出器11と、受信信号のエネルギ量が第1エネルギ閾値より小さな第2エネルギ閾値に満たない場合に第2検出情報を送出するスイッチオフ閾検出器12と、第1スイッチオフ期間の間に第2検出情報が入力された場合に音声タイムスロットを特徴付ける音声検出情報の生成を終了させる情報処理手段13とを含む。該情報処理手段は、第2スイッチオフ期間の間第1検出情報が入力されなかった場合、及び/又は第3スイッチオフ期間の間第1検出情報が入力されなかった場合にも音声検出情報の送出を追加的に終了させるように構成され、第3スイッチオフ期間の開始は第1検出情報が入力されなくなった後に第2検出情報が最初に入力される時として決定される。
(もっと読む)
音声分類装置、音声分類方法、及び音声分類用プログラム
【課題】分類の個数を事前に指定しなくても、音声を分類することができ、得られた分類結果の音声の種類を判別できるようにする。
【解決手段】本発明による音声分類装置は、複数の音声区間に分割された音声データを逐次的にクラスタリングして、クラスタリング結果をクラスタ情報として算出する逐次クラスタリング手段と、前記音声データ中の音声区間がいずれのクラスタラベルに対応するかを判別するための情報であるクラスタラベル判別情報を算出するクラスタラベル判別情報算出手段と、前記逐次クラスタリング手段が算出した前記クラスタ情報と、前記クラスタラベル判別情報算出手段が算出した前記クラスタラベル判別情報とを用いて、前記音声データ中の音声区間がいずれのクラスタラベルに対応するかを判別するクラスタラベル判別手段と、を備えたことを特徴とする。
(もっと読む)
発話認識装置、発話認識方法
【課題】精度良く発話区間の検出を行い、発話認識を行える発話認識装置、発話認識方法を提供することを課題としている。
【解決手段】音響を集音する音響集音部と、映像を撮像する映像撮像部と、集音された音響信号に基づき音響情報の特徴量を抽出する音響特徴量抽出部と、撮像された画像情報に基づき顔領域の特徴量と唇領域の特徴量を抽出する唇特徴量抽出部と、抽出された唇領域の特徴量に基づき唇の横方向の長さに関する視覚特徴量を抽出し、抽出された所定区間の視覚特徴量に対して3次以上の関数により時間軸方向にフィッティングして平滑化することで視覚特徴量を生成する視覚特徴量生成部と、生成された視覚特徴量と抽出された音響情報の特徴量とを統合して算出した発話確率に基づき発話区間を検出する発話区間検出部と、発話区間検出部が検出した発話区間の発話を認識する音声認識部とを備える。
(もっと読む)
1 - 20 / 144
[ Back to top ]