
Fターム[5B075NK33]の内容
検索装置 (67,127) | 検索キー情報 (8,147) | 検索キー情報の自動抽出 (2,419) | 自然言語解析による検索キーの抽出 (1,229) | 不要語辞書 (35)
Fターム[5B075NK33]に分類される特許
1 - 20 / 35
情報端末装置、情報検索方法、情報検索プログラム
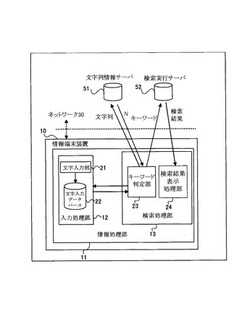
【課題】ユーザにとって無駄な情報の提示を防ぐこと。
【解決手段】本発明の情報端末装置は、文字入力部と、前記文字入力部からの入力に基づいて文字列を登録する文字列記憶部と、所定のタイミングで、前記文字列記憶部に登録された文字列を候補文字列として、第1のサーバに送信し、送信した候補文字列の検索回数又は関連語の数を前記第1のサーバから受信する送受信部と、前記第1のサーバから受信した候補文字列の検索回数又は関連語の数に基づいて、候補文字列を第2のサーバに送信して関連する情報の検索を行うか否かを判定する検索実行判定部と、を備える。
(もっと読む)
発言制御装置およびコンピュータプログラム

【課題】 NGワードやNGセンテンスを事前に把握して、仮想空間へアップさせない技術を提供する。
【解決手段】 過去のNGワードやNGセンテンスに関するデータを随時蓄積するNG発言データベースと、 言語解析手段と、 NGワードやNGセンテンスを検知するためのNGフィルタを生成するフィルタ生成手段と、 前記ユーザの発言データを受信する発言データ受信手段と、 その発言データに前記NGワードやNGセンテンスを含むか否か前記NGフィルタを用いてフィルタリングするフィルタリング手段と、 当該発言データがNGワードやNGセンテンスを含む場合には、その旨を報告するためのNG報告データを当該発言データに係るユーザの法的責任者に係る情報端末へ送信するNG報告手段と、を備えた発言制御装置とする。
(もっと読む)
情報分類システム、情報分類方法及びプログラム
【課題】不要語・重要語を自動的に導出しクラスタリングを行なうことにより、利用者にとって有益な分類結果を生成する。
【解決手段】情報分類システムによれば、文書データにおける第一の特定範囲および第二の特定範囲のテキスト情報に関して、各特定範囲に含まれる各単語の相関関係に基づいて重要語または不要語を抽出する重要語・不要語抽出処理部と、記憶装置に記憶された各文書データについて各特定範囲の重要語または不要語に基づいてクラスタリングを行うクラスタ生成処理部とを実行する処理装置を備える。
(もっと読む)
検索キーワード辞書に対する非検索キーワード辞書を用いた文章検索プログラム、サーバ及び方法
【課題】例えば予め登録されたキーワードによって違法・有害なカテゴリに属するか否かを判定する際に、違法・有害でない文章情報が、違法・有害なカテゴリに分類されることをできる限り減らすことができる文章分類プログラム、サーバ及び方法を提供する。
【解決手段】特定カテゴリに属さない複数の正当学習文章情報と、特定カテゴリに属する複数の不当学習文章情報とを蓄積した学習文章蓄積手段を有し、検索キーワードを含む学習文章情報を検索し、その検索キーワードに対する係り受けキーワードを抽出し、係り受けキーワード毎に、全ての学習文章情報の数に対する正当学習文章情報の数の正当割合を算出し、正当割合が所定閾値以上となる係り受けキーワードを非検索キーワードとして登録する非検索キーワード辞書を生成する。これにより、検索キーワードに対する係り受けキーワードとして非検索キーワードが含まれている文章情報は検索されないようにする。
(もっと読む)
専門用語抽出装置およびプログラム
【課題】コミュニティ内のメンバーの発言をもとに、一般用語を除外して個人を特徴づけるキーワードを抽出する。
【解決手段】専門用語抽出装置1は、投稿者の操作に応じて入力された文書を形態素解析する形態素解析部20と、文書に含まれる単語間、単語と投稿者との間、単語と該投稿者が属する投稿先グループとの間の偏りスコアを計算する偏りスコア計算部30と、偏りスコアの値応じて、文書に含まれている一般用語を抽出する一般用語抽出部40と、一般用語抽出部40により抽出された一般用語を文書から除いて、個人の特徴を示すキーワードを抽出するインデックス抽出部50と、を備える。
(もっと読む)
トピック具体表現辞書作成システム、トピック具体表現辞書作成方法及びそのプログラム
【課題】不要語辞書を効率的に作成し、かつ、抽出もれの少ない強化語リストを作成する。
【解決手段】対象トピック観点と、テキストの中で対象トピック観点について記述されている範囲とから、対象トピック観点に対応する具体表現辞書に登録する可能性のある候補のリストである「候補語リスト」を作成する。具体表現辞書と係り受けルールとを使って、具体表現辞書に登録されている単語を含む2単語の係り受け関係を抽出し、係り受け関係を基に不要語を抽出するためのルールを作成し、具体表現辞書に登録されていない単語を不要語として抽出し、不要語辞書に格納する。対応する候補語リストと、対応する不要語辞書とをつきあわせ、候補語リストから、不要語辞書に登録されている単語を削除し、削除されなかった単語は強化語リストに追加する。対象トピック観点に対応する強化語リストを対応する具体表現辞書に追加する。
(もっと読む)
文書データ分析プログラム及びコンピュータによる文書データ分析方法並びに文書データ分析システム
【課題】文書データに含まれている内容を正しく抽出する。
【解決手段】文書データ分析プログラム17は、コンピュータに、データベースに記憶されており文書を構成する文書要素のうち使用期間が所定の基準より短い文書要素とその性質を示すマスクデータとを関連付けた第1の定義辞書15を参照し、コンピュータによって取得された分析対象の文書データに含まれている文書要素のうち第1の定義辞書15に含まれている文書要素をその文書要素に関連するマスクデータに変換するマスク概念抽出機能14と、データベースに記憶されており使用期間が所定の基準より長い文書要素とその属性データとを関連付けた第2の定義辞書16を参照し、マスク概念抽出機能14によって変換された後の文書データに含まれておりかつ第2の定義辞書16に含まれている複数の文書要素とその属性データとを抽出する概念抽出機能3とを実現させる。
(もっと読む)
オブジェクト量的表現方法
【課題】デジタルドキュメントをベクトル空間内に数値を用いて表現する。
【解決手段】複数のデジタルドキュメントから、処理されるべき第1のデジタルドキュメントを識別し、デジタルドキュメントに含まれる画像を取り囲みかつアンカーテキストではないテキストを備えると共に第1のデジタルドキュメントに対応する第1の特徴を、複数のデジタルドキュメントから抽出する。第1の特徴を第1のベクトルへ変換し、第1のベクトルを第1のデジタルドキュメントに関連付ける。
(もっと読む)
コンテンツナビゲーションプログラム
【課題】 現在多くのユーザが関心を寄せている情報の検索を容易に行うことができるようにする。
【解決手段】 ユーザがキーワード6aに基づいた検索を行い検索結果6bの中から任意のコンテンツ7bを選択する度に、格納手段1aにより、検索用のキーワード6aと選択されたコンテンツ7bとが、関連付けて記憶手段1bに格納される。その後、グループ化手段1cにより、キーワードと選択されたコンテンツとの対応関係に基づいて、記憶手段1bに格納されたキーワード間の関連性が判定され、関連する複数のキーワードがグループ化される。そして、任意の代表キーワード8aが選択されると、関連キーワード出力手段1dにより、選択された代表キーワード8aと同じグループに属する他の関連キーワード8bが出力される。
(もっと読む)
情報検索装置および情報検索方法
【課題】検索キーワードに対して間接的に関係するキーワードによって番組を検索すること
【解決手段】番組関連情報取得部201が取得した番組関連情報に記述される出演者情報から、属性判定部203は人名や所属団体名などを示す単語を抽出して辞書部222を更新し、関係学習部204は当該抽出された人名や所属団体名の関係を学習して辞書部222を更新する。さらにOSD生成部212が生成した検索キーワード提示画面に番組検索のための検索キーワードが入力されると、関連検索単語抽出部211は入力された検索キーワードに関連する単語を辞書部222から抽出して検索キーワード提示画面に提示する。そして番組検索部213は検索キーワード提示画面に提示された単語に基づいて番組を検索する。
(もっと読む)
不要語決定装置及びプログラム
【課題】不要語であるか否かを決定するための閾値を用いることなく、不要語を決定することができるようにする。
【解決手段】パラメータ学習部14によって、学習用文書データに対する尤度を最大にする、学習用文書データに含まれる単語群の各単語のトピック毎の出現確率を学習して探索する。単語分類部16によって、単語群の各単語を、出現確率が最も高くなるトピックに分類する。不要語決定部20によって、全てのトピックに対する出現確率の各々が予め定められた範囲内となり一様に分布する単語が分類されたトピックの単語群を、不要語として決定する。
(もっと読む)
テキストマイニング方法、テキストマイニング装置、及びテキストマイニングプログラム
【課題】解析に利用する文字列にノイズとなる文字列が含まれる可能性を低減し、精度の高いテキストマイニングを可能とする。
【解決手段】データ処理部11は、デキストデータ記憶部12に記憶したテキストデータから複数の文字列を抽出し、カテゴリー毎の出現頻度を算出する。また、抽出した文字列に対応するカテゴリーが、記憶されたテキストデータそれぞれにおいて同時に使用されている比率である同時利用率を算出する。そして、出現頻度と同時利用率を利用して、因子分析対象とするカテゴリーを選択し、因子分析を行う。
(もっと読む)
文書データのノイズ除去システム
【課題】キーワードの自動的抽出の前処理として、種々雑多な文書データから不要な文字列を自動的に削除する技術の実現。
【解決手段】第1のノイズ除去後文書DB46から文書データを読み、各文書データの各行について英数字等の占める割合である英数字等濃度を算出し、この英数字等濃度と閾値Dとを比較し、英数字等濃度が閾値D以上である場合に当該行をノイズ行であると判定し、各文書データから削除する英数字等ノイズ除去部48を備えた文書データのノイズ除去システム40。
(もっと読む)
情報処理装置、情報処理方法、およびプログラム
【課題】番組情報から流行番組を簡単に抽出するようにする。
【解決手段】キーワード抽出部52は、番組情報受信部51で受信された番組情報の中からキーワードを抽出する。キーワード集計部55は、抽出されたキーワードの1週間分のキーワード数を集計する。差分演算部56は、今週のキーワードの集計結果と先週のキーワードの集計結果との差分を演算する。流行キーワード抽出部57は、今週と先週のキーワード数の差分が大きい順に所定の個数のキーワードを抽出し、これを今週の流行キーワードとする。本発明は、ハードディスクレコーダに適用することができる。
(もっと読む)
ユーザ入力に応じた検索空間の絞り込み
【課題】データのコーパスは大量の情報を保持し、関連する情報を見つけるのは困難である。文書にはタグを付けて関連情報の検索を容易にすることができる。しかし、場合によっては、いままでの文書タグ付け方法は情報を見つける際に効果的でないことがある。
【解決手段】一実施形態では、コーパスの検索空間を検索して結果を求める。コーパスはキーワードと関連付けられた文書を含み、各文書は、それの少なくとも1つのテーマを示す少なくとも1つのキーワードと関連づけられている。1つまたは複数のキーワードを無関係キーワードであると決定する。その無関係キーワードにより検索空間を改良する。
(もっと読む)
情報提供サーバ及び情報提供方法
【課題】検索キーワードとなる単語リストデータをクライアント端末に提供する。
【解決手段】情報提供サーバ1は、検索キーワードとなる複数の単語を収集し、記憶装置107の単語リストデータ記憶部107aに挿入する新規単語収集部101aと、単語リストデータ記憶部107aに記憶された単語リストデータを、クライアント端末2a等に配信する単語リスト配信部107bと、クライアント端末2a等から、単語リストデータの単語が使用された履歴を取得して、記憶装置107の履歴データ記憶部107bに記憶する履歴取得部101cと、履歴データ記憶部107bを参照して、単語リストデータ記憶部107aから単語を削除する不要単語削除部101dとを備える。
(もっと読む)
テキストの多重トピック抽出装置、テキストの多重トピック抽出方法、プログラム及び記録媒体
【課題】学習データを必要とせずに、トピックを得ることができ、しかも、極めて広い範囲からトピックを得ることができ、常に安定したトピック推定精度を得ることができるテキストの多重トピック抽出装置を提供することを目的とする。
【解決手段】入力したテキストを、文単位に分解するテキスト分解部と、上記テキスト分解部が分解した文を形態素解析し、解析された形態素のうちで、名詞を検索語として抽出する検索語抽出部と、上記検索語抽出部が抽出した検索語によってウェブ検索し、検索されたテキストを形態素解析し、この解析された形態素のうちで、名詞を関連語として取得する関連語取得部と、検索語と関連語とを組み合わせてキーワード集合を生成し、複数のキーワード集合に共通して現われる単語であるトピックを、キーワード集合を用いて抽出するトピック抽出部とを有するテキストの多重トピック抽出装置である。
(もっと読む)
ユーザーの潜在的な関心情報へのアクセスを提供する方法及びシステム
【課題】 ユーザーの潜在的な関心情報へのアクセスを提供する方法及びシステムを提供する。
【解決手段】 閉鎖字幕情報は、インターネットで関連した情報を探すために分析され、閉鎖字幕情報を含むプログラムを受信するテレビジョンとユーザーとの相互作用は、ユーザーの関心を決定するためにモニタリングされ、関連した閉鎖字幕情報は、キー情報を決定するために分析され、キー情報は、インターネットのような利用可能な資源で情報を探索するのに使われ、探索結果は、ユーザーの関心情報をユーザーに推薦するのに使われる。
(もっと読む)
構造化文書データベース管理システム及びプログラム
【課題】構造化文書に含まれる空白文字のうち整形用の空白文字のみを索引の構成時に取り除くことにより、文書として意味をなす単語による索引を構築できるようにする。
【解決手段】第1の空白文字判定部531は、構文解析部52によって検出された構造化文書中のテキストが空白文字のみから構成されるイグノラブル空白文字である場合、当該空白文字を整形用空白文字であるとして、後続する開始タグを含む次の要素の構造情報と対応付けて空白文字情報蓄積部55に蓄積する。第2の空白文字判定部532は、テキスト中の空白文字列及び当該空白文字列と関連した構造の構造情報を空白文字情報蓄積部55に蓄積されている情報と比較することにより、当該空白文字列が整形用空白文字であるかを判定する。索引作成部56は、整形用空白文字であると判定された空白文字をテキストから削除して、当該テキストを含む構造化文書の検索に用いられる索引を作成する。
(もっと読む)
非対称署名生成を使用するドキュメント照合エンジン
入力ドキュメントをドキュメント保管庫からの一組のドキュメントに対して照合する自動化された方法。一組のドキュメントのそれぞれについて、ドキュメント識別子、及び第1の署名発生器(215-A)により生成された署名を含む署名データベース(224)を記憶する。入力ドキュメントを受け取り、第2の署名発生器(215-B)を使用して、入力ドキュメントに対して署名を生成し、入力ドキュメントに対して生成された署名を使用して、署名データベースを検索する。第1の署名発生器(215-A)、及び第2の署名発生器(215-B)は、同一ドキュメントに対して異なる数の署名を生成するように構成される。他の実施形態、態様、及び機能も開示する。  (もっと読む)
(もっと読む)
1 - 20 / 35
[ Back to top ]