
Fターム[5D015JJ01]の内容
音声認識 (5,191) | パターン照合によらない認識 (78) | 母音の識別 (11)
Fターム[5D015JJ01]に分類される特許
1 - 11 / 11
分析装置、分析プログラムおよび分析方法
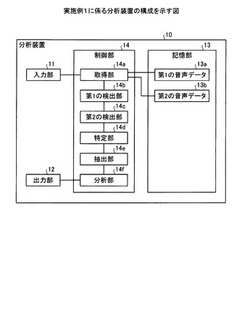
【課題】より簡易に会話スタイルを分析すること。
【解決手段】分析装置10は、取得部14aと、第1の検出部14bと、第2の検出部14cと、抽出部14eと、分析部14fとを有する。取得部14aは、音声データを取得する。第1の検出部14bは、取得された音声データから、第1の確率モデルを用いて、有声音領域および無声音領域を検出する。第2の検出部14cは、検出された有声音領域および無声音領域に基づいて、第2の確率モデルを用いて、音声データにおける発話領域および沈黙領域を検出する。抽出部14eは、検出された発話領域および沈黙領域の会話特性を抽出する。分析部14fは、抽出された会話特性に基づいて、会話スタイルを分析する。
(もっと読む)
音声変更装置、音声変更方法および音声情報秘話システム

【課題】騒音レベルの増長を抑えた上で音声の内容を隠蔽する。
【解決手段】音声情報秘話システムは、ブース2にいる顧客6の発話音声を受け、それを表す音声信号を生成するマイクロホンMicと、マイクロホンMicによって生成された音声信号を変更するSDコントローラ部SDと、SDコントローラ部SDによって変更された音声信号を音声に変換して発話音声が受聴されうる隣接ブース2’に出力するスピーカSPと、を有する。SDコントローラ部SDは、マイクロホンMicによって生成された音声信号から子音部分を抽出する部分抽出部と、その子音部分を置換もしくは時間反転する部分変更部と、そのように子音部分が置換もしくは反転された音声信号をスピーカSPに出力する出力部と、を含む。
(もっと読む)
番組画像配信システム、番組画像配信方法及びプログラム
【目的】例えば撮影現場の出演者とキャラクタが会話をしている画像をリアルタイムに生成することを可能にする番組画像生成システム51等を提供する。
【構成】同じ音声入力端末57の音声入力部59に入力された音声に基づいて、遠隔再生処理装置531及び532では、入力された音声と背景音声データを同期して再生し、さらに、それぞれ異なるキャラクタ要素画像に基づいて生成されたキャラクタ画像と実写データと合成して表示することにより、音声という容易に入力可能な情報を用いて、共通の音声を、複数の場所に、その場に合った番組(コンテンツ)として配信することが可能になる。そのため、リアルタイムなコンテンツ演出と、消費者参加型のコンテンツ作成が可能になり、市場の活性化を図ることができる。さらに、遠隔操作やリアルタイム配信により、イベントや緊急配信に運用することもできる。これにより、注目度・話題性・認知度・臨場感等が向上する。
(もっと読む)
音声認識装置、音響モデル学習装置、音声認識方法、および、プログラム
【課題】隠れマルコフモデルを用いる音声認識を高精度に行う。
【解決手段】特徴量抽出手段111は、入力音声にフレームを割り当て、各フレーム毎の特徴量を抽出する。累積尤度算出手段113は、隠れマルコフモデルを用いて、各フレーム毎における状態毎の累積尤度を算出する。このとき、子音を示すフレームについては通常の尤度演算を行うが、母音を示すフレームにおいては、類似したモデルを集めたグループ毎に尤度演算を行う。そして、最大の累積尤度を与えるグループが定まった後は、そのグループについてだけ尤度演算を行うことに決定する。これにより、話者の個人差の少ない子音と、個人差の多い母音とに分け、母音についてだけ個人差を考慮した認識ができ、その結果、音声認識処理の高精度化が図られる。
(もっと読む)
音声認識装置及びそれを搭載した輸送機器
【課題】単語辞書の作成に事前調査を必要としない音声認識装置を提供する。
【解決手段】音声認識装置10は、音響信号の中から音声信号を含む発話区間を検出する発話区間検出部11と、発話区間検出部11により検出された発話区間内の音声信号を分析することにより、その音声信号から音響特徴量を抽出する特徴量抽出部12と、複数種類の単語がモーラ数でソートされて登録されている単語辞書13と、単語辞書13に登録された単語の音響特徴量が登録されている音響モデル14と、単語辞書13及び音響モデル14を参照し、特徴量抽出部12により抽出された音響特徴量を単語辞書13に登録された各単語の音響特徴量と照合することにより各単語の尤度を算出し、最尤度の単語を認識結果とする照合部15とを備える。
(もっと読む)
音声制御装置
【課題】 音声の特徴自体によって直接的に制御を行うことを可能とした音声制御装置を提供する。
【手段】 音声取得部2は、音声を取得し電気信号に変換する。特徴量算出手段4は、音声電気信号を周波数解析し、特徴量を算出する。母音判定手段6は、算出した特徴量に基づいて、予め登録された母音との類似度に基づいて母音の判定を行う。制御手段8は、各母音を異なる方向に対応づけた平面または空間において、母音判定手段6によって判定された母音に対応する方向に、その類似度に対応する大きさのベクトルを想定する。制御手段8は、このようにして想定したベクトルに基づいて制御信号を出力する。このようにして、音声に基づいた制御を行うことができる。
(もっと読む)
音声合成装置、方法及びプログラム
【課題】 無声音声と口唇画像とから有音音声を合成する際に、発話者が意図する抑揚を合成音声に反映させる。
【解決手段】 本発明は、発話者の無声音声と撮像口唇画像とが同期して入力され、有音音声を合成する音声合成装置に関する。映像信号分析手段は、入力口唇画像から有声音の母音情報を抽出し、母音発声時の口唇の開閉大きさと、予め設定した基準大きさとの比率をピッチ比率として抽出する。音声信号分析手段は、入力無声音声と、映像信号分析手段が抽出した母音に対応する無声母音の音響モデルとから、子音情報を抽出し、音素列と単語を対応付けた内蔵する辞書と、どの単語の並びであるかを計算する言語モデルとから、テキスト情報を抽出し、入力無声音声のパワー変化から発声全体の継続時間長を抽出する。音声合成手段は、上述の両分析手段によって抽出された各種情報から、抑揚を付与した有音音声を合成する。
(もっと読む)
筋電位信号による音声認識装置
【課題】 サポートベクターマシンを用いて識別性を向上させた筋電位信号による音声認識装置を提供する。
【課題を解決するための手段】 音声認識装置は、口唇周辺の複数箇所の筋電位信号を検出する信号計測部と、前記信号計測部から検出された筋電位信号から特徴情報を抽出する特徴抽出部と、前記特徴抽出部から抽出された特徴情報により訓練データを生成する訓練データ生成部と、前記訓練データ生成部により生成された訓練データに基づいてサポートベクトルマシンを構成するサポートベクトルマシン学習部と、前記サポートベクトルマシン学習部により構成されたサポートベクトルマシンによるデータ処理により前記特徴情報から母音音声を識別する音声識別部とを備える。
(もっと読む)
音声合成装置
【課題】 合成音の質を向上させることができる音声合成装置を提供する。
【解決手段】 音声合成装置1は、入力音声信号をフィルタリング処理し、線形予測残差信号を得る分析フィルタ2と、線形予測残差の自己相関関数(残差相関関数)の波形信号を分析する音源特性分析器3と、残差相関関数の雑音比に基づいて母音波形であるかどうかを判断する母音検出部4と、母音波形の極の尖頭度や母音波形におけるフレーム区間内のゼロクロス数から、母音波形の母音種を特定する母音種抽出部5と、母音種に応じた周期パターンを発生させる周期信号発生器9及び雑音パターンを発生させる雑音信号発生器10とを有する音源部6と、雑音パターンをフィルタリング処理する合成フィルタ7と、合成フィルタ7をバイパスした周期パターンと合成フィルタ7を通過した雑音パターンとを合成して、合成音を生成する音声合成部8とを備えている。
(もっと読む)
リップシンクアニメーション作成装置、コンピュータプログラム及び顔モデル生成装置
【課題】滑らかで自然なアニメーションが得られるようキーフレームとブレンド率を自動的に設定するアニメーション作成装置を提供する。
【解決手段】装置200は、音響モデル170、マッピング定義176、トランスクリプション154を使用し、発話データ152から視覚素を求め、デフォルトのブレンド率を付与して視覚素シーケンス180を作成する視覚素シーケンス作成部230と、視覚素シーケンス180内に定義されるキーフレームからなるキーフレームシーケンス内で、隣接するキーフレームとの間で、顔モデルの変化が最も速いものから順番に、キーフレームを削除するキーフレーム削除部236と、キーフレーム内の発話パワーが小さいときにブレンド率を小さくする調整部244と、画像の変化が速いときにブレンド率を小さくする調整部250と、キーフレーム間のブレンドにより顔画像のアニメーションを作成するブレンド処理部256とを含む。
(もっと読む)
音声信号判別装置、音質調整装置、放送受信機、プログラム、及び記録媒体
【課題】入力された音声信号に対して的確にスピーチ/非スピーチを判別することが可能な音声信号判別装置を提供する。
【解決手段】音声信号判別装置において、入力された音声信号がスピーチに対応するものか、非スピーチに対応するものかを判別するための判定を行うスピーチ/非スピーチ判定手段12と、入力された音声信号が、モノラル信号又はステレオ信号のいずれであるかを判定するモノラル/ステレオ判定手段13と、モノラル/ステレオ判定手段13での判定結果に基づいて、スピーチ/非スピーチ判定手段12における判定基準を最適化する基準最適化手段14とを有する。
(もっと読む)
1 - 11 / 11
[ Back to top ]