
Fターム[5B075NR20]の内容
Fターム[5B075NR20]に分類される特許
1 - 20 / 151
具体主題の有無判定装置、方法、及びプログラム
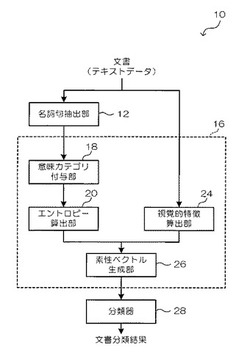
【課題】文書が具体主題を有するか否かを判定する。
【解決手段】名詞句抽出部12で、具体主題の候補となる名詞句を抽出し、意味カテゴリ付与部18で、名詞句各々に意味カテゴリを付与し、エントロピー算出部20で、付与された意味カテゴリの偏りを示すエントロピーを第1の素性として算出する。また、視覚的特徴算出部24で、入力された文書が縦長か横長かを示す第2の素性を算出する。素性ベクトル生成部26で、第1の素性及び第2の素性を並べた素性ベクトルを生成し、具体主題が既知の学習用文書の素性ベクトルを用いて学習された分類器に入力して、入力された文書が具体主題を有するか否かを判定する。
(もっと読む)
グループ化装置およびエレメント抽出装置

【課題】ネット上において特定ユーザーの個人領域ページを特定し、ページ内に含まれるエレメントを抽出する。
【解決手段】第1のアドレスキーと第2のアドレスキーの類似度がしきい値以上と判断された場合に、URLを特定のアドレス群として関連付ける(個人領域の特定)。さらに、イメージ化したWebページ上に点を配置し、配置した点を含むエレメントの階層構造を統合などして、対応する内容データを抽出する(エレメントの抽出)。
(もっと読む)
データ抽出装置、データ抽出方法、及びプログラム
【課題】人手による修正コストを小さくし、かつ、セマンティックドリフトを効率的に軽減する
【解決手段】正例エンティティに対応する正例トピック情報を正例エンティティの素性の少なくとも一部とし、負例エンティティに対応する負例トピック情報を負例エンティティの素性の少なくとも一部とし、正例エンティティの素性と負例エンティティの素性とを教師あり学習データとした学習処理によって識別モデルを生成し、対象エンティティに対応するトピック情報を当該対象エンティティの素性の少なくとも一部とし、対象エンティティが正例エンティティか負例エンティティかを識別する。また、トピック情報の関する情報を人手によって修正する。
(もっと読む)
録画装置
【課題】録画された動画からユーザー所望のシーンを簡易且つ迅速に抽出して表示することが可能な録画装置の提供を目的とする。
【解決手段】デジタルテレビ放送を受信して記録媒体に記録する録画装置100において、デジタルテレビ放送に含まれる動画を構成するフレーム画像から、出演者分類DB70に登録された出演者の顔画像を抽出し、出演者分類DB70に登録された出演者に対応付けられているジャンルを、顔画像の抽出を行ったフレーム画像に付加する。
(もっと読む)
ランドマーク推薦装置及び方法及びプログラム
【課題】 動作主が好む、位置座標以外のランドマークの特徴に基づいて、ランドマークを推薦する。
【解決手段】 本発明は、位置座標の近さ以外で複数のランドマークを潜在的に結びつける特徴(潜在トピック)の存在を仮定して、動作主が各潜在トピックに対して興味を持つ確率値θ(ユーザ固有トピック出現確率)と潜在トピックから各ランドマークが選択される確率値φ(トピック固有ランドマーク存在確率)を学習し、これらの確率値、動作主の移動履歴情報、ランドマーク情報とから算出される、動作主がランドマークを訪問する確率値に基づいて、動作主に対してランドマークを推薦する。
(もっと読む)
データ分析の分析軸推薦方法、システム、及びプログラム
【課題】多次元データ分析における利用者(分析担当者)による分析対象とするデータ項目の組の選定に要する試行錯誤の削減などを可能とする技術を提供する。
【解決手段】本システム(101)では、多次元データ分析の分析軸を推薦する処理機能を有し、多次元データのデータ項目間のデータの関連度を算出する処理(11)と、上記関連度に基づいて、分析対象に適するデータ項目の組を抽出する処理(12)と、多次元データ分析の際、上記抽出したデータ項目の組を、分析者に対して推薦する分析軸として提示する処理(13)とを行う。上記構成により、分析対象とするデータ項目の組(分析軸)の選定を支援する。
(もっと読む)
話題出力装置及び方法及びプログラム
【課題】 一定期間よりも大きな周期の既によく知られた話題に関する語句を出力しないよう選択する。
【解決手段】 本発明は、時刻情報、階層カテゴリ情報が付与された一定期間の文書を取得し、文書集合に含まれる語句の出現数を求め、該出現数に基づいて、該一定期間に話題になった語句の話題度を算出し、話題度の高い語句に対して、周期性があるかどうかを判断し、周期性があると判断した各語句に対して、階層カテゴリの上位階層から順に、同一階層カテゴリ間において語句の出現に偏りがあるかどうか調べ、上位階層において偏りが少ないほど高い認知レベルを付与する。利用者に指示された認知レベルや、予めシステムに設定した認知レベルに合わせて、語句を選択して出力する。
(もっと読む)
文書分析装置およびプログラム
【課題】複数のカテゴリの内容を相互に比較するのに好適な特徴語を抽出することが可能な文書分析装置およびプログラムを提供することにある。
【解決手段】単語抽出手段は、カテゴリ情報格納手段に格納されているカテゴリ情報によって示される第1のカテゴリに属する複数の文書に含まれる単語を抽出する。文書数算出手段は、抽出された単語が第1のカテゴリに属する複数の文書において出現する文書の数を示す第1の文書数および第1のカテゴリの下位に位置する第2のカテゴリに属する複数の文書において出現する文書の数を示す第2の文書数を算出する。特徴度算出手段は、第1のカテゴリに属する文書の数、第2のカテゴリに属する文書の数、第2のカテゴリの数、第1および第2の文書数に基づいて、前記抽出された単語の特徴度を算出する。特徴語抽出手段は、特徴度に基づいて前記第1のカテゴリに対する特徴語を抽出する。
(もっと読む)
Nグラム検索のための転置インデックスの生成方法および生成装置、当該転置インデックスを用いた検索方法および検索装置、ならびに、コンピュータプログラム
【課題】データ容量が効率的に抑えられた転置インデックスの生成方法等を提供する。
【解決手段】文書入換ステップと、生成ステップと、合成ステップと、を備えた転置インデックスの生成方法であって、文書入換ステップでは、それぞれが、見出し語と対応する複数の説明文とから構成される複数の文書データ18のうち、少なくとも1つの文書データ18の複数の説明文の順序を入れ換えて、入換文書データを作成し、生成ステップでは、文書データ18もしくは作成された入換文書データから、「N文字の文字列であるNグラム(Nは自然数)」を抽出し、抽出されたNグラムのそれぞれについて、当該文書データ18もしくは当該入換文書データ中の出現位置を対応付けて、部分転置インデックスを生成し、複数の文書データ18について生成された複数の部分転置インデックスから、転置インデックスを合成する。
(もっと読む)
同一の共有コンテンツに興味を持つ視聴者の属性の観点を推定する最適観点推定プログラム、装置及び方法
【課題】同一の共有コンテンツに興味を持つ他の視聴者の属性の観点を推定すると共に、その観点に基づいて視聴者属性を推定するプログラム等を提供する。
【解決手段】ツリー状の観点及び属性単語を含む観点リストを記憶した観点リスト記憶手段と、各属性単語に関連する多数の学習文章情報を記憶した学習文章情報記憶手段とを有する。また、共有コンテンツから複数のキーワードを抽出する。次に、共有コンテンツについて、キーワードを要素とし且つその出現頻度を値とする第1のベクトルを導出し、キーワード毎に、当該キーワードと一致する属性単語における学習文章情報について、当該学習文章情報に含まれる単語を要素とし且つその出現頻度を値とする第2のベクトルを導出する。両ベクトルの類似度を算出し、類似度を対応付けた類似度付き観点リストを生成し、観点リストのレイヤ毎に、類似度の分散が最も大きい観点及び属性単語を導出する。
(もっと読む)
階層構造管理装置、その方法、及びプログラム
【課題】様々な分類観点が混在して管理されている階層構造から、任意の観点に基づく階層構造を自動生成し、利用者にとって使い勝手のよい階層構造管理装置等を提供する。
【解決手段】既存のファイルのパス名一覧を入力データとし、ノード名やファイル名を形態素解析して単語情報を構築し、既存のファイルを保持している旧階層構造から、複数箇所に出現する単語を切り出して旧階層構造を単純化して、第1の新階層構造を形成し、その後、切り出した単語を使用して、各単語が新階層構造上の複数の箇所に出現しないように、それぞれの単語が所属する第2以降の新階層構造を決定することで、組織で使用されるファイルの分類基準を独立した新階層構造を用いて再構成することができる。
(もっと読む)
関係コンテンツ評価装置、関係コンテンツ評価システムおよび関係コンテンツ評価方法
【課題】 複数のコンテンツにおいてなされた情報処理の種類に基づいてそれらコンテンツ間の関係を関係情報として特定する。
【解決手段】 関係コンテンツ評価装置は、コンテンツを識別するコンテンツ識別子を複数含む関係情報、および、そのコンテンツ識別子で識別されるコンテンツ間の関係性の指標を示す値である関係度、を対応付けて記憶する記憶部から、第一のコンテンツ識別子を含む関係情報とその関係情報に対応付けられている関係度とを読み出し、読み出した関係度のうち、第一のコンテンツ識別子と第二のコンテンツ識別子とを含む関係情報に対応付けられた関係度の和と、第一のコンテンツ識別子を含む関係情報に対応付けられた関係度の和との比が所定の閾値以上の場合に、第一のコンテンツ識別子で識別されるコンテンツと第二のコンテンツ識別子で識別されるコンテンツとを関係するコンテンツと判定する。
(もっと読む)
データ処理装置及びデータ処理方法及びプログラム
【課題】2つの2次元データの間で対応関係にあるカラムを抽出する作業の効率を向上させる。
【解決手段】区切り分割部11が移行元データにおいて解析対象となるカラム対を選択し、相関ルール計算部12が移行先データにおいて解析の対象となるカラム対を選択し、移行元データのカラム対において行ごとに支持度及び確信度を計算し、移行先データの各カラム対について、行ごとに支持度及び確信度を計算する。相関差分値計算部13が、移行元データ内で行間の支持度及び確信度の差分計算を行い、移行先データ内で、カラム対ごとに、行間の支持度及び確信度の差分計算を行い、比較計算部14が、移行元データでの差分値と移行先データでの差分値との差分計算を行い、判定部15が、差分計算の結果に基づき、移行元のカラム対に対応する移行先のカラム対を判定する。
(もっと読む)
画像ファイル生成装置、顕微鏡装置およびプログラム
【課題】撮像条件を変えて画像を連続して取得する場合に、取得画像の容易な事後管理を実現する。
【解決手段】画像ファイル生成装置は、ユーザから画像の取得指示、取得終了指示、取得画像の撮像条件の変更を受け付ける受付部140と、取得指示に応じて、変更された撮像条件で得られた画像を外部から取得する画像取得部150と、1以上の取得画像を収容した画像ファイルを生成するファイル生成部160とを備え、受付部140は、取得フェーズ中の撮像条件の変更時において、当該変更の受付前に取得された取得画像と当該変更の受付後に取得される取得画像とを異なる画像ファイルに収容するか否かを更に受け付け、ファイル生成部160は、受付部140により、異なる画像ファイルに収容しない旨を受け付けた場合には、当該変更前に取得した画像と当該変更後に取得した画像とを纏めて収容した画像ファイルを生成する。
(もっと読む)
情報処理装置、情報処理方法およびプログラム
【課題】特定のシーンを適切に検出する。
【解決手段】カットチェンジ解析部230は、チェンジ点を検出する。動き解析部240は、画像における被写体の遷移を検出する。構図解析部270は、画像における構図と特定シーンの構図との類似の程度を示す構図類似度情報を生成する。振幅解析部320およびスペクトル解析部330は、解析対象の音声データと特定シーンの音声データとの類似の程度を示す音声類似度情報を生成する。区間特徴量生成部350および区間評価部360は、チェンジ点と検出された遷移と構図類似度情報と音声類似度情報とに基づいて、チェンジ点間に含まれる動画が特定シーンに対応する動画であるか否かを判定する。
(もっと読む)
情報処理システム、装置、方法、及びプログラム
【課題】行なわれたアクセスと関連付けられている情報の提供において、対象が異なる作業に基づいたアクセスによって取得された情報同士が関連付けられることを抑制する。
【解決手段】予め定められた複数のアドレスのそれぞれに与えられた識別情報を、アクセスに応じて切り替え可能にして保持させ、アクセス先アドレスと保持された識別情報を関連付けて記憶させておき、記憶されているアドレスのうちアクセス先アドレスと同じアクセス先を示すアドレスと関連付けられている識別情報が同一であるアドレスを抽出する。
(もっと読む)
図書館カタログ・メニュとサーチ機能とを有する電子書籍
【課題】書籍及びそれ以外のテキスト情報を配布し、更に、電子書籍をカタログ化しサーチする電子書籍選択及び配布システムを提供する。
【解決手段】テキスト情報は電子信号上に符号化され多数の異なる媒体の任意の1つを介して伝送される。ビューワ又はライブラリ・ユニットは、電子書籍を記憶し、ビューワ上に表示を行う。ユーザは、様々な基準に基づいて組織され記憶されている電子書籍のメニュをカタログ化して見ることができる。ユーザは、更に、記憶された電子書籍の中から特定の電子書籍をサーチすることもできる。
(もっと読む)
意味属性推定装置、意味属性推定方法、意味属性推定プログラム
【課題】日本語辞書,日英対訳辞書を要することなく、単語の意味属性を自動で推定する。
【解決手段】意味属性推定装置5は、予め概念ベクトルと意味属性が付与された多数の既存単語の情報を格納した概念ベース4を備える。そして、概念ベクトル付与手段1は意味属性を推定したい単語(処理対象単語)に対して概念ベクトルを算出する。距離計算手段2は、処理対象単語と、予め概念ベース4に格納された既存単語との概念ベクトルにおける距離を算出する。意味属性候補出力手段3は、前記概念ベクトルにおける距離に基づき、処理対象単語の概念ベクトルとの距離が小さな単語を抽出し、抽出された単語の意味属性を処理対象単語の意味属性候補とする。
(もっと読む)
コンテンツ自動分類装置、コンテンツ自動分類方法およびコンテンツ自動分類プログラム
【課題】ラベルありサンプルの与え方に偏りがある場合でもコンテンツ自動分類の精度を向上させる。
【解決手段】この発明のコンテンツ自動分類装置は、カテゴリが不明なコンテンツを入力として、そのコンテンツのカテゴリを分類するコンテンツ自動分類装置であって、識別関数生成部とコンテンツ分類部とを備え、識別関数生成部は、コンテンツとカテゴリの依存関係の強さを表す識別関数を、条件付確率モデルと同時確率モデルの重み付き統合で与え、識別関数のモデルパラメータである条件付確率モデルのパラメータと、同時確率モデルのパラメータと、重み付き統合の重みと、をラベルありサンプルとラベルなしサンプル双方の統計情報をもとに同時に計算する。
(もっと読む)
関連するウェブページ内コンテンツを分類・整理し自由自在に再構成して表示する方法
【課題】 本発明は,関連するウェブページ内コンテンツを分類・整理して自由自在に再構成して表示する方法を提供することを目的とする。
【解決手段】 上記課題は,ウェブ内配置把握工程(ステップ101),ウェブ分割工程(ステップ102),特徴語抽出工程(ステップ103),特徴語整理工程(ステップ104),表示情報整理工程(ステップ105),関連ウェブページ表示工程(ステップ106)を含む方法により解決される。このように本発明の方法は,ウェブページ内の情報をコンテンツ単位で属性ごとに整理することで,これらのコンテンツを自由自在に再構成して表示させ、ユーザのアクションを促進させることができる。
(もっと読む)
1 - 20 / 151
[ Back to top ]