
Fターム[5B045EE03]の内容
Fターム[5B045EE03]に分類される特許
1 - 20 / 74
マルチプロセッサシステム、及びマルチプロセッサシステムの制御方法
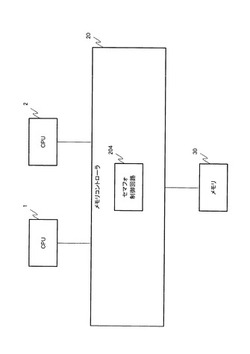
【課題】各CPU(プロセッサ)の処理負荷を軽減し、セマフォの使用効率を向上させたマルチプロセッサシステム、マルチプロセッサシステムの制御方法を提供すること
【解決手段】メモリ30は、CPU1及びCPU2からアクセスされる。セマフォ制御回路204は、CPU1、CPU2からメモリ30へのロック命令、アンロック命令を受信して、メモリ30の同期制御を行う。詳細には、セマフォ制御回路204は、ロックを行ったプロセッサがロック処理を行っている時間(ロック処理時間)をカウントする。また、セマフォ制御回路204は、ロック中にロック命令を送信したプロセッサの命令送信順序を保持し、算出済みのロック処理時間と、命令送信順序を基に、ロックに失敗した各プロセッサの待ち時間を算出して通知する。
(もっと読む)
プロセッサ、マルチプロセッサシステムおよびメモリ制御方法

【課題】ローカル命令メモリのサイズを実質的に拡大する形態でローカル命令メモリを各プロセッサ間で共有できるマルチプロセッサシステムにおけるプロセッサを提供する。
【解決手段】第1CPU100は、メモリ共有モード設定レジスタ107に格納された情報を参照することで、第1CPU100が命令フェッチを行うアドレスが、ローカル命令メモリ先頭アドレスレジスタ103とローカル命令メモリ終了アドレスレジスタ104とで定義される領域内であるか、または、共有命令メモリ先頭アドレスレジスタ105と共有命令メモリ終了アドレスレジスタ106とで定義される領域内であるかを判定し、その判定の結果に基づいてセレクタ102を制御することで、命令メモリ101と命令メモリ201とを切り替え、切り替え後の命令メモリから命令をフェッチして実行する。
(もっと読む)
ネットワークシステム
【課題】本発明は、重複書込領域への書込み可否の判定に要する時間を短縮し、かつネットワーク内の転送速度を速くすることが可能なネットワークシステムを提供することを目的とする。
【解決手段】本発明によるネットワークシステムは、複数の局の各々は、自局を含む複数の局のいずれかの局で重複書込領域LWへの書込みが行われているか否かを示す判別フラグLBとを有する分散共有メモリCMと、分散共有メモリCM外に保持されトークン50が自局に前回到着した際に自局が重複書込領域LWへの書込みを行ったか否かを示す権利フラグBdと、分散共有メモリCM外に保持されトークン50が自局に今回到着した際に自局が重複書込領域LWへの書込みを要求しているか否かを示す要求フラグBkと、判別フラグLB、権利フラグBd、および要求フラグBkのオン・オフ状態に基づいて重複書込領域LWへの書込可否を判定するフラグ判定部12a〜12cとを備える。
(もっと読む)
共有キャッシュメモリ装置
【課題】2個のプロセッサに、より高速に連携した処理を行わせることが可能な共有キャッシュメモリ装置を提供する。
【解決手段】共有キャッシュメモリ装置を、第1プロセッサが生成して第2プロセッサが利用するデータを記憶するための幾つかの監視対象記憶領域をデータメモリ部33に確保する機能、管理対象記憶領域毎に第1プロセッサによるデータの書き込みが行われたか否かを管理する機能、データの書き込みが完了していない監視対象記憶領域上のデータを要求するリード要求を受信したときに、その監視対象記憶領域へのデータの書き込みが第1プロセッサにより行われるのを待機してから、当該リード要求に応答する機能を有する装置として構成しておく。
(もっと読む)
共有メモリシステム及びその制御方法
【課題】処理時間の短縮及び消費電力の低減が可能な共有メモリシステムを提供すること。
【解決手段】共有メモリシステムは、アクセス監視機構112に対し、動画属性用のクラスタをクラスタメモリ1、2とする定義を行う。アクセス監視機構112は、DSP(2)104が画像の属性情報を付加してメモリアクセスを行うと、クラスタメモリ1、2に対してアクセス許可を示す制御情報131をクラスタメモリ空間選択装置119に出力する。クラスタメモリ空間選択装置119は、制御情報131に従って、DSP(2)104からのアクセスをクラスタメモリ1もしくは2に振り分ける。GPU105からのアクセスも同様である。複数のクラスタ111に分割された共有メモリ110を複数のマスタが共有することで、キャッシュメモリのコヒーレンシを保つ。
(もっと読む)
CPU間通信システム及びCPU間通信方法
【課題】CPU間通信において、同期の待ち時間に応じてウェイト処理を最適に制御できるようにする。
【解決手段】送信側CPUと受信側CPUとがメモリ104を介してデータ通信を行うCPU間通信システム800において、送信側CPUは、メモリ104に空き領域があるかを判定するメモリ領域判定部351と、空き領域がある場合に、メモリ104にデータを書き込むデータ書き込み部352と、空き領域がない場合に、受信側CPUの状態を判定する受信側CPU判定部353と、受信側CPUの状態がデータ読み出し処理の実行状態である場合に、メモリ104に空き領域ができるまでデータ書き込み部352を待ち状態とし、受信側CPUの状態がデータ読み出し処理の実行状態でない場合に、受信側CPUにデータ読み出し処理の実行を開始させるための読み出し開始要求を受信側CPUへ送信する送信側制御部354とを備える。
(もっと読む)
半導体装置
【課題】複数のバスマスタを備えた半導体装置において、バススレーブに対する処理を従来よりも効率的に実行できる半導体装置を提供する。
【解決手段】半導体装置100において、各マスタ装置M0〜Mnは、複数のバスB0〜B4に接続され、複数のバスのうちの割当てられた1本のバスを介してスレーブ装置30に対する処理要求をコントローラ20に出力する。複数のマスタ装置M0〜Mnの各々には割当優先度が定められる。調停回路11は、複数のマスタ装置M0〜Mnのうちバスの割当を要求している1または複数のマスタ装置に対して、バスの割当を要求したタイミングと割当優先度とに基づいて不使用のバスを割当てるとともに、バスを割当てたマスタ装置の処理要求に対して処理順位を設定する。コントローラ20は、バスが割当てられたマスタ装置から受けた処理要求の内容と処理順位とに基づいて、スレーブ装置30に対して処理を実行する。
(もっと読む)
マルチコア・プロセッサ
【課題】共有アクセス対象へのアクセスに関する調停を確実に行うことが可能なマルチコア・プロセッサを提供すること。
【解決手段】複数のプロセッサコアによって読み書き可能なメモリ上に、特定の共有アクセス対象に対するアクセスの内容及び順序を規定するためのメッセージキューが設定され、複数のプロセッサコアは、メッセージキューに対する所定の書き込み制御に応じて自己が実行すべきタスクに含まれる処理のうち特定の共有アクセス対象に対するアクセスを含む処理に関するジョブ情報を排他的にメッセージキューに書き込み、複数のプロセッサコアのうち少なくとも一の特定対象アクセス実行用プロセッサコアは、メッセージキューに書き込まれたジョブ情報に従って特定の共有アクセス対象に対するアクセスを含む処理を実行することを特徴とする、マルチコア・プロセッサ。
(もっと読む)
信号制御装置及び信号制御方法
【課題】2つのCPUがデュアルポートRAMに同じタイミングで読出し又は書込みを行う場合に、データ信号を正しく読出すこと。
【解決手段】信号制御装置4は、第1及び第2のCPUがデュアルポートRAM5に書き込むアドレスの衝突を検出するアドレス衝突検出部14を備える。また、アドレスの衝突が検出された場合に、デュアルポートRAM5に書込みを行う第1又は第2のCPUのいずれかに設けられたバッファメモリに、衝突したアドレスから読出したデータ信号を保存する制御を行う制御部13を備える。また、第1及び第2のCPUの読出し可能状態又は書込み可能状態に応じて、データ信号の読出し元であるレジスタ又はバッファメモリを切替えて、読出し可能状態となるCPUに読出した前記データ信号を出力するマルチプレクサ15a,15bを備える。
(もっと読む)
計算機システム
【課題】 高密度実装するサーバモジュールのメモリ容量の増設を容易にする。
【解決方法】 メモリ容量を追加するためのメモリ増設モジュールをサーバシステムに備えることにより、サーバブレードのCPUには通常のメモリと認識可能な外部メモリの増設手段を持ち、複数のサーバブレードで1つのモジュールを共有することにより、複数のサーバブレードのメモリ容量を増設が可能なサーバシステム。
(もっと読む)
情報処理装置
【課題】アクセラレータが使用するローカルメモリに対するデータの入れ替え処理のオーバヘッドを大幅に低減し、アクセラレータによる演算処理を高速化する。
【解決手段】ローカルメモリ5を複数バンク5a〜5cに分割し、各バンクを切り替えて使用し、アクセラレータ3のコンフィギュレーションは変更せずに別のバンクをアクセス可能とする。コンフィギュレーションがプログラムの場合は演算の終了時に、この切り替えのタイミングが発生する。アクセラレータ3の状態を示す機能レジスタにどのバンクをCPUが使用しているかの情報を保持し、使用中であればアクセラレータ3は実行を保留し、使用しなくなり次第割り当てられたバンクで起動する。各バンクはアクセラレータ3の機能レジスタの情報に基づいて演算器と結びつけられる。演算の切れ目でバンクの切り替えを発生させ、演算器と結びつくバンクを別のものに切り替える。
(もっと読む)
並列処理システム制御装置、その方法及びそのプログラム
【課題】並列処理システムを制御するための並列処理システム制御装置であって、並列処理システムの各プロセッサ及び各共有メモリの差異を隠蔽し、アプリケーションプログラムから統一的に並列処理システムを制御する並列処理システム制御装置を提供する。
【解決手段】固有のプロセッサに依存しない共通コマンドを解析してアプリケーションプログラム40の各部分処理を実行する各プロセッサを特定し、各部分処理の入出力データ用のバッファが格納された共有メモリを特定し、各プロセッサが入出力データ用のバッファをアクセスするためのアドレスを特定し、共通コマンドを各プロセッサへの個別のコマンドであるプロセッサ個別コマンドに変換し、並列処理システムを実行制御するための、共通コマンド変換・メモリ管理部、個別実行制御部、メモリ管理情報、個別実行制御登録部と、を備える。
(もっと読む)
アトミックなセマフォ操作を行う方法および装置
【課題】処理システムと、処理システム内で通信する方法において、セマフォへのアトミックなアクセスを、バスプロトコルの枠組み内で、追加のハードウェアを最少にして、性能を劣化することなく、実施する技術を提供する。
【解決手段】処理システムは、バスと、バスに連結されたメモリ領域と、バス上でメモリ領域へアクセスする複数の処理構成要素とを含み、各処理構成要素が、セマフォ操作を行って、バス上でのセマフォ位置への読み出し動作および書き込み動作を同時に要求することによって、メモリ領域へのアクセスを得るように構成される。
(もっと読む)
画像形成装置
【課題】画像形成装置において、不揮発性メモリを2つのCPUで共有させると共に、2つのCPUから不揮発性メモリへのアクセスを簡単な回路で調整できるようにする。
【解決手段】画像形成プロセス制御を行う第1CPU1と、通信制御を行う第2CPU2と、第1CPU1及び第2CPU2で共有するEEPROM4と、第1CPU1及び第2CPU2の一方を不揮発性メモリ4に直接アクセス可能とするセレクタ3とを設ける。そして、第1CPU1と第2CPU2との間で通信可能とし、通常状態では、第1CPU1がEEPROM4に直接アクセス可能とするとともに、第2CPU2は、第1CPU1を介してEEPROM4にアクセス可能とする。一方、第1CPU1が作動を停止した省電力状態又は第1CPU1が動作異常状態では、セレクタ3によって第2CPUがEEPROM4に直接アクセス可能となるようする。
(もっと読む)
データ処理装置、印刷システムおよびプログラム
【課題】CPUとGPUとの間で、大量のデータを効率良く処理する。
【解決手段】複数の処理を非同期で並列に実行可能なデバイス3と、このデバイス3との間でデータの授受を行うホスト2とを有し、ホスト2には、システムメモリ12内にデバイス3との間でデータ転送を行うためメモリ領域が確保され、デバイス3は、ホスト2からのデータを処理している間に並列してメモリ領域へのアクセスを行ってデータ転送を行い、ホスト2では、デバイス3に転送するデータを3以上に分割し、分割された2番目以降のデータについて、デバイス3で前回のデータが処理されている間に、メモリ領域への書き込みを行う。
(もっと読む)
インターフェース装置、演算処理装置、インターフェース生成装置、および回路生成装置
【課題】演算装置同士を最小の記憶素子数で接続することが可能で、キャッシュメモリに記憶するデータ数を最小にしても確実にアドレス指定によるデータ転送を行えるようにする。
【解決手段】バッファに保存した書込みデータを書込みアドレスの順序に並び替えてストリームデータとして出力するストリーム変換装置130と、キャッシュメモリ140と、読出しに関するアドレス情報で指定されたデータがキャッシュメモリに既にロードされているかを判定し、ロードされていない場合には、ロード信号を出力し、ロードアドレスを出力する制御装置150と、ロードアドレスを用いて、読出しアドレスで指定されたデータがキャッシュメモリのどの記憶素子に保存されているかを求め、求めた値をキャッシュアドレスとしてキャッシュメモリに出力し、キャッシュメモリから入力されたキャッシュデータを読出しデータとして出力するアドレス変換装置160と、を有する。
(もっと読む)
演算制御装置、マイクロプロセッサ及び機器
【課題】プロセッサ内蔵する演算装置において、新メモリ登場などによりますます顕在化する、複数の演算装置間の待合せ時間における消費電力及び演算能力の浪費の削減と、演算装置のコンテキストスイッチ負荷の削減が課題である。
【解決手段】マイクロプロセッサと、マイクロプロセッサに接続されたメモリとを備える機器に備わる演算制御装置であって、マイクロプロセッサは、複数の演算部を備え、メモリは、複数の演算部が読み書き可能な共有記憶領域を含み、演算制御装置は、共有記憶領域への書き込みができるか否かを検出する書込検出部を備え、演算部が共有記憶領域に書き込みができない場合、共有記憶領域を監視し、演算部の稼動を停止することを特徴とする。
(もっと読む)
記憶装置への情報蓄積制御方法
【課題】 キューのオーバフローを防止する情報蓄積制御方法を提案する。
【解決手段】 処理要求を順次記憶する第1の記憶手段と、前記第1の記憶手段に記憶可能な処理要求の数を超えない値に設定されたセマフォ変数を記憶する第2の記憶手段と、前記第1の記憶手段に記憶された処理要求についての処理完了に応じて処理結果に関するデータを順次記憶する記憶手段であって、前記第1の記憶手段に記憶可能な処理要求の数以上の数の前記データを格納可能な第3の記憶手段と、前記処理要求の前記第1の記憶手段への記憶に応じて、前記セマフォ変数を1減少させ、前記第3の記憶手段からの前記データの読み出しに応じて前記セマフォ変数を1増加させる処理を行う処理手段とを備え、前記第1の記憶手段への更なる処理要求の記憶は、前記セマフォ変数の値が正であることを条件に行われる、ことを特長とする情報処理装置。
(もっと読む)
ハードウェアデバイスをヘテロジニアス処理ユニット間でバインドし移行するためのチップセットサポート
【課題】コンピュータシステム内に含まれる他のプロセッサとの競合を引き起こすことなしにハードウェアデバイスに対する、プロセッサによるアクセスを可能とする方法をていきょうすること。
【解決手段】この方法は、第1のプロセッサから第1のアドレスマップを、また第2のプロセッサから第2のアドレスマップを受け取るステップであり、各アドレスマップは、プロセッサがアクセスするように構成されているハードウェアデバイスのセットのためのメモリマップド入出力アパーチャを含む、ステップと、第1と第2のアドレスマップを組み合わせることによってグローバルアドレスマップを生成するステップと、第1のプロセッサから第1のアクセス要求を受けるステップと、グローバルアドレスマップ内に含まれるアドレスマッピングに基づきハードウェアデバイスに第1のアクセス要求をルーティングするステップとを含む。
(もっと読む)
ヘテロジニアス処理ユニット間での不均一メモリアクセスのためのチップセットサポート
【課題】第2のプロセッサに関連付けられたメモリに第1のプロセッサがアクセスすることを可能にするための方法を提供すること。
【解決手段】この方法は、第1のプロセッサから、NUMAデバイスのためのMMIOアパーチャを含む第1のアドレスマップを受け取るステップと、第2のプロセッサから、ハードウェアデバイスのためのMMIOアパーチャを含む第2のアドレスマップを受け取るステップと、第1のアドレスマップと第2のアドレスマップを組み合わせることによってグローバルアドレスマップを生成するステップと、第1のプロセッサからNUMAデバイスに送られたアクセス要求を受け取るステップと、第1のアクセス要求と変換テーブルとに基づいて、メモリアクセス要求を生成するステップと、グローバルアドレスマップに基づいて、メモリアクセス要求をメモリにルーティングするステップとを含む。
(もっと読む)
1 - 20 / 74
[ Back to top ]