
Fターム[5B042LA23]の内容
デバッグ、監視 (27,428) | ブレークポイント条件、トリガ条件 (1,358) | モジュール切換時、タスクスイッチ時 (100)
Fターム[5B042LA23]の下位に属するFターム
サブルーチン呼び出し時 (48)
サブルーチン戻り時 (18)
Fターム[5B042LA23]に分類される特許
1 - 20 / 34
動的解析装置、動的解析システム、動的解析方法、及びプログラム
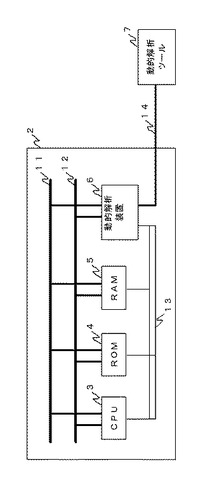
【課題】簡便に正確に制御装置等の動作を解析可能とする。
【解決手段】動的解析装置6は、解析対象のCPU3が接続される、アドレスバス11、データバス12、制御信号線13に接続される。動的解析装置6は、アドレスバス11上のアドレスの値から処理内容、例えば、実行中の関数や変数を特定し、データバス12上のデータから処理データ、例えば、変数の値を特定するデータ解析部と、データ解析部により解析された処理内容と処理データの履歴を含む履歴情報を記憶する記憶部と、動的解析ツール7からのアクセスに応答して、記憶部に記憶した履歴情報を提供する履歴情報提供手段と、を備える。
(もっと読む)
制御装置及び制御方法

【課題】プロセッサにかかる負荷を低減することができる制御装置及び制御方法を提供すること。
【解決手段】本発明にかかる制御装置は、ユーザモード及びカーネルモードのうち、カーネルモードでアクセス可能である制御対象を制御する制御タスクをユーザモードで実行するオペレーティングシステム100と、オペレーティングシステム100を実行するプロセッサ10と、を備えた制御装置である。オペレーティングシステム100は、制御タスクを実行していない期間に、カーネルモードで、制御対象から情報を取得して、取得した情報に基づいて制御対象の異常を検出する異常検出処理を実行する。
(もっと読む)
プログラム群
【課題】ブートプログラムから基本プログラムに切り替わる時に、規定されたウォッチドッグ信号を確実に供給できるようにする。
【解決手段】ブート処理が実行されている間は、WDカウント値がWD閾値THw1に達する(即ち、WD周期が経過する)毎にWD信号の信号レベルを反転させ、通常処理が実行されている間は、WDカウント値がWD閾値THw2に達する(即ち、WD周期が経過する)毎にWD信号の信号レベルを反転させている。ブート処理から通常処理に切り替わるタイミングでは、引継情報に基づいて、WDカウント値の初期値を、初期オフセット時間が経過するとWD閾値THw2に達するような値に設定する。
(もっと読む)
タイムスタンプを生成するための方法、装置およびトレースモジュール
【課題】効率的にタイムスタンプを生成することを目的とする。
【解決手段】本発明は、データ処理の分野に関し、特に、データ処理装置または処理のトレーシングの特徴がデータ処理装置によって実行されている間に、タイムスタンプを生成するための方法、装置1およびトレースモジュール12に関する。所定の事象が発生する場合、タイムスタンプリクエストが保留になっていることを示すように、タイムスタンプリクエストフラグ18が設定される。後続のトレースパケットの生成時において、タイムスタンプリクエストフラグは、タイムスタンプリクエストが保留になっていることを示すかどうかが判定され、リクエストが保留になっている場合には、後続のトレースパケットに対応するタイムスタンプが生成され、いかなる保留になっているタイムスタンプリクエストも存在しないことを示すために、タイムスタンプリクエストフラグが設定される。
(もっと読む)
シミュレーション装置及びシミュレーション方法
【課題】設計対象の検証を容易に行うことを可能とする。
【解決手段】検出部11が、設計対象20において実行される各関数が配置されるメモリ22上のアドレス範囲、または関数間を移動する命令が配置されるメモリ22上のアドレスを検出し、関数スタック生成部12が、設計対象20で実行される各命令のアドレスと、各関数が配置されるメモリ22上のアドレス範囲または関数間を移動する命令のアドレスとを比較し、比較結果に応じて関数間の呼び出し関係を示す関数スタックを生成する。
(もっと読む)
情報処理システム及びその評価方法
【課題】モードを変更してもシステムを停止する必要がなく、システムの評価を効率的に行うことが可能な情報処理システムを提供する。
【解決手段】命令バッファ3のリタイヤカウンタ10を監視し、リタイヤカウンタ10が所定のしきい値11を超えたことを検知する手段、リタイヤカウンタ10が所定のしきい値11を超えた時には動作モードを通常モードから安定モードに変更する手段、安定モードに変更後に新規にコンテキストスイッチ7が発生した時に動作モードを通常モードに戻す手段を具備する。また、リタイヤカウンタ10が所定のしきい値11を超えた時にフェッチICをリタイヤIC15に更新してプログラムをリタイヤICから再開させる。
(もっと読む)
スタックトレース採取システム、方法およびプログラム
【課題】システムへの負荷の増大なしに、スタックトレース情報を格納するのに必要なメモリ容量を削減し、かつ、障害を起こしているプロセス/スレッドを特定する。
【解決手段】スタックトレース採取システムは、プロセスが実行単位であるスレッド毎に実行される実行部30と、トレースデータ格納部33を有する。実行部30は、実行中のスレッドが別のスレッドに切り替わる際に、該実行中のスレッドの切り替え直前における処理状態を示す第1のスタックトレース情報とスレッドの切り替え後に実行された別のスレッドの切り替え直後の処理状態を示す第2のスタックトレース情報をそれぞれ採取し、該採取した第1及び第2のスタックトレース情報をトレースデータ格納部33に格納するスタックトレース採取部31と、トレースデータ格納部33に格納された第1および第2のスタックトレース情報を外部記憶装置に出力するトレースデータ出力部32を有する。
(もっと読む)
情報処理システム、情報処理方法、クライアント装置及びその制御方法、管理サーバ装置及びその制御方法、プログラム、記録媒体
【課題】 Webアプリケーションの現実の利用態様をより正確に把握可能にする技術を提供する。
【解決手段】 情報処理システムは、ネットワーク上で提供されるWebアプリケーションを閲覧するクライアント装置と、クライアント装置の動作を管理する管理サーバ装置とを有する。クライアント装置はウィンドウシステムを提供し、ウィンドウシステムにおいてWebアプリケーションを閲覧可能に表示し、最前面のウィンドウのキャプション名を取得し、取得したキャプション名を取得情報とともに管理サーバ装置へ送信する。管理サーバ装置は、クライアント装置から受信した取得情報によりキャプション名で識別されるWebアプリケーションの利用状況を算出し、算出した利用状況を記憶手段に記憶させる。
(もっと読む)
情報処理システム、スタックオーバーフローの発生検出方法及びプログラム
【課題】本発明はスタックのオーバーフローを起因とするスタック破壊の検出について、オペレータの手間をかけずに検出できるOS、マルチタスクOSに組み込まれる情報処理システム、スタックオーバーフローの発生検出方法及びOSを提供することを課題とする。
【解決手段】ディスパッチ若しくは割り込み要求が生じたとき、OSのディスパッチャ若しくは割り込みハンドラはスタックポインタ値を調べスタックのオーバーフローが発生していないかをチェックする。またこのときのスタックポインタ値とシステム時刻をバッファリングする。
(もっと読む)
性能モニタリングプログラム、性能モニタリング方法、性能モニタリング装置
【課題】ページング方式の仮想記憶を持つCPUにおいて実行されるプログラム(プロセス)毎の動作情報を、オペレーティングシステム側に特別な改変を加えることなく、正確に効率良くモニタリングする技術を提供する。
【解決手段】オペレーティングシステムにて行われるTLBエントリの無効化に伴ってプロセッサで実行される割込み処理の発生を検出する割込検出部と、割込検出部にて割込み処理が検出されたタイミングにおいて、プロセッサにてカウントされた所定のイベントのカウンタ値を取得するカウンタ値取得部と、割込検出部にて検出される割込み処理の直前にプロセッサ上で実行されていたプロセスを識別するための識別情報をオペレーティングシステムから取得するプロセス情報取得部と、カウンタ値取得部にて割込み処理時に取得されるカウンタ値と、該割込み処理の直前にプロセス情報取得部にて取得される情報とを対応付ける対応付け部と、を備える。
(もっと読む)
命令ログ取得プログラム及び仮想計算機システム
【課題】仮想計算機から仮想計算機モニタに制御権が戻る場合に、仮想計算機で実行される命令のログ情報を取得する命令ログ取得プログラムを提供する。
【解決手段】仮想計算機モニタ1において、ログ情報を取得すべき命令を指定する判定情報が判定情報保持部115に保持される。仮想計算機から仮想計算機モニタ1に複数の実CPUの制御権が戻る場合に、仮想計算機が最後に実行した命令の命令アドレスに基づいて定まる範囲の命令アドレスの命令が取得される。取得された命令が判定情報で指定された命令である場合、その命令の命令アドレスとその命令が取得された回数である取得回数とを含むログ情報が、ログ情報保持部116に記録される。
(もっと読む)
情報処理装置及び情報処理プログラム
【課題】制御手段が停止する動作モードを備えた場合でも、複雑な処理を行なうことなく通信に用いる情報の期限管理が実行できる情報処理装置及び情報処理プログラムを提供する。
【解決手段】何れかの機能の実行指示が入力された場合、及び外部機器から情報を受信した場合に、その旨を示す割り込み信号が入力された場合に、CPU20により割り込み信号に応じた処理を示す割り込みハンドラに基づく処理を実行する際に、予め設定された条件が成立した場合にCPU20への駆動電力の供給を遮断する第2の節電モードに移行し、第2の節電モードにおいて割り込み信号が入力された場合にCPU20への駆動電力の供給を再開すると共に、通信機能を実行するために用いる情報に予め設定されている有効期限が経過している場合はその情報を廃棄する。
(もっと読む)
情報処理装置の監視・管理システム
【課題】アプリケーションソフトの稼働状況を監視し、リアルタイムでアプリケーションソフトの使用を管理することが可能である情報処理装置の監視・管理システムを提供すること。
【解決手段】監視・管理装置から端末への動作要求に基づき、所定時間間隔で端末のアプリケーションソフトの稼働状況を記録させ、また、指定したアプリケーションソフトの使用を自動停止させ、また、出力画面の記録をさせ、前記稼働状況と出力画面について端末から監視・管理装置に送信させ、監視・管理装置上で再生する手段を有する。
(もっと読む)
マイクロコントロールユニット及びマイクロコントロールユニットの不良解析方法
【課題】システム内で異常動作を起こした場合に、単体での異常動作再現を容易に行い、異常動作発生原因となっているプログラム上のポイントの絞り込み作業を容易に行うことができるようにしたマイクロコントロールユニット(MCU)を提供する。
【解決手段】本発明のMCUの第1実施形態1がシステム2内で異常動作を起こした場合には、まず、システム2内で本発明のMCUの第1実施形態1を動作させ、分岐情報及び特定アドレス・アクセス情報を抽出してパソコン3に記録する。その後、本発明のMCUの不良解析方法の第1実施形態1を簡易動作ボード4に移して単体で動作させる状態におき、パソコン3から分岐情報及び特定アドレス・アクセス情報を本発明のMCUの第1実施形態1に戻して利用し、本発明のMCUの第1実施形態1にシステム2内での動作を再現させる。
(もっと読む)
デバッグ装置
【課題】トレース条件設定回路による回路の複雑化やトレースメモリの物理的規模の拡大を抑えてソースプログラムの関数ID又はOSによって管理されるタスクの処理順序を把握すること。
【解決手段】トレース制御中、マイクロコンピュータ(2)が実行するオブジェクトプログラムの命令アドレスに対応するソースプログラムの関数IDが変化したとき、変化した関数IDをトレースメモリ(5)に格納するように制御する。また、OSの管理の下でマイクロコンピュータが処理するタスクのタスクIDを監視し、タスクIDが変化したとき、変化したタスクIDをトレースメモリに格納するように制御する。これにより、変化した関数ID又はタスクIDがトレースメモリに逐次格納されるため、トレース結果からマイクロコンピュータが実行したソースプログラムの関数IDの処理順序又はマイクロコンピュータが実行したタスクIDの処理順序を容易に把握することができる。
(もっと読む)
プログラムプロファイリング装置、プログラムプロファイリング方法、及びプログラム
【課題】実行環境に比較的負荷をかけることなくプログラムをプロファイリングする。
【解決手段】統計モード計測部231は、複数のメソッドから構成された実行プログラムを実行した際に、実行したメソッド毎の処理時間と実行したメソッド間の呼出関係とを計測してその結果を記憶する。そして、計測対象設定部24は、記憶したその結果から、実行時間の主要な要因となる主要メソッドを特定し、主要メソッドのみを、詳細モードでのメソッドの処理の計測の対象に設定する。そして、詳細モード測定部232は、実行プログラムを実行した際に、計測対象設定部24によって測定対象に設定された主要メソッドが処理する毎に、該主要メソッドの処理に関する詳細な情報を取得して記憶し、シーケンス解析部はその情報からシーケンスを解析する。
(もっと読む)
電子機器
【課題】主たる処理の実行速度が低下しないようにして、スタック使用量を検出し、記録することが可能な技術を提供すること。
【解決手段】本発明が適用された電子制御装置では、検査対象のスタック領域に蓄積されたデータの最大量を検出し、この検出量を、ピークテーブルに記録するスタック領域検査タスクを、アイドルタスクとして生成し、検査対象のスタック領域を使用する他のタスク(主タスク)が実行状態及び実行可能状態にない期間に実行する。また、このスタック領域検査タスクでは、スタック領域の上端から下端に向けて、ブロック単位で領域内部を参照し、参照ブロックがオールゼロのブロック(領域内のビットが全てリセット状態のブロック)であるか否かを検査する。そして、この検査結果に基づき、スタック領域の最大使用量を検出する。
(もっと読む)
プロファイリングプログラムおよびプロファイリング方法
【課題】プロファイリングにおいて少ないオーバヘッドで詳細な情報を収集すること。
【解決手段】ターゲット範囲指定インタフェース120が情報収集対象範囲の指定をアプリケーションプログラム30から受け取ってフラグ管理テーブル150に登録し、フラグ設定インタフェース130がフラグ値をアプリケーションプログラム30から受け取ってフラグ管理テーブル150に設定し、割込みハンドラ140が割込み発生時の実行アドレスがフラグ管理テーブル150に登録された情報収集対象範囲のいずれかに該当する場合には実行アドレスとともにフラグ管理テーブル150のその時点のフラグ値を割込みハンドラ記録テーブル160に記録する。
(もっと読む)
分散型プログラムのトレース装置
【課題】CORBA等を使用した複数ノードに跨る分散型プログラムにおいて、他のノードを経由して同一処理上で同一ロックを捕捉しようとした場合に発生するデッドロックを検出する。
【解決手段】トレース実行中に各ノード上でロックを捕捉する処理の起動元ノード名と、起動元スレッド番号とを含むロックに関する実行状態を書き込むためのロック情報格納領域と、各ノード上でロックに関する実行状態を周期的に監視し、デッドロックが発生したことを検出する手段とを備える分散型プログラムのトレース装置。ロック情報を保存する際に起動元ノード名と起動元スレッド番号とを設定することにより、複数ノードに跨る分散型のプログラムであっても、同一処理上で同一ロックを捕捉しようとしていることが検出することができるため、デッドロックを検出することができる。
(もっと読む)
トレース装置、トレース方法およびトレースプログラム
【課題】 デバッグ対象のプログラムと協働する他のプログラムを実際に動作させた結果に基づいてデバッグを行うことができなかった。
【解決手段】 上位プログラムと下位プログラムと検査対象プログラムとが動作するシステムをトレースするにあたり、上記検査対象プログラムと同じインタフェースによって上記上位プログラムと下位プログラムとからの入力情報の取得および上記上位プログラムと下位プログラムとへの出力情報の受け渡しを実行し、上記取得した入力情報に基づいて上記検査対象プログラムを動作させ、当該検査対象プログラムの出力情報に基づいて上記インタフェースによる受け渡しを行い、これらの入出力に関するログを記録する。
(もっと読む)
1 - 20 / 34
[ Back to top ]