
Fターム[5B045GG14]の内容
マルチプロセッサ (2,696) | プログラム、命令の実行処理 (212) | 並列処理 (89) | SIMD (12)
Fターム[5B045GG14]に分類される特許
1 - 12 / 12
画像音声信号処理装置及びそれを用いた電子機器
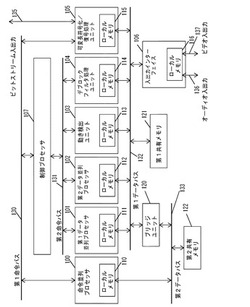
【課題】 MPEG−4 AVCの符号化/復号処理のような、大量のデータ処理量が要求される画像処理に対して、高性能で、高効率な画像処理が行える信号処理装置及びそれを用いた電子機器を提供する。
【解決手段】 信号処理装置は、命令並列プロセッサ100、第1データ並列プロセッサ101、第2データ並列プロセッサ102、及び、専用ハードウェアである動き検出ユニット103とデブロックフィルタ処理ユニット104と可変長符号化/復号処理ユニット105とを備える。この構成により、処理量の多い画像圧縮伸張アルゴリズムの信号処理において、ソフトウェアとハードウェアで負荷が分散され高い処理能力と柔軟性を実現した信号処理装置、及びそれを用いた電子機器を提供出来る。
(もっと読む)
画像処理装置、画像形成装置及びプログラム

【課題】画像データに対する非線形処理の効率を向上させることができる画像処理装置、画像形成装置及びプログラムを提供する。
【解決手段】画像データの一部の画素値と、該画像データの一部とは異なる部分の画素値とを比較する比較手段と、前記比較手段による比較の結果に応じて、前記画像データに非線形処理を施す非線形処理手段とを有する。前記非線形処理手段は、前記比較手段による比較の結果、前記画像データの一部の画素値と、該画像データの一部とは異なる部分の画素値とが同じである場合、前記画像データの一部と、該画像データの一部とは異なる部分とに同じ非線形処理を施す。
(もっと読む)
プロセッサアレイ及びその形成方法
【課題】プロセッサの並列アレイ内の処理エレメント間に高度の接続性を提供し、同時に、処理エレメントを相互接続するために必要な配線を最小限化し、かつPE間通信が遭遇する通信待ち時間を最小限化することが可能な重プロセッサアレイのアーキテクチャを提供する。
【解決手段】マニフォルドアレイトポロジは、クラスタ内に配列された処理エレメント、ノード、メモリ等を含む。クラスタは、処理エレメントを物理的に再配列することなく、組織の有利な変更を可能にするクラスタスイッチ配置構成986Aによって接続される。既存アレイ用の相互接続部の一般的な個数をかなり減少させることも達成される。容易なスケーラビリティの追加利益を伴い、高速、効率的、かつコストの点でも効果的な処理および通信が得られる。
(もっと読む)
画像処理装置
【課題】複数のプロセッサ要素を1次元に結合してなる分散メモリ型プロセッサアレイを備えた画像処理装置により、1行の画素数がプロセッサ要素数より多い画像を処理する場合の効率向上を図る。
【解決手段】画像処理プロセッサ100は、複数個のプロセッサ要素をリング状に1次元に結合してなる分散メモリ型プロセッサアレイ120を備え、処理対象の画像の1行の画素数がプロセッサ要素数より大きいときに、該画像を折り畳んでプロセッサ要素のローカルメモリに格納する。各プロセッサ要素のメモリアクセス制御部は、ローカルメモリアクセスにより画像の所定の行に含まれる画素に対する読出要求があった際に、ローカルメモリに格納された、上記所定の行の全ての画素をローカルメモリから読み出すことが可能である。なお、ローカルメモリアクセスは、プロセッサアレイ120内部に生じるメモリアクセスである。
(もっと読む)
単一パステセレーション
【課題】 テセレーションシェーダープログラムを実行するための改良されたシステム及び方法を提供する。
【解決手段】 グラフィックプロセッサを通して単一パスでテセレーションを実行するシステム及び方法は、グラフィックプロセッサ内の処理リソースを、異なるテセレーションオペレーションを実行するためのセットへと分割する。頂点データ及びテセレーションパラメータは、メモリに記憶されるのではなく、1つの処理リソースから別の処理リソースへ直接ルーティングされる。それ故、表面パッチ記述がグラフィックプロセッサに与えられ、そしてメモリに中間データを記憶せずに、グラフィックプロセッサを通して単一の非中断パスでテセレーションが完了される。
(もっと読む)
プロセッサアレイ及びその形成方法
【課題】プロセッサの並列アレイ内の処理エレメント間に高度の接続性を提供し、同時に、処理エレメントを相互接続するために必要な配線を最小限化し、かつPE間通信が遭遇する通信待ち時間を最小限化する。
【解決手段】マニフォルドアレイトポロジは、クラスタ52内に配列された処理エレメント、ノード、メモリ等を含む。クラスタは、処理エレメントを物理的に再配列することなく、組織の有利な変更を可能にするクラスタスイッチ配置構成986Aによって接続される。既存アレイ用の相互接続部の一般的な個数をかなり減少させることも達成される。容易なスケーラビリティの追加利益を伴い、高速、効率的、かつコストの点でも効果的な処理および通信が得られる。
(もっと読む)
パーティションフリーマルチソケットメモリシステムアーキテクチャ
【課題】アプリケーションのメモリ帯域幅を増大させる技術を提供する。
【解決手段】少なくとも2つのメモリに接続される少なくとも2つのプロセッサを有する装置であって、前記少なくとも2つのプロセッサの第1プロセッサは、前記少なくとも2つのメモリの第1メモリに格納されているデータの第1部分と、前記少なくとも2つのメモリの第2メモリに格納されているデータの第2部分とをクロック信号期間の第1部分内で読み、前記少なくとも2つのプロセッサの第2プロセッサは、前記少なくとも2つのメモリの第1メモリに格納されているデータの第3部分と、前記少なくとも2つのメモリの第2メモリに格納されているデータの第4部分とを前記クロック信号期間の第1部分内で読む。
(もっと読む)
プロセッサ
処理装置は、各々が1つのインストラクションを実行するよう構成された複数のプロセッサ12と、該プロセッサ間においてデータトークンとコントロールトークンを伝送するためのバス20とを備える。各プロセッサ12は、バスを介してコントロールトークンを受け取ると、そのインストラクションを実行し、インストラクションを実行する際にデータに対して演算を行い、そのデータ対象プロセッサとなるプロセッサ12を特定し、該特定されたデータ対象プロセッサに対して出力データを送信したり、また、コントロール対象プロセッサプロセッサを特定し、該特定されたコントロール対象プロセッサにコントロールトークンを伝達するように配置されている。  (もっと読む)
(もっと読む)
自律または共通制御されるPEアレイを有するシステムのためのデータ転送ネットワークおよび制御装置
SIMD/MIMDデュアルモードのアーキテクチャプロセッサは、共通制御される第1のプロセッシングエレメント(PE)群と、自律制御される第2のプロセッシングエレメント群と、前記第1、第2のPE群を順次接続するパイプラインネットワークと、を備える。アクセスコントローラは、前記第1、第2のPE群の各PEにそれぞれ接続されたアクセス制御線を有し、前記各PEと前記パイプラインネットワークとの間のデータアクセスタイミングを制御する。各PEは、SIMD/MIMDデュアルモードのアーキテクチャプロセッサのように自律制御または共通制御することが可能である。配線エリア要件を緩和する。  (もっと読む)
(もっと読む)
並列プロセッサ及びそれを用いた画像処理装置
【課題】 この発明は、駆動回路において大きな駆動力を必要とせず且つ、制御信号線の配線遅延が生じない並列プロセッサを提供することを目的とする。
【解決手段】 グローバルプロセッサ2で発生したプロセッサエレメント制御信号を、任意のPE単位(GPE)のローカル信号発生部50に供給されるグローバル制御信号(GCS)と、ローカル信号発生部50でバッファされ、任意のPE単位(GPE)に含まれるPE3aのみ供給されるローカル制御信号(LCS)に制御信号を分割する。
(もっと読む)
情報処理システムおよび情報処理方法
分散メモリ型において、単一命令により種々のメモリに記憶された配列中の要素を入出力し、処理と通信を統合する。隣接するPMM12の間には、一方から他方にパケットを伝達する第1のパケット伝送路14、および、他方から一方にパケットを伝達する第2のパケット伝送路16を備える。各PMMは、各々が項目と当該項目に属する項目値とを含むレコードの配列として表される表形式データを表現するための、特定の項目に属する項目値に対応した項目値番号の順に当該項目値が格納されている値リスト、および、一意的な順序集合配列の順に、当該項目値番号を指示するためのポインタ値が格納されたポインタ配列からなる情報ブロックを保持し、各メモリにて保持された情報ブロックの集合体により、グローバルな情報ブロックが形成される。  (もっと読む)
(もっと読む)
処理管理装置、コンピュータ・システム、分散処理方法及びコンピュータプログラム
【課題】 ネットワークに接続されている複数の処理装置とこれらの処理装置を管理する処理管理装置とで分散処理を行う際の処理管理装置のオーバーヘッドを回避する。
【解決手段】 傘下の複数の処理装置(SPU)207等を管理する処理管理装置(PU)203が、SPU207等と、ネットワークに接続されている他のSPUに対するネットワークアドレス及び当該SPUの現在のタスク実行能力を表すリソース情報をリソースリストにリストアップしておく。いずれかのSPUがPU203に対してタスク要求を送信すると、PU203は、タスク要求を遂行可能な1又は複数のSPUをリソースリストより特定し、特定したSPUに、その実行結果の指定先を含むタスクの実行を依頼することにより、PU203を介在させない実行結果の受け渡しを可能にする。
(もっと読む)
1 - 12 / 12
[ Back to top ]