
Fターム[5B045BB28]の内容
マルチプロセッサ (2,696) | 通信、転送方式 (1,368) | 系路の接続、切替方式 (844) | 接続、切替の対象 (453) | 処理装置(CPU) (306)
Fターム[5B045BB28]に分類される特許
1 - 20 / 306
画像音声信号処理装置及びそれを用いた電子機器
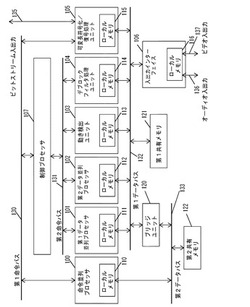
【課題】 MPEG−4 AVCの符号化/復号処理のような、大量のデータ処理量が要求される画像処理に対して、高性能で、高効率な画像処理が行える信号処理装置及びそれを用いた電子機器を提供する。
【解決手段】 信号処理装置は、命令並列プロセッサ100、第1データ並列プロセッサ101、第2データ並列プロセッサ102、及び、専用ハードウェアである動き検出ユニット103とデブロックフィルタ処理ユニット104と可変長符号化/復号処理ユニット105とを備える。この構成により、処理量の多い画像圧縮伸張アルゴリズムの信号処理において、ソフトウェアとハードウェアで負荷が分散され高い処理能力と柔軟性を実現した信号処理装置、及びそれを用いた電子機器を提供出来る。
(もっと読む)
データ中継制御装置、リンク間転送設定支援装置およびリンク間転送設定方法

【課題】共有メモリ方式のサイクリック伝送されているネットワークが複数存在する制御システムで、一つのネットワークの通信ノードから別のネットワークの通信ノードへ共有メモリ領域のデータを転送するリンク間転送の設定を人手によらず設定することができるデータ中継制御装置を得ること。
【解決手段】複数のネットワークにそれぞれ接続される複数のノード31,32と、複数のノード31,32間を通信路で接続するベースと、リンク間転送設定に基づいて、データを一のネットワークに接続されるノードから前記他のネットワークに接続されるノードに転送するリンク間転送制御部35と、プログラムで使用されるメモリ領域に付されたラベルと、ラベルが演算前にデータを格納する動作か、演算後のデータの行き先となる動作かを示すフラグ情報と、を有するラベル割付情報に基づいて、リンク間転送設定を生成するリンク間転送設定生成部33と、を備える。
(もっと読む)
I/O制御装置およびI/O制御方法
【課題】他のコアプロセッサが初期化したI/O装置に対するI/O要求を受けた場合であっても、コアプロセッサがそのI/O要求に対応することができるようにすること。
【解決手段】I/O制御装置1において、マルチコアプロセッサ6と、マルチコアプロセッサ6のうち、SASコントローラ1d、DMAコントローラ1eの初期化を行ったコアプロセッサ1b、1cの識別情報を記憶する記憶手段3aと、を備え、コアプロセッサ1b、1cと異なるコアプロセッサ1aがSASコントローラ1dについてのI/O要求を受けると、コアプロセッサ1aは、記憶手段3aを参照して特定される、コアプロセッサ1bに対して、I/O要求の処理を依頼する。
(もっと読む)
処理装置、及び、処理装置の起動方法
【課題】複数のCPUがメモリーを共有する構成を、より単純な回路構成によって実現する。
【解決手段】複数のCPU121、122と、これら複数のCPU121、122により共有されるROM130とを備え、少なくともいずれかのCPUがメインCPUとして起動し、メインCPU用の所定のアドレスに基づいてROM130から起動プログラムを読み出した後、他のCPUを起動させる制御を行い、メインCPUにより起動されたCPU122は、サブCPU用の所定のアドレスに従ってROM130から起動プログラムを読み出す。
(もっと読む)
異なる複数の優先度レベルのトランザクション要求をサポートする集積回路内における処理リソース割振り
【課題】異なる複数の優先度レベルのトランザクション要求をサポートする集積回路内における処理リソース割振りを実現すること。
【解決手段】集積回路2は、複数のトランザクションソース6、8、10、12、14、16、18および20を含み、トランザクションソースは、関連付けられたPOC/POS30および34を各々が有する共有キャッシュ22および24とリングベースの相互接続30を介して通信し、要求サービング回路として働く。要求サービング回路は、異なる複数のトランザクションに割り振ることができる処理リソース36のセットを有する。これらの処理リソースは、動的に、または静的に割り振ることができる。静的割振りは、選択アルゴリズムに依存して行うことができる。この選択アルゴリズムは、入力変数のうちの1つとしてサービス品質値/優先度レベルを使用することができる。
(もっと読む)
相互接続装置、および、相互接続装置の制御方法ならびに当該方法をコンピュータに実行させるプログラム
【課題】相互接続装置においてデッドロックを回避しつつ、レイテンシを低減する。
【解決手段】リクエスト管理部は、複数のマスタのいずれかから複数のスレーブのいずれかに対して発行されたリクエストがそのリクエストに先行して発行された先行リクエストの複数のスレーブのいずれかへの出力を待つべき待機リクエストである場合にはその待機リクエストに先行リクエストを対応付けて管理する。調停部は、複数のマスタから発行された複数のリクエストを調停して調停したリクエストを複数のスレーブのうち調停したリクエストの宛先である応答デバイスに出力する。リクエスト待機制御部は、待機リクエストを待機させて、その待機リクエストに対応する先行リクエストが複数のスレーブのいずれかに出力された後に待機リクエストを調停部へ出力する。
(もっと読む)
情報処理装置及び画像形成装置
【課題】一つのチップの機能ブロックから別のチップの機能ブロックへデータを転送する場合に、予め定められた機能ブロックからのデータについては、転送遅延が生じないようにする。
【解決手段】監視部37は、第1の送信バッファ25に蓄積されているデータ量が、所定のしきい値を超えていれば、第1のチップ11と第2のチップ13との間でデータの転送遅延が発生するとみなす。しきい値を超えれば、第2にチップ13に配置された複数の第2の機能ブロックのうち予め定められた第2の機能ブロックについては、第2のチップ13において、第2の送信バッファを経由させずに第2の追越用ラインを経由させ、第1のチップ11において、第1の受信バッファ35を経由させずに第1の追越用ライン39を経由させて、宛先となる第1の機能ブロック19へ転送させる。
(もっと読む)
分散共有メモリ管理システム、分散共有メモリ管理方法、および分散共有メモリ管理プログラム
【課題】メモリを共有する異なるノードにおけるメモリ資源・通信資源の使用効率を高める。
【解決手段】固有メモリに格納されたデータ値を更新し、更新された値が予め設定された共通初期値と異なる場合に更新された値と該値の固有メモリにおけるアドレスを送出する計算ノードと、共有メモリに格納されたデータを共通初期値で初期化するデータ初期化機能と、計算ノードから更新データが送り込まれた場合に前記更新データに基づき前記共有メモリにおける対応するアドレスのデータを前記更新値へと更新する共有メモリデータ更新機能を有するメモリ管理装置を備える。
(もっと読む)
集積回路装置及び電子機器
【課題】グラフィックス処理性能をスケーラブルに調整可能であり、目標とする処理性能に応じて、最適なシステムを構築することのできる集積回路装置を提供する。
【解決手段】目標性能に応じた数の集積回路をカスケード接続することにより、グラフィックス処理性能をスケーラブルに拡張又は縮小できるという知見に基づく。第1の集積回路1と、第2の集積回路2と、第1の集積回路1と第2の集積回路2を接続する通信用バス4と、第1の集積回路1の演算結果を第2の集積回路2に出力するための入出力用バス5を含む。
(もっと読む)
異種計算機システムにおけるプロセッサブリッジ
【課題】ブリッジ論理デバイスを提供する。
【解決手段】1つ以上の高性能プロセッサと、該1つ以上の高性能プロセッサがソフトウェアのタスクを実行するのを支援するプロセッサ支援論理回路と、該1つ以上の高性能プロセッサより少ない電力を消費するハイパーバイザプロセッサとを有する異種計算機システムのためのブリッジ論理デバイス。このブリッジ論理デバイスは該1つ以上の高性能プロセッサの下の該システムのステータスを保守するハイパーバイザ動作論理回路と、該1つ以上の高性能プロセッサと該ハイパーバイザプロセッサとのプロセッサ言語間の翻訳をするプロセッサ言語翻訳論理回路と、第1、第2、及び第3ポートを有し該3つのポートのうち任意2つの間でデータを双方向に中継する高速バススイッチとを備える。該バススイッチは該1つ以上の高性能プロセッサに該第1ポートが接続され、該ハイパーバイザプロセッサに該プロセッサ言語翻訳論理回路を介して該第2ポートが接続され、該プロセッサ支援論理回路に該第3ポートが接続される。
(もっと読む)
情報処理装置、通信方法、及びプログラム
【課題】 リング状のバスを用いて、データの受け渡し及び処理を行う情報処理装置では、保留パケットが増大し、デッドロックが発生するおそれがあった。
【解決手段】 情報処理装置は、リング状にバス接続されている複数の通信手段を備え、複数の通信手段の少なくとも1つは、受信したデータに対して処理を実行する処理手段が、通信手段に対応する処理手段より後の処理を実行する処理手段であるかを判定し、受信したデータについて、他の通信手段に対応する処理手段において処理が保留されたかを検知し、受信したデータに対して処理を実行する処理手段が通信手段に対応する処理手段より後の処理を実行する処理手段であると判定され、受信したデータに対する処理が保留されたことを検知した場合、送信間隔を延長する。
(もっと読む)
半導体集積回路装置
【課題】容易にカスタマイズ対応可能な半導体集積回路装置を提供する。
【解決手段】アレイ型プロセッサ部(300)は、プロセッサエレメント(330)とプログラマブルスイッチ(320)とを備えるプロセッサユニット(310)をマトリクス状に配置する。プロセッサエレメント(330)は、複数ビット幅の第1演算器(332)と複数ビット幅より狭い所定のビット幅の第2演算器(333)とを有する。第1演算器(332)および第2演算器(333)の接続構成は構成情報メモリ(340)に設定される構成情報に基づいて変更可能である。プログラマブルスイッチ(320)は、配線からプロセッサエレメントに複数ビット幅のデータおよび所定のビット幅のデータを構成情報に基づいて入出力する。制御回路(200)は、内部バス(180)に接続され、アレイ型プロセッサ部(300)の動作を制御し、内部バス(180)を介してデータを授受する。
(もっと読む)
ルーティングのための方法及び装置
【課題】データプロセッサコアのサイズ及び遅延を小さくすること。
【解決手段】データプロセッサが開示され、該データプロセッサが、該データプロセッサ外部のデータ経路を通して要求をルーティングすることによって該データプロセッサのローカルメモリをアクセスする。予約/修飾コントローラが、ローカルメモリをアクセスするための受信される要求に関連される特定動作を実行される。特定動作に加えて、データプロセッサコアのローカルメモリをアクセスするために予約/修飾コントローラに関連するメモリコントローラが相当するアクセス要求をデータプロセッサコアにルーティングする。
(もっと読む)
情報処理装置、並列計算機システム、および並列計算機システムの制御方法
【課題】通信相手の情報処理装置までの経路選択を通信の送信とは分離して行う並列計算機の情報処理装置、並列計算機システム、制御方法を提供する。
【解決手段】複数の情報処理装置が複数経路を介して接続された並列計算機システムにおいて、各情報処理装置は、輻輳情報収集の指示および通信の指示を行なう演算処理装置と、通信を行なう場合の経路情報を保持する経路情報保持部と、輻輳情報収集パケットを複数経路のいずれかに送信する送信部と、複数経路のいずれかから輻輳情報収集パケットに対応する輻輳情報収集応答パケットを受信する受信部と、演算処理装置が輻輳情報収集を指示した場合に、生成した輻輳情報収集パケットを送信部に送信させ、受信部が受信した輻輳情報収集応答パケットに含まれる輻輳情報に基づき経路情報保持部が保持する経路情報を書き替え、書き替えた経路情報に基づき演算処理装置が指示した通信を送信部に行なわせる制御部を有する。
(もっと読む)
データ転送装置、並列計算機システムおよびデータ転送装置の制御方法
【課題】データの転送効率を低下させることなく各計算ノード間における通信に対して帯域を適切に分配できない。
【解決手段】1つの側面では、ルータ10は、受信した複数のデータを調停して転送する転送装置である。このルータ10は、複数のデータを受信した場合には、データが受信されるまでに調停の相手になった他のデータの累積数を取得する。また、ルータ10は、取得したデータの数に基づいて、各データから取得した累積数を更新する。そして、ルータ10は、更新した各データの累積数に基づいて、受信したデータを調停して、計算ノード2aへ送信するデータを選択する。その後、ルータ10は、選択したデータに更新した累積数を格納し、更新した累積数を格納したデータを計算ノード2aへ送信する。
(もっと読む)
並列計算機システム、制御装置、並列計算機システムの制御方法および並列計算機システムの制御プログラム
【課題】故障した計算ノードがネットワークに混在する場合にも、シミュレーション対象を分割した各領域を適切な位置関係を有する計算ノードにマッピングする。
【解決手段】並列計算機10は、互いに接続された複数の計算ノードをそれぞれ備える複数の計算ユニット11〜22を有し、各計算ユニット11〜22にそれぞれ含まれる計算ノードを一対一に接続する複数の経路を有するリンクを有する。また、制御装置30は、並列計算機10が有する複数の計算ノードから故障が発生した故障ノードを検出する。また、制御装置30は、並列計算機10が有する複数の計算ノードから検出された故障ノードを除いて、プログラムを実行させる実行ノードを選択する。また、制御装置30は、選択された実行ノードを含む複数の計算ユニットにおいて、隣り合う2つの計算ユニットをそれぞれ接続する複数の経路のうち、故障ノードに接続された経路以外の経路を選択する。
(もっと読む)
障害処理回路を含むマルチノードシステム及び障害処理方法
【課題】ノード間接続装置で障害が発生した場合にその障害の影響が全ノードに及ぶことを回避可能としたマルチノードシステムと処理方法を提供する。
【解決手段】複数のノードがノード間接続装置によって接続されたマルチノードシステムにおいて、ノード間接続装置にて障害が発生した場合に、その障害を全ノードに通知するのではなく、障害が影響するノードにのみ障害を通知し、障害が影響しないノードへは障害を通知せずに運用を継続できるようその障害発生箇所とシステム構成に応じて障害通知先を選択する障害処理回路を備えることによって、ノード間接続装置の障害が影響するノードの範囲を最小限に抑える。
(もっと読む)
デバイスシステムおよびチップ
【課題】拡張性のよいシステムを提供する。
【解決手段】マスター(プロセッサー52a)は送信先のスレーブ(SDRAMコントローラー34)の識別情報S1と自身の識別情報M3とを格納してリクエストを送信し、ルーター57は識別情報S1に基づいてポートP56にリクエストを転送し、チップリンク58,39を介してリクエストを受信したルーター37は識別情報S1に基づいてポートP33にリクエストを転送する。スレーブは識別情報M3を格納してレスポンスを送信し、ルーター37は識別情報M3に基づいてポートP35にレスポンスを転送し、チップリンク39,58を介してレスポンスを受信したルーター57は識別情報M3に基づいてポートP51にレスポンスを転送する。これにより、マスターやスレーブ,各ルーターは、チップ内の通信と同様な処理でチップ31,47間の通信を行なうことができる。
(もっと読む)
データ転送制御装置及びプログラム
【課題】共有メモリのサイズに制限があっても、異なるOS間で効率的にデータ転送を行う。
【解決手段】第1OSから第2OSで管理するハードウェア・デバイスへデータを転送するためのデータ転送命令が第1OSに対して発行された場合に、該データ転送命令による転送対象のデータを、第1OS及び第2OSが共有して使用する共有メモリの使用可能なサイズよりも小さいサイズの複数個の分割データに分割して、該共有メモリに書き込み、、該共有メモリに書き込まれた分割データが第2OSにおいて読み出されて上記ハードウェア・デバイスに転送されるように、上記分割データが共有メモリに書き込まれる毎に、該分割データのデータサイズを転送サイズとして指定した分割データ転送コマンドを生成して第2OSに対して発行する。
(もっと読む)
データ処理装置
【課題】任意のネットワークに接続する任意の機器間で用いられるローカルメモリの関係付けを可能とする。
【解決手段】プロファイルデータ4には、機器ごとに、接続先のネットワーク種別が記述されるとともに、所定のパラメータが記述されている。メモリ割付ルールデータ6には、ネットワーク種別ごとに、プロファイルデータ4に記述されているパラメータを用いたメモリ割付けルールが記述されている。機器構成管理部8は、メモリ割付けの対象となるネットワーク種別を接続先とする機器のプロファイルデータ4に記述されているパラメータを抽出し、抽出したパラメータを、対応する機器とともに表示し、各パラメータに対して、機器のローカルメモリを特定するための設定情報を入力する。メモリ割付解析部9は、パラメータに対する設定情報を用いてメモリ割付けルールを解析し、関係付けるローカルメモリの組を特定する。
(もっと読む)
1 - 20 / 306
[ Back to top ]