
Fターム[5B045BB29]の内容
マルチプロセッサ (2,696) | 通信、転送方式 (1,368) | 系路の接続、切替方式 (844) | 接続、切替の対象 (453) | メモリ、ファイル (109)
Fターム[5B045BB29]に分類される特許
1 - 20 / 109
画像音声信号処理装置及びそれを用いた電子機器
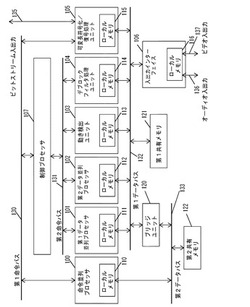
【課題】 MPEG−4 AVCの符号化/復号処理のような、大量のデータ処理量が要求される画像処理に対して、高性能で、高効率な画像処理が行える信号処理装置及びそれを用いた電子機器を提供する。
【解決手段】 信号処理装置は、命令並列プロセッサ100、第1データ並列プロセッサ101、第2データ並列プロセッサ102、及び、専用ハードウェアである動き検出ユニット103とデブロックフィルタ処理ユニット104と可変長符号化/復号処理ユニット105とを備える。この構成により、処理量の多い画像圧縮伸張アルゴリズムの信号処理において、ソフトウェアとハードウェアで負荷が分散され高い処理能力と柔軟性を実現した信号処理装置、及びそれを用いた電子機器を提供出来る。
(もっと読む)
処理装置、及び、処理装置の起動方法

【課題】複数のCPUがメモリーを共有する構成を、より単純な回路構成によって実現する。
【解決手段】複数のCPU121、122と、これら複数のCPU121、122により共有されるROM130とを備え、少なくともいずれかのCPUがメインCPUとして起動し、メインCPU用の所定のアドレスに基づいてROM130から起動プログラムを読み出した後、他のCPUを起動させる制御を行い、メインCPUにより起動されたCPU122は、サブCPU用の所定のアドレスに従ってROM130から起動プログラムを読み出す。
(もっと読む)
異なる複数の優先度レベルのトランザクション要求をサポートする集積回路内における処理リソース割振り
【課題】異なる複数の優先度レベルのトランザクション要求をサポートする集積回路内における処理リソース割振りを実現すること。
【解決手段】集積回路2は、複数のトランザクションソース6、8、10、12、14、16、18および20を含み、トランザクションソースは、関連付けられたPOC/POS30および34を各々が有する共有キャッシュ22および24とリングベースの相互接続30を介して通信し、要求サービング回路として働く。要求サービング回路は、異なる複数のトランザクションに割り振ることができる処理リソース36のセットを有する。これらの処理リソースは、動的に、または静的に割り振ることができる。静的割振りは、選択アルゴリズムに依存して行うことができる。この選択アルゴリズムは、入力変数のうちの1つとしてサービス品質値/優先度レベルを使用することができる。
(もっと読む)
相互接続装置、および、相互接続装置の制御方法ならびに当該方法をコンピュータに実行させるプログラム
【課題】相互接続装置においてデッドロックを回避しつつ、レイテンシを低減する。
【解決手段】リクエスト管理部は、複数のマスタのいずれかから複数のスレーブのいずれかに対して発行されたリクエストがそのリクエストに先行して発行された先行リクエストの複数のスレーブのいずれかへの出力を待つべき待機リクエストである場合にはその待機リクエストに先行リクエストを対応付けて管理する。調停部は、複数のマスタから発行された複数のリクエストを調停して調停したリクエストを複数のスレーブのうち調停したリクエストの宛先である応答デバイスに出力する。リクエスト待機制御部は、待機リクエストを待機させて、その待機リクエストに対応する先行リクエストが複数のスレーブのいずれかに出力された後に待機リクエストを調停部へ出力する。
(もっと読む)
情報処理装置及び画像形成装置
【課題】一つのチップの機能ブロックから別のチップの機能ブロックへデータを転送する場合に、予め定められた機能ブロックからのデータについては、転送遅延が生じないようにする。
【解決手段】監視部37は、第1の送信バッファ25に蓄積されているデータ量が、所定のしきい値を超えていれば、第1のチップ11と第2のチップ13との間でデータの転送遅延が発生するとみなす。しきい値を超えれば、第2にチップ13に配置された複数の第2の機能ブロックのうち予め定められた第2の機能ブロックについては、第2のチップ13において、第2の送信バッファを経由させずに第2の追越用ラインを経由させ、第1のチップ11において、第1の受信バッファ35を経由させずに第1の追越用ライン39を経由させて、宛先となる第1の機能ブロック19へ転送させる。
(もっと読む)
マルチプロセッサおよびそれを用いた画像処理システム
【課題】データの共有やデータ転送のバッファリングを容易に行なうことが可能なマルチプロセッサを提供すること。
【解決手段】複数の共有ローカルメモリ5−0〜5−(n−1)のそれぞれが、複数のプロセッサユニットPU0〜PU(n−1)(1−0〜1−(n−1))の中の2つのプロセッサに接続されており、複数のプロセッサユニットPU0〜PU(n−1)(1−0〜1−(n−1))と複数の共有ローカルメモリ5−0〜5−(n−1)とがリング状に接続される。したがって、データの共有やデータ転送のバッファリングを容易に行なうことが可能となる。
(もっと読む)
ルーティングのための方法及び装置
【課題】データプロセッサコアのサイズ及び遅延を小さくすること。
【解決手段】データプロセッサが開示され、該データプロセッサが、該データプロセッサ外部のデータ経路を通して要求をルーティングすることによって該データプロセッサのローカルメモリをアクセスする。予約/修飾コントローラが、ローカルメモリをアクセスするための受信される要求に関連される特定動作を実行される。特定動作に加えて、データプロセッサコアのローカルメモリをアクセスするために予約/修飾コントローラに関連するメモリコントローラが相当するアクセス要求をデータプロセッサコアにルーティングする。
(もっと読む)
アクセス装置及びアクセス方法
【課題】他の処理から見たときのアクセス処理によるオーバーヘッドを削減することを可能とするアクセス装置を提供する。
【解決手段】拡張ユニットと、前記拡張ユニットにアクセスする機能を有する1以上のアクセス装置と、を備える拡張記憶装置におけるアクセス装置であって、マルチコアCPU又は複数のCPUにより当該アクセス装置に複数のコアが備わるようにし、第1のコアでは、拡張ユニットアクセス専用ファームウェアが実行され、第2のコアでは、拡張記憶装置ファームウェアが実行され、前記拡張ユニットアクセス専用ファームウェアは、前記拡張ユニットにアクセスする処理の少なくとも一部を前記第1のコアに実行させるものであり、前記拡張記憶装置ファームウェアは、前記第2のコアで実行されるプログラムと前記拡張ユニットアクセス専用ファームウェアとの仲介をする処理を前記第2のコアに実行させるものである。
(もっと読む)
デバイスシステムおよびチップ
【課題】拡張性のよいシステムを提供する。
【解決手段】マスター(プロセッサー52a)は送信先のスレーブ(SDRAMコントローラー34)の識別情報S1と自身の識別情報M3とを格納してリクエストを送信し、ルーター57は識別情報S1に基づいてポートP56にリクエストを転送し、チップリンク58,39を介してリクエストを受信したルーター37は識別情報S1に基づいてポートP33にリクエストを転送する。スレーブは識別情報M3を格納してレスポンスを送信し、ルーター37は識別情報M3に基づいてポートP35にレスポンスを転送し、チップリンク39,58を介してレスポンスを受信したルーター57は識別情報M3に基づいてポートP51にレスポンスを転送する。これにより、マスターやスレーブ,各ルーターは、チップ内の通信と同様な処理でチップ31,47間の通信を行なうことができる。
(もっと読む)
データ転送制御装置及びプログラム
【課題】共有メモリのサイズに制限があっても、異なるOS間で効率的にデータ転送を行う。
【解決手段】第1OSから第2OSで管理するハードウェア・デバイスへデータを転送するためのデータ転送命令が第1OSに対して発行された場合に、該データ転送命令による転送対象のデータを、第1OS及び第2OSが共有して使用する共有メモリの使用可能なサイズよりも小さいサイズの複数個の分割データに分割して、該共有メモリに書き込み、、該共有メモリに書き込まれた分割データが第2OSにおいて読み出されて上記ハードウェア・デバイスに転送されるように、上記分割データが共有メモリに書き込まれる毎に、該分割データのデータサイズを転送サイズとして指定した分割データ転送コマンドを生成して第2OSに対して発行する。
(もっと読む)
データ処理装置
【課題】任意のネットワークに接続する任意の機器間で用いられるローカルメモリの関係付けを可能とする。
【解決手段】プロファイルデータ4には、機器ごとに、接続先のネットワーク種別が記述されるとともに、所定のパラメータが記述されている。メモリ割付ルールデータ6には、ネットワーク種別ごとに、プロファイルデータ4に記述されているパラメータを用いたメモリ割付けルールが記述されている。機器構成管理部8は、メモリ割付けの対象となるネットワーク種別を接続先とする機器のプロファイルデータ4に記述されているパラメータを抽出し、抽出したパラメータを、対応する機器とともに表示し、各パラメータに対して、機器のローカルメモリを特定するための設定情報を入力する。メモリ割付解析部9は、パラメータに対する設定情報を用いてメモリ割付けルールを解析し、関係付けるローカルメモリの組を特定する。
(もっと読む)
相互結合網制御システム、相互結合網制御方法
【課題】情報間の順序を保証しつつ相互結合網の性能低下を抑制する相互結合網制御システム及び方法を提供すること。
【解決手段】本発明にかかる相互結合網制御システムは、相互結合網2と、順序保証バッファ3と、順序情報制御部4と、読出制御部5とを有する。相互結合網2は、複数の入力ポートと複数の出力ポートとを有し、入力ポートから入力された情報を、情報の出力先である出力ポートに出力する。順序情報制御部4は、入力ポートに入力される情報に対し、情報の出力先である出力ポート毎に、情報の読出順序を定める順序情報を付与する。順序保証バッファ3は、出力ポートから出力された情報を蓄積する。読出制御部5は、順序保証バッファ3に蓄積された情報を、順序情報により定められる順序にしたがって読出す。
(もっと読む)
アイソレーションメモリバッファを組み込んだロードリデュースド・デュアル・インライン・メモリ・モジュール(LR−DIMM)を利用したスイッチ/ネットワークアダプタ・ポートインターフェースを含むヘテロジニアスコンピューティングシステム
【課題】アイソレーションメモリバッファを組み込んだLR−DIMMを利用したスイッチ/ネットワークアダプタ・ポートインターフェースを含むヘテロジニアスコンピューティングシステムを提供する。
【解決手段】コンピュータシステム100は、少なくとも1つの高密度ロジックデバイス106及びメモリバスに高密度ロジックデバイスを接続するコントローラを備える。複数のメモリスロットがメモリバスと接続され、アダプタポートが複数のメモリスロットのうちの少なくとも一部と関連付けられ、アダプタポートの各々は、関連付けられたメモリリソースを含む。ダイレクト・エクセキューション・ロジック要素108は、アダプタポートのうちの少なくとも1つと接続される。メモリリソース110は、少なくとも1つの高密度ロジックデバイス及びダイレクト・エクセキューション・ロジック要素によって、選択的にアクセス可能である。
(もっと読む)
要求転送装置及び要求転送方法
【課題】スループットを維持しつつ、命令間の順序保証を行うこと。
【解決手段】本発明にかかる要求転送装置は、複数の要求元のそれぞれから、複数の要求先のいずれかが指定された複数の要求を含む要求群を受け付け、受け付けた要求群に含まれる各要求に対して、当該要求群を識別するための識別情報を付加し、識別情報を対応付けた複数の領域に予め分割され、複数の要求先に対応する複数のバッファのうち、各要求に指定された要求先に対応するバッファ内で付加された識別情報に対応付けられた領域へ各要求を格納し、複数のバッファのそれぞれから、識別情報に対応付けられた領域単位に、格納された要求を読み出し、読み出した要求を、当該要求に指定された要求先へ出力する。
(もっと読む)
バスシステムおよびそのデッドロック回避回路
【課題】スプリットトランザクションにより複数のスレーブへの同時アクセスを許容したシステムにおいて、デッドロックの発生を防止する。
【解決手段】先行トランザクション情報管理部410は、対応するマスタから複数のスレーブの何れかに先に発行された先行トランザクション情報を管理する。発行停止判定部420は、先行トランザクション情報に基づいて、対応するマスタから新たに発行されたトランザクションがデッドロックの要因になるか否かを判定する。レスポンス出力制御部430は、先行トランザクション情報に基づいて、対応するマスタへ返送すべきレスポンスを制御する。退避バッファ470は、先行トランザクションに対する複数のスレーブからのレスポンスが予め期待された順序とは異なる順序で戻ってきた場合に、そのレスポンスを退避する。
(もっと読む)
共有キャッシュメモリ装置
【課題】2個のプロセッサに、より高速に連携した処理を行わせることが可能な共有キャッシュメモリ装置を提供する。
【解決手段】共有キャッシュメモリ装置を、第1プロセッサが生成して第2プロセッサが利用するデータを記憶するための幾つかの監視対象記憶領域をデータメモリ部33に確保する機能、管理対象記憶領域毎に第1プロセッサによるデータの書き込みが行われたか否かを管理する機能、データの書き込みが完了していない監視対象記憶領域上のデータを要求するリード要求を受信したときに、その監視対象記憶領域へのデータの書き込みが第1プロセッサにより行われるのを待機してから、当該リード要求に応答する機能を有する装置として構成しておく。
(もっと読む)
共有メモリシステム及びその制御方法
【課題】処理時間の短縮及び消費電力の低減が可能な共有メモリシステムを提供すること。
【解決手段】共有メモリシステムは、アクセス監視機構112に対し、動画属性用のクラスタをクラスタメモリ1、2とする定義を行う。アクセス監視機構112は、DSP(2)104が画像の属性情報を付加してメモリアクセスを行うと、クラスタメモリ1、2に対してアクセス許可を示す制御情報131をクラスタメモリ空間選択装置119に出力する。クラスタメモリ空間選択装置119は、制御情報131に従って、DSP(2)104からのアクセスをクラスタメモリ1もしくは2に振り分ける。GPU105からのアクセスも同様である。複数のクラスタ111に分割された共有メモリ110を複数のマスタが共有することで、キャッシュメモリのコヒーレンシを保つ。
(もっと読む)
CPU間通信システム及びCPU間通信方法
【課題】CPU間通信において、同期の待ち時間に応じてウェイト処理を最適に制御できるようにする。
【解決手段】送信側CPUと受信側CPUとがメモリ104を介してデータ通信を行うCPU間通信システム800において、送信側CPUは、メモリ104に空き領域があるかを判定するメモリ領域判定部351と、空き領域がある場合に、メモリ104にデータを書き込むデータ書き込み部352と、空き領域がない場合に、受信側CPUの状態を判定する受信側CPU判定部353と、受信側CPUの状態がデータ読み出し処理の実行状態である場合に、メモリ104に空き領域ができるまでデータ書き込み部352を待ち状態とし、受信側CPUの状態がデータ読み出し処理の実行状態でない場合に、受信側CPUにデータ読み出し処理の実行を開始させるための読み出し開始要求を受信側CPUへ送信する送信側制御部354とを備える。
(もっと読む)
プロセッサーシステム
【課題】各デバイス間の通信を効率よく中継する。
【解決手段】マスターデバイス40とそれに対するスレーブデバイスとしての第1のスレーブデバイス50とを接続してデバイス間の通信を中継するクロスバースイッチ45と、マスターデバイス40および第1のスレーブデバイス50に対するスレーブデバイスとしての第2のスレーブデバイス60と第1のスレーブデバイス50とを接続してデバイス間の通信を中継する多段ブリッジ55とを備えて、クロスバースイッチ45と多段ブリッジ55との接続を介してマスターデバイス40と第2のスレーブデバイス60とを接続してデバイス間の通信を中継するから(経路(3))、各デバイス間の通信において通信対象となるデバイス以外のデバイスを経由する必要がなく、各デバイス間の通信を効率よく中継することができる。
(もっと読む)
データプロセッサ
【課題】プロセッサコアのローカルメモリや共有メモリの所要のアドレスに対して小さな回路規模で排他制御を行うことができるデータプロセッサを提供する。
【解決手段】要求に従ってバスロック設定と解除が可能にされるシステムバス(5)を共有する複数個のプロセッサコア(20,40)が相互に互いの内部リソース(22,42)を共有するデータプロセッサ(1)において、プロセッサコアが内部リソースの第1アドレス(ロック変数割り当てアドレス)へアクセスを行うときバスロックの要求を伴って当該アクセス要求をシステムバスに出力することによりシステムバスにバスをロックさせると共にシステムバスから当該プロセッサコアに帰還されるのを待って当該アクセス要求を処理し、プロセッサコアが内部の第2アドレスへアクセスを行うとき当該アクセス要求をプロセッサコアの内部で処理する。
(もっと読む)
1 - 20 / 109
[ Back to top ]