
Fターム[5B042KK07]の内容
デバッグ、監視 (27,428) | 異常、誤り検出時の処理 (2,313) | 内部状態の保存、凍結 (244) | ログアウト (205)
Fターム[5B042KK07]の下位に属するFターム
メモリダンプ (73)
Fターム[5B042KK07]に分類される特許
1 - 20 / 132
コンピュータ、コンピュータシステム、および障害情報管理方法
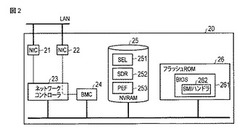
【課題】システム管理コントローラが障害の情報を管理することができない場合であっても、障害の情報を管理すること。
【解決手段】実施形態によれば、ネットワークを介して管理用コンピュータに接続されたコンピュータであって、記憶部と、前記コンピュータにハードウェア障害が発生した場合に前記ハードウェア障害の内容を示す障害情報を生成する生成手段と、前記障害情報が生成された場合に第1の指示信号を発行する発行手段と、前記発行手段からの前記第1の指示信号の受信に応じて前記障害情報を前記記憶部に格納するシステム管理コントローラと、前記障害情報の前記記憶部への格納に失敗した場合に前記障害情報を前記管理用コンピュータに送信する送信手段とを具備する。
(もっと読む)
マルチコアプロセッサのすべてのプロセッサコアの実行トレースダンプが可能なSOCデバイス

【課題】高価な外部ICEなしでターゲット端末のデバッグとトレースダンプが可能になるマルチコアプロセッサ及びデバッグ方法を提供する。
【解決手段】デバッグコントロールユニットを内蔵したターゲットマルチコアプロセッサSOCにおけるEJTAGデバッグ機能、すなわち、プログラム停止・再開、レジスタダンプ、メモリダンプなどと全てのプロセッサのトレースダンプ機能をFIFOで構成し、ターゲットに内蔵のUSBデバイスコントローラのオプションデバイスとして実装する。
(もっと読む)
車載電子制御装置、診断ツールおよび診断システム
【課題】所定の車両挙動が発生すると、そのときの車両走行情報に基づいて所定の車両挙動が発生した原因を適切に解析可能とする車載電子制御装置、診断ツールおよび診断システムを提供する。
【解決手段】電子制御装置は、アクセルを踏んでいないのにスロットル開度が大きく開いている等の所定の車両挙動が発生している場合(S400:Yes)、そのときの車両走行情報と、時刻と、車両走行情報を記憶したことを表わす記憶実行情報とを挙動情報として記憶する(S402)。エンジンが停止すると(S404:Yes)、電子制御装置は、挙動情報の記憶実行情報から車両走行情報が記憶されていると判定すると(S406:Yes)、CPUの作動に対する異常判定を実行し(S408)、異常判定結果と、異常判定の実行時刻と、異常判定を実行したことを表わす判定実行情報とを異常判定情報として記憶し(S410)、CPUへの電力供給を遮断する(S412)。
(もっと読む)
監視システム
【課題】監視対象装置のメモリ容量の増大と保守性の低下を解決すること。
【解決手段】本発明である監視システムは、監視対象装置にて実行される処理状態を表す統計ログを所定の時間間隔にて採取する統計ログ採取手段と、監視対象装置から出力された当該監視対象装置の状態を表すイベントログを採取してバッファメモリに蓄積するイベントログ採取手段と、取得した統計ログが予め設定された異常状態であるか否かを判断する統計ログ解析手段と、統計ログ解析手段の判断により統計ログが異常状態となったときに、統計ログを採取する時間間隔が短くなるよう統計ログ採取手段に変更設定するログ採取間隔変更手段と、を備え、上記イベントログ採取手段は、上記統計ログ解析手段の判断により統計ログが異常状態となったときに、バッファメモリに蓄積した現時点以前のイベントログの少なくとも一部を所定の記憶装置に記憶する、という構成をとる。
(もっと読む)
情報処理システム及び情報処理方法
【課題】本発明は、情報処理システム及び情報処理方法に係り、統合装置内での異常時に外部装置が行う退避処理を必要最小限に抑えることにある。
【解決手段】統合装置内の各内部装置に、他の内部装置とは異なる条件で異常判定を行わせると共に、異常判定時に共通処理部に対してハードウェア資源(HW)のフェールセーフ(FS)要求を通知させる。共通処理部に、内部装置からのFS要求の通知を受けた場合に、他の内部装置に対してHWのFS動作を事前に通知させる。内部装置に、共通処理部からの事前通知を受けた場合に、共通処理部に対してHWのFS動作許可を通知させると共に、協調処理を行う外部装置に対して、HWのFS動作及び異常が自内部装置と他の内部装置との何れに起因するのかを通知させる。また、共通処理部に、内部装置からのFS要求の通知を受けかつFS動作許可の通知を受けた場合に、HWをFS動作させる。
(もっと読む)
障害解析情報収集装置
【課題】主記憶装置やHDD装置に一時的に不具合、誤動作が発生した場合においても、再起動後に障害情報を可能な限り収集することができる障害解析情報収集装置を得ることを目的とする。
【解決手段】障害解析情報収集装置100は、主記憶装置5と、バックアップメモリ2と、HDD6とを有し、
障害発生時に、主記憶装置5に記録されている主記憶情報を、ダンプファイル13としてHDD6に設けた主記憶情報記録領域に保存する主記憶情報記録手段9と、CPUレジスタ3やI/Oレジスタ4の値をバックアップメモリ2に設けたH/W情報記録領域12に保存するハードウェア情報管理手段8と、障害発生後に装置100を再起動した後で、保存されている主記憶情報及びハードウェア情報を結合して解析ファイル14としてHDD6に保存する障害情報管理手段11とを備える。
(もっと読む)
電子制御装置
【課題】ソフトウェアの処理負荷が所定負荷を超えた場合に、処理負荷の異常原因を解析できる電子制御装置を提供する。
【解決手段】タスクの起床元では、起床対象のタスクを起床すると(S420)、起床対象のタスクからリターンされる起床結果に基づいて起床が成功したか否かを判定し(S422)、起床に失敗すると(S422:No)、連続失敗回数カウンタを+1する(S424)。起床されたタスクは、起床元のタスクでカウントした連続失敗回数カウンタの値を今回値として記憶し(S430)、連続失敗回数カウンタをクリアし(S432)、今回の起床までにおける連続失敗回数の最大値を算出する(S434)。起床されたタスクは、連続失敗回数がソフトウェアの設計時に設定した許容範囲を超えている場合(S436:No)、ソフトウェアの処理負荷異常と判定し、判定結果と処理負荷異常時の車両走行情報とを記憶する(S438、S440)。
(もっと読む)
機器管理システム
【課題】管理対象とする機器に発生した障害に対する対処の緊急度を判定することのできるシステムを提供する。
【解決手段】機器管理システム1は、機器に発生した障害に対応する障害メッセージを所定の装置へ送信する管理対象機器3と、障害メッセージの重要度とシステム情報を管理対象機器3毎に記憶した機器データベースが設けられ、管理対象機器3から障害メッセージを受信すると、機器データベースを参照し、管理対象機器3が送信した障害メッセージ及び障害が発生したコンポーネントの重要度に基づき、管理対象機器3が送信した障害メッセージに対する対処の緊急度を判定する緊急度判定手段を備えた機器管理装置2とから少なくとも構成される。
(もっと読む)
共用リソース管理システム及びリソース管理サーバ装置
【課題】共用リソースを配備する情報処理センタの可用性を向上させる。
【解決手段】構成カタログ140には、リソースを構成要素とするシステムの構成が掲載されている。センタ管理者は適当な入力手段によりその内容を更新することができる。機能モジュール150は、サーバ(1000〜5000)を構成している各リソースの状態情報及び障害情報を機能モジュール120に通知する。機能モジュール150は、この状態情報及び障害情報を前記各サーバを構成している各リソースから得る。機能モジュール120は、機能モジュール150から通知された状態情報及び障害情報を収集し、データベース110に保存する。機能モジュール130は、前記状態情報及び障害情報を参照しながら前記リソースを組み替えて、構成カタログ140に要求されたシステムを構築するための計算を行うと共に結線も含めて該システムを構成するハードウェアの実装を行う。
(もっと読む)
情報処理装置、記録方法、及びプログラム
【課題】本発明が解決しようとする課題は、上記問題点を解決することであり、CPUの動作履歴記録用メモリーの容量を少量化することである。
【解決手段】上記課題を解決するための本発明は、記録装置であって、監視対象である情報処理装置のCPUの動作履歴が、ウォッチドッグタイマーのカウンター値がクリアされる周期に対応付けられて記録されている動作履歴記録部と、前記動作履歴を前記動作履歴記録部に記録し、前記クリア後に新たに前記CPUの動作を記録する際、前記CPUに障害が発生しなかった周期の動作履歴に上書きする記録手段とを有することを特徴とする。
(もっと読む)
クラスタシステム、データ記録方法、及びプログラム
【課題】共有ディスク上のログファイルへのデータ記録を適正に行うことにより現用サーバと予備サーバの切替え時にエラーが発生しないようにする。
【解決手段】クラスタシステムは、運用系のサーバ装置10aと待機系のサーバ装置10bが共有ディスク30を利用して動作を行うように構成されている。サーバ装置10aにおいてデータ転送機能を有するsyslogd11aが、クラスタサービス20のアプリケーション21のログメッセージをローカルディスク上の名前付きパイプ13aへ一時的に保存すると、ログアプリケーション14aが、名前付きパイプ13aに保存されたログメッセージを共有ディスク30上のログファイル31へ記録する。このとき、ログアプリケーション14aは、アプリケーション21のログメッセージが名前付きパイプ13aへ保存されるタイミングで、ログファイル31のオープン/書き込み/クローズの処理を行う。
(もっと読む)
ログ保存装置およびログ保存プログラム
【課題】ログデータの保存に過不足のない記憶領域を確保してログデータをメモリに保存することができるログ保存装置およびログ保存プログラムを提供する。
【解決手段】 ログデータの格納が指示されたときに、メモリ上にこのログデータを格納するログ領域を確保する確保部と、ログデータを、この確保されたログ領域に格納するログ格納部と、確保部で新たに確保されたログ領域よりも前に確保済のログ領域が存在する場合、新たに確保されたログ領域の場所を示す場所データを確保済みのログ領域と関連付けて格納する場所格納部とを備える。
(もっと読む)
障害解析支援システム、障害解析支援方法、および障害解析支援プログラム
【課題】Webシステムにおいて障害解析を適切に行なう。
【解決手段】障害解析支援システム401は、運用系システム201の負荷状況を監視するためのシステム監視部22と、1または複数のWebブラウザからのリクエストを監視するためのリクエスト監視部21と、リクエストによって呼び出されるAPIを監視するためのAPI呼び出し監視部23と、リクエストの処理が行われている際にWebアプリケーションで例外が発生するか否かを監視し、例外が発生した場合には、例外の内容を示す例外情報を生成し、生成した例外情報、および各監視結果をログファイルとして出力するための例外監視部24と、例外監視部24から受けたログファイルに基づいてスクリプトを生成するためのスクリプト生成部60と、スクリプト生成部60によって生成されたスクリプトに基づいて例外の発生を再現するための障害再現部80とを備える。
(もっと読む)
メモリエラーパターン記録システム、メモリモジュール、及びメモリエラーパターン記録方法
【課題】コントローラやメモリモジュールを交換してもメモリモジュールに発生したエラーを再現する。
【解決手段】メモリモジュール1が、メモリデバイス12−1〜12−Nと、メモリデバイス12−1〜12−Nへのアクセスパターンであってエラーが発生するアクセスパターンを記憶する不揮発性メモリ17と、コントローラ2によるメモリデバイス12−1〜12−Nへのアクセスによってエラーが発生したか否かを判定するエラー検出回路15と、エラー検出回路15によって、エラーが発生したと判定された場合、不揮発性メモリ17にコントローラ2によるアクセスパターンを記録するアクセス情報記録回路16とを備える。
(もっと読む)
情報処理装置および情報処理装置の時刻同期方法
【課題】メインシステムと保守管理システムにおける精度の高い時刻同期を行うことを可能にし、障害発生時にはメインシステムと保守管理システムで検出された障害の時刻関係が明確なログを採取する情報処理装置を提供する。
【解決手段】情報処理装置において、BMC118は、TIMERTC122を取得してメモリ121に保存し、TIMERTC122を保存した時におけるシステムバスクロックカウンタ回路115のCOUNTSTART123をメモリ121に保存し、メインシステム101側の障害発生時に、その障害発生時のシステムバスクロックカウンタ回路115のCOUNTOFFSET124をメモリ121に保存し、ソフト時計108の計時の刻みとシステムバスクロックカウンタ回路115のカウンタの計時の刻みとの比率、TIMERTC122、COUNTSTART123、およびCOUNTOFFSET124に基づいて、障害発生時のOS時刻を算出する。
(もっと読む)
計算機システム及び障害情報収集方法
【課題】障害の原因を特定するための有用な情報であるコアファイルを完全に保存し、コアファイルの保存処理が終了する前にプロセスの障害からの回復を可能とする。
【解決手段】プロセスに障害が発生したときにメモリ1050内にコアダンプ管理情報を格納する領域1020を作成し、コアダンプ管理情報を格納する領域にプロセスが使用するメモリ領域の位置情報を保持するメモリ管理情報位置情報1012を、コアファイル保存データ位置情報1022として記録し、プロセスの終了処理を行う障害時プロセス終了手段1100と、コアダンプ管理情報を格納する領域に記録されたコアファイル保存データ位置情報1022を参照しプロセスが使用するメモリ領域の情報の一部または全てを二次記憶装置1060にコアファイル1061として記録し、プロセスが使用するメモリ領域の情報及びコアダンプ管理情報を格納する領域及び領域内の情報を削除するコアファイル保存手段とを備える。
(もっと読む)
情報処理装置
【課題】情報処理装置において障害が発生した場合、その障害情報の自動的な収集と障害情報の保存の確実性を提供する。
【解決手段】情報処理装置8は、ソフトウェアを実行するCPU1と、ソフトウェアの動作を監視するウォッチドッグタイマ2と、ハードウェアの状態を監視するハードウェア監視デバイス4と、その監視結果を管理する障害情報管理用LSI3と、障害情報を保存する不揮発性メモリ6とを備える。ウォッチドッグタイマ2は、一定時間内にウォッチドッグトグルがない場合、CPU1に対してノンマスカブルの割り込み信号を通知して2回目のスタートを行う。CPU1は障害情報管理用LSI3から障害情報を収集する。収集が完了した場合はColdリセットを行って再起動し、収集が未完了の場合はHotリセットを行って再起動する。Hotリセットの場合、再起動後に障害情報を収集する。
(もっと読む)
クラスタシステム復旧方法、サーバ及びソフトウェア
【課題】予備機でサービス稼働中であり、現用機がクラスタ構成に組み込まれていない場合に、現用機でサービスを再開させることを目的とする。
【解決手段】現用機と予備機とで構成されるクラスタシステムが開示される。現用機の故障箇所推定手段は、現用機の故障ログ記憶手段に格納された故障ログから、現用機の故障箇所を推定する。現用機の導通確認手段は、現用機に接続されたルータまで導通を確認する。現用機のクラスタ構成手段は、現用機のクラスタ状態をサービス稼働中へ遷移できる状態へ遷移させる。次に、現用機の遷移抑止手段は、予備機のクラスタ状態をサービス稼働中への遷移が抑止されている状態へ遷移させる。次に、現用機の遷移抑止解除手段は、予備機のクラスタ状態をサービス稼働中へ遷移できる状態へ遷移させる。
(もっと読む)
画像処理装置
【課題】CPUによる制御下で装置の動作中に装置内に記憶された装置各部の状態を示す状態情報を、CPUの動作停止状態でも取得することができる画像処理装置を提供する。
【解決手段】複合機10は、メインCPU11とサブCPU12を備える。メインCPU11は、複合機10の各部の動作を制御すると共に、複合機10の動作中は、各部の動作履歴を示す動作ログデータなどを逐次生成し、不揮発メモリ15に記憶する。複合機10が管理者端末40からログ取得要求パケットを受信すると、サブCPU12は不揮発メモリ15からログデータを読み出して取得し、管理者端末40へ送信する。メインCPU11がハングアップして複合機10が異常停止した場合などでも、管理者端末40から複合機10へログ取得要求パケットを送信することで、複合機10内に記憶されているログデータを管理者端末40にて取得することができる。
(もっと読む)
電圧検出システム及びその制御方法
【課題】電源電圧の降下が急峻な場合、システムが誤作動を起こす可能性があった。
【解決手段】割込みモードと、リセットモードとを有する電圧検出システムの制御方法であって、第1、第2の検出レベルを設定し、電源電圧が前記第1の検出レベルより高い場合、ラッチ回路を第1の状態として、前記割込みモードに設定し、前記電源電圧が前記第1の検出レベル以下となった場合、割込み信号を生成し、前記ラッチ回路を前記第1の状態から第2の状態とすることで、前記リセットモードに設定し、前記リセットモード時に、前記電源電圧が前記第2の検出レベル以下となった場合、システムリセットする電圧検出システムの制御方法
(もっと読む)
1 - 20 / 132
[ Back to top ]