
ドルビー・ラボラトリーズ・ライセンシング・コーポレーションにより出願された特許
101 - 110 / 111
調整可能なフリーランニングの固定時計
累積した修正値が予測されるクロックドリフトの値を越えない限りユーザにより修正可能なコンピュータ装置内のフリーランニングの固定時計である。該時計は、最初にユーザ又は信頼できる時刻配信事業者などにより設定される。この時計は、その時計により時間的要件を測定する信頼に基づくシステムにおいて必要とされよう。  (もっと読む)
(もっと読む)
ツリー状階層データ構造を順に横断してゆくことによりビットストリームシンタックスを記述するオーディオビットストリームフォーマット
ツリー状階層データ構造を順に横断してゆくことによりビットストリームシンタックスを記述するオーディオ情報を表示するビットストリームフォーマットは、それぞれが1以上のノードを持つ複数のツリー状階層レベルからなるツリー状階層を有し、ノードには、少なくともいくつかの徐々に小さくなるオーディオ情報のサブディビジョンが徐々にツリー状階層の低いレベルにおいて表示され、前記オーディオ情報は前記1以上のレベルにおけるノードに含まれる。  (もっと読む)
(もっと読む)
知覚コーディングのビット割り当てにおける複雑さを軽減した計算方法
知覚コーディングシステムにおけるスペクトル成分を量子化するためのビット割り当てプロセスを、ビット割り当てプロセスにおいて用いられる1以上のコーディングパラメータに対して最適な値を正確な推定値を取得することにより効率的に実行する。知覚オーディオコーディングシステムにおける1実施の形態において、音響心理学的マスキングカーブからのオフセットの正確な推定値が、コーディングに用いられていたオフセットに対する初期値を選択することにより導き出され、この計算された数値と実際の割り当てに有用なビット数との差からオフセットの最適値を推定する。  (もっと読む)
(もっと読む)
マルチチャンネルオーディオコーディング
オーディオの複数のチャンネルは、結合されて、モノフォニックコンポジット信号又は、オーディオの複数のチャンネルを復元させる関連する補助情報が加えられた複数のチャンネルになり、これには、複数のオーディオチャンネルからモノフォニックオーディオ信号又は複数のオーディオチャンネルにダウンミキシングする改良された技法と、モノフォニックオーディオチャンネル又は複数のオーディオチャンネルから導き出した複数のオーディオチャンネルをデコリレートする改良された技法とが含まれている。開示する発明は、オーディオエンコーダ、デコーダ、エンコーディング/デコーディングシステム、ダウンミキサー、及びデコリレータに有用である。  (もっと読む)
(もっと読む)
信号解析及び合成のための適応型混合変換
オーディオ及びビデオコーディングシステム等に用いられる各解析及び合成フィルタバンクは、一次変換とそれにカスケードする1つ以上の二次変換を含むハブリッド変換により実行される。フィルタバンクの一次変換は時間領域エイリアシングアーチファクトをキャンセルする解析/合成システムを実行する。一次変換にカスケードする二次変換は変換係数のブロックに適用される。ブロック長は、析及び合成フィルタバンクの時間分解能を適合させるように変換される。  (もっと読む)
(もっと読む)
MDCT係数から導かれた推定スペクトル強度と位相を使用する改良型コーディングテクニック
スペクトルの強度と位相の推定は、修正型離散コサイン変換などの解析フィルタバンクからのスペクトル情報を使用する推定プロセスによって得られる。推定プロセスはインパルス応答に対する畳込みのような演算で実行される。インパルス応答の部分は、計算量と推定精度をトレードオフする畳込みのような演算での使用のために選択される。フィルタ構造とインパルス応答に関する解析式の数学的誘導を開示する。  (もっと読む)
(もっと読む)
ブロック系列化に基づくオーディオコーディング

オーディオ情報のブロックはグループ内に配列され、これはエンコーディング制御パラメータをを共有して、エンコード化信号における制御パラメータを伝送するのに必要な側情報量を低減させる。エンコード化オーディオ情報の歪を低減する系列化形態は、最適解又は近似的最適解を検索する幾つかの手法の何れかにより決定される。その手法は全数検索、高速最適検索、及びGreed Merge法を含み、検索技法にエンコード化信号のビットレート及び/又は検索技術の計算の複雑さに対する歪の低減を相殺させることを可能とする。 (もっと読む)
クロスフェードを容易にするために重複させたフレームベースオーディオの伝送/記憶方法
先行する隣のフレーム又は後続する隣のフレームのどちらかの一部を各フレームに付加することにより修正されたフレームからPCMオーディオフレームを接合する方法である。第1の形態によれば、接合点のみにおいてフレームの端部とフレームの付加部分にフェードアップとフェードダウンを行い、重複して結合することで接合を行って接合点でのクロスフェードを提供する。あるいは、すべてのフレームの端部とフレームの付加部分にフェードアップとフェードダウンを行い、重複して結合する。相補的ェードアップとフェードダウンを提供することにより丸め誤差が削減される。  (もっと読む)
(もっと読む)
オーディオ信号処理システム及び方法
複数のオーディオ入力信号(15〜19)を処理する方法、装置、及びソフトウェア製品である。この装置は複数の入力信号(15〜19)を受け取り、リスナーがリスニング環境でおそらく聞くであろう反響をシミュレートする遅延反響成分を含む1組の複数の入力・複数出力反響装置(14)出力信号(35〜39)を生成する。この装置には、前記反響装置の出力を受け取る複数入力・2出力フィルター(20〜24)と複数の入力端子が含まれ、左右の耳に対する出力を提供し、リスニング環境に対応する1組の頭部伝達関数とこのリスニング環境でリスナーに方向性を与えることを実行するよう構成される。この装置は、ヘッドフォンを通した出力(47〜48)を聞いているリスナーに、対応する複数の方向に前記リスニング環境に空間的広がりを持って置かれた複数のラウドスピーカからでてきている複数のオーディオ入力信号を聞いているようかのような感覚を持たせる。 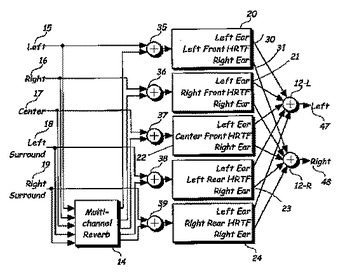 (もっと読む)
(もっと読む)
オーディオ信号の感知音量を計算し調整する方法、装置及びコンピュータプログラム

2以上の前記特定音量モデル関数のグループから選択された1つの特定音量モデル又は2以上の特定音量モデルの1つの組み合わせがオーディオ信号の感知音量の計算に用いられる。この関数は、例えば、オーディオ信号が狭帯域なのか広帯域なのかの程度を示す指標により選択される。あるいは、関数のグループからのこのような選択と共に、ゲイン値G[t]が計算され、オーディオ信号にこのゲインが適用されると、参照音量と実質的に同じ感知音量となる。ゲインの計算は、感知音量の計算を含む反復的処理ループを用いる。 (もっと読む)
101 - 110 / 111
[ Back to top ]