
Fターム[5B075QS01]の内容
Fターム[5B075QS01]に分類される特許
1 - 20 / 108
検索方法、検索装置、ならびに、コンピュータプログラム
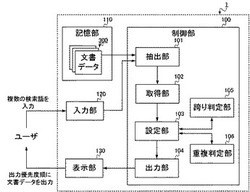
【課題】ユーザの意図にあった検索結果を提示するのに好適な検索方法、検索装置、ならびに、コンピュータプログラムを提供する。
【解決手段】検索装置1において、抽出部101は、複数の文書データ(文書データ群300)のうちから、複数の検索文字列を含む文書データを抽出する。取得部102は、抽出された文書データのそれぞれにおいて、複数の検索文字列を全て包含する文字列を取得する。設定部103は、抽出された文書データのそれぞれに、当該文書データにおいて取得された文字列の文字数に基づいて、出力優先度を設定する。出力部104は、設定された出力優先度を対応付けて、抽出された文書データを出力する。跨り判定部105は、取得された文字列が複数のセンテンスに跨っているか否かを判定する。重複判定部106は、取得された文字列に包含される複数の検索文字列が同一位置にある文字を共有しているか否かを判定する。
(もっと読む)
特徴量算出装置、文書類似度算出装置、特徴量算出方法およびプログラム

【課題】文書間の類似度を算出するために用いられる文書の特徴量を適切に算出する技術を提供する。
【解決手段】文書類似度算出装置10は特徴量算出装置(部)100を有し、特徴量算出装置100は単語間類似度情報記憶部194とtf−idf算出部110と特徴量ベクトル算出部130とを有する。単語間類似度情報記憶部194は、外部の文書の単語又はユーザによって設定された単語を含む単語間の類似度を示す単語間類似度情報を記憶する。tf−idf算出部110は、文書を構成する各単語のtf−idfを算出する。特徴量ベクトル算出部130は、tf−idf算出部110によって算出された上記文書を構成する各単語のtf−idfと、単語間類似度情報記憶部194に記憶されている単語間類似度情報とに基づいて、上記文書の特徴量ベクトルを算出する。
(もっと読む)
文書検索装置、文書検索方法及び文書検索プログラム
【課題】与えられたキーワードを含む電子文書の数(DF値)を、少ないメモリ使用量で高速に計算できる文書検索装置を提供する。
【解決手段】入力された複数の検索キーワードの各々の重要度を用いて、複数の文書から所望の文書を検索する文書検索装置であって、複数の文書の各々に含まれる文字列に対する接尾辞配列を構築し、接尾辞配列の各接尾辞と、各接尾辞と同じ文書に由来し、且つ、辞書順序で一つ前又は後の接尾辞と、を先頭の文字から順番に比較した場合に一致する文字の数を、各接尾辞に対応する要素とする整数配列を構築し、構築された整数配列において、入力された複数の検索キーワードの各々で始まる接尾辞に対応する要素のうち、検索キーワードの文字数より小さい値の要素の数を、当該検索キーワードを含む文書の数として算出し、算出された文書の数を用いて、当該検索キーワードの重要度を計算する。
(もっと読む)
電子文書マスキングシステム
【課題】構造化されていない電子文書に対し、電子文書毎の公開レベルに対応して秘匿すべき情報を変更し、マスキング対象を絞ってマスキングする。
【解決手段】マスキング処理部101のマスキング対象判定部は、電子文書110の文書名により文書公開レベルDB106を検索して、各電子文書110についてマスキングする文字列の種別毎のマスキング要否情報を取得する。そして、マスキング対象判定部は、取得された要否情報がマスキングすることを指定している場合、マスキング対象判定辞書105に格納されているマスキング対象文字列の種別毎の文字列定義情報に基づいて電子文書110に含まれる各文字列がマスキング対象文字列であるか否かを判定し、マスキング対象文字列であると判定されたマスキング対象文字列をマスキングする。
(もっと読む)
文書処理装置、文書処理方法、文書処理プログラム、及び文書処理プログラムを記録したコンピュータ読み取り可能な記録媒体
【課題】 インターネット上の文書から、正当な引用を行なっている文書を含めたオリジナルな文書の抽出を可能にする。
【解決手段】 複数の文書に含まれる文字列から、この文字列の一部をなす部分文字列を文書毎に生成する部分文字列生成手段と、前記部分文字列生成手段により生成された前記部分文字列の内、自らが生成された文書以外の文書に含まれない部分文字列を一意部分文字列として判定する一意部分文字列判定手段と、文書毎の総部分文字列数と前記一意部分文字列判定手段により判定された前記一意部分文字列数との比が所定の範囲にある文書を不要文書として検出する不要文書検出手段とを備える。
(もっと読む)
フィルタ設定システム、フィルタ設定方法、及びフィルタ設定プログラム
【課題】メッセージ処理にかかる処理負荷を有効に軽減する。
【解決手段】フィルタ条件に一致したメッセージ中の条件単語の出現回数、出現位置、および前記条件単語の長さを条件単語情報として算出し、この条件単語情報が予め設定されたフィルタ作成定義情報の値を上回る場合に、当該条件単語を追加フィルタ候補として抽出する出現頻度分析手段74と、追加フィルタ候補のメッセージ内における出現頻度割合が一定値以上である場合に、この追加フィルタ候補によりフィルタ条件情報の内容を追加更新するフィルタ候補選定手段75と、フィルタ条件情報に一致したメッセージの割合に基づき追加フィルタ情報のフィルタ有効性の有無判定を行いフィルタ有効性がないと判定されたフィルタ条件情報を削除するフィルタ有効性分析手段を備えた。
(もっと読む)
検索装置、ならびに、コンピュータプログラム
【課題】複数の文書から、指定された検索語を有する文書を、効率的に検索するのに好適な検索装置等を提供する。
【解決手段】検索対象の複数の文書データから抽出されたNグラムのそれぞれについて、複数の文書データ中の出現位置情報を構成要素とする転置インデックスを、Nの異なる複数のNグラムについて記憶する記憶部11を備えた検索装置10において、Nグラム抽出部13は、Nの異なる複数のNグラムのうち、検索文字列の文字数に応じて使用するNグラムを変化させて、検索文字列からNグラムを抽出し、文書特定部14は、検索文字列から抽出されたNグラムについて、転置インデックスの出現位置情報に基づいて、複数の文書データのうちから検索文字列を含む文書データを特定する。
(もっと読む)
要素列の近似的な照合又は検索及びその方法を実行するためのプログラムを格納した記録媒体
【課題】 オートマトンを変形した構成とすることで、文章の要素列と複数の辞書語の要素列を効率的に実行することが可能な近似的な照合又は検索方法に関する。
【解決手段】 オートマトンの遷移ルールが付与された辞書語の要素列を登録するための工程と、近似的な照合又は検索を行うための、エラー値の上限値を設定するための工程と、照合対象となる文章の要素列を入力するための工程と、遷移ルールが付与された辞書語の要素及びエラー値の上限値に基づき、第1の命令手順及び第2の命令手順によって、辞書語の要素と文章の要素列において照合対象となった部分文字列の要素とを照合し、辞書語の最後に照合を行った要素の位置情報pと、照合の不一致のエラー値eの内部的変数の組を生成する工程と、生成された内部的変数の組を記憶する工程と、内部的変数の組をもとに、照合結果を出力する工程を有する要素列の近似的な照合又は検索方法である。
(もっと読む)
表示制御装置、画像形成装置、表示制御方法及び表示制御プログラム
【課題】ウェブページ内から所望の情報を容易に発見することができる表示制御装置を提供する。
【解決手段】表示部410と、表示部410にウェブページを表示させるウェブ表示制御部5223と、ウェブページのスクロール指示を受け付けるスクロール指示受付部5225と、スクロール指示に応じてウェブページを予め定められた標準速度でスクロールして表示するスクロール表示制御部5226と、検索キーワードの入力を受け付けるキーワード受付部5227と、ウェブページ内から検索キーワードが使用されている箇所を検索する(ページ内検索処理)ページ内検索部5224とを備え、スクロール表示制御部5226は、ページ内検索処理が行われ検索キーワードが使用されている箇所が表示部410に表示されている場合、スクロールする速度を前記標準速度よりも遅い閲覧速度に設定する表示制御装置。
(もっと読む)
画像検索システム、画像検索方法および画像検索プログラム
【課題】スキャナにより読み込んだ文書画像を検索時に呼び出す場合において、システムへの負荷を大幅に減らし、検索、閲覧そしてダウンロードや編集のスピードを向上させるシステムの提供。
【解決手段】スキャナにより読み込まれた文書画像データをタグ形式画像フォーマットへ変換する際、頁毎の個別画像ファイルを生成し、これにOCR処理を施して得たテキストデータファイルを前記画像ファイルと共通の識別子と、文字座標情報を付与して保存し、検索要求を受けた際、検索文字と一致した文字情報を有するテキストファイルと共通する識別子を持つ画像ファイルを呼び出し、検索対象を強調して表示することを特徴とする。
(もっと読む)
文書検索装置ならびにその動作制御方法およびその制御プログラム
【目的】文書内で複数のキーワードに関連する部分を見つける。
【構成】複数のキーワードが入力され(ステップ12),入力された複数のキーワードのうち,少なくとも2つのキーワードが含まれている段落部分が文書から見つけられる(ステップ13)。キーワード同士の距離が短いほどスコアが多くなるようなスコアの総スコアが段落部分ごとに算出される(ステップ14)。総スコアの多い順に段落部分が表示される(ステップ16)。
(もっと読む)
検索キーワード辞書に対する非検索キーワード辞書を用いた文章検索プログラム、サーバ及び方法
【課題】例えば予め登録されたキーワードによって違法・有害なカテゴリに属するか否かを判定する際に、違法・有害でない文章情報が、違法・有害なカテゴリに分類されることをできる限り減らすことができる文章分類プログラム、サーバ及び方法を提供する。
【解決手段】特定カテゴリに属さない複数の正当学習文章情報と、特定カテゴリに属する複数の不当学習文章情報とを蓄積した学習文章蓄積手段を有し、検索キーワードを含む学習文章情報を検索し、その検索キーワードに対する係り受けキーワードを抽出し、係り受けキーワード毎に、全ての学習文章情報の数に対する正当学習文章情報の数の正当割合を算出し、正当割合が所定閾値以上となる係り受けキーワードを非検索キーワードとして登録する非検索キーワード辞書を生成する。これにより、検索キーワードに対する係り受けキーワードとして非検索キーワードが含まれている文章情報は検索されないようにする。
(もっと読む)
情報共有システム
【課題】共有情報に関係した自己の書込データの入力を容易にでき、有益な集計結果を迅速に確認することが可能な情報共有システムを提供すること。
【解決手段】議題と議題に関係した標準パターンとを含む共有情報を記憶した情報管理装置と、共有情報を利用する複数の情報端末とからなり、情報端末が、情報管理装置から配信された共有情報を表示する表示部と、表示された議題に関係し標準パターンを参考にして考案された書込データを入力する入力部と、入力された書込データを情報管理装置へ送信する書込データ処理部と、情報管理装置から集計結果を受信し表示部に表示する集計結果受信部とを備え、情報管理装置が、共有情報を情報端末へ配信する共有情報配信部と、標準パターンと受信された書込データとを用いて、共有情報に対する分析処理を行い集計結果を生成する自動集計部と、その集計結果を情報端末へ送信する集計結果送信部とを備えたことを特徴とする。
(もっと読む)
情報検索プログラム及び情報検索装置
【課題】質問文に対する適切な回答となる文書に含まれる文章中にその質問文から抽出される自立語が含まれていない場合において、適切な回答を行う情報検索プログラム及び情報検索装置を提供する。
【解決手段】情報検索プログラム11Aは、コンピュータを、受け付けた質問文から自立語を抽出する自立語抽出手段10Aと、自立語抽出手段10Aが抽出した自立語を含む文章を、文章データベース2Aから検索する関連文章検索手段10Cと、関連文章検索手段10Cが検索した文章に含まれる自立語を抽出し、その自立語から特徴的に用いられる自立語を特徴語として特定する特徴語特定手段10Dと、特徴語を、又は特徴語を含む文書を検索して該当する文書を、質問文に対する回答として抽出する回答抽出手段10Eとして機能させる。
(もっと読む)
文書解析システム
【課題】大量の文書が常に増加していくという特徴や、話題が多様で体験談や感想が書かれていることが多いという特徴を持つ文書データの集合において、より正確に話題の内容や筆者の意図を分析する。
【解決手段】文書解析システムは、文書データ124に含まれるキーワードをマッチング検索によって調べるマッチング検索処理部113と、各文書データ124からキーワードとユーザの印象や感想を示す評価語句を抜き出して文書データ124内のキーワードを評価する文書内分析処理部114と、文書内分析処理部114で得られたキーワードに対する評価に基づいて多数の文書データ124についてキーワードを評価する文書間分析処理部115を備える。この文書解析システムにより、ブログやSNSなどのCGMに蓄積されるユーザが発信した文書データ群について市場全体のニーズやその変化を解析し、ユーザの嗜好や市場ニーズに関する情報を得ることができる。
(もっと読む)
漢文例文検索装置およびプログラム
【課題】漢文例文検索装置において、漢文の例文を漢文の訓読の規則を考慮して適切に検索すること。
【解決手段】漢文検索入力画面Gの熟語検索文字列入力エリアE1に検索文字列(熟語)が入力された場合には、漢文例文データベースから順次読み出される例文データを対象に、前記検索文字列(熟語)と完全一致し且つその文字列間に返り点が存在しない文字列(熟語)を含んでいる例文データが検索されて表示される。また、読み順検索文字列入力エリアE2に検索文字列(読み順)が入力された場合には、漢文例文データベース24cから順次読み出される例文データを対象に、漢文の訓読の規則に従った漢字1文字が順次取得され、前記検索文字列(読み順)と完全一致する例文データが検索されて表示される。
(もっと読む)
情報共有システム、情報共有方法、および情報共有プログラム
【課題】きめ細かい機密保持制御とユーザビリティに優れた情報共有制御とをバランス良く両立させる。
【解決手段】記憶装置が格納している各文書データから所定属性を持つ文字列ないし記号を特徴情報として抽出し文書データ毎に記憶するクローラー部111と、情報検索要求が示す検索条件に基づいて記憶装置が格納している各文書データでの全文検索を実施する検索エンジン部112と、全文検索により特定した文書の特徴情報を記憶装置のテーブルから抽出し、該当特徴情報に関するアクセス権のデータを記憶装置から読み取り、アクセス権のデータがアクセス可を示す特徴情報を開示可特徴情報として特定するセキュリティモジュール部113と、全文検索の結果と全文検索結果に含まれる文書の特徴情報のうち開示可特徴情報とを併せて検索結果としてクライアントコンピュータに送信る検索サービス部110とから情報共有システムを構成する。
(もっと読む)
文字列照合装置および文字列照合プログラム
【課題】正規表現を照合条件とする文字列照合に対して、状態遷移表を格納するのに必要な記憶容量を削減する。
【解決手段】正規表現で記述された照合条件2に基づいて状態遷移表を生成する状態遷移表生成部3と、前記状態遷移表生成部3により生成された状態遷移表に基づいて遷移するオートマトンとを備えるとともに、前記オートマトンは、前記照合条件2に基づいて生成された状態遷移表において、現状態と入力文字の組に対する次の遷移先状態が存在しない場合、入力文字を読み進めずに初期状態或いは所定の状態へ遷移することにより、状態遷移表を格納するのに必要な記憶容量を削減する。前記照合条件2に基づいて生成された状態遷移表において、現状態と入力文字の組に対する次の遷移先状態が存在しない場合、入力文字を読み進めずに所定の状態へ遷移する除外文字を設定して状態遷移表を作成する。
(もっと読む)
文書検索装置
【課題】電子文書やイメージ文書、これら混在文書等多様種文書の文字コード正規化は複数の方法を用いるが、正規化後の文字コードでヒットした検索スコアを各正規化法に応じたものにできない。
【解決手段】異なる処理をする等価文字テーブルと異体・異発音文字テーブルと分解合成文字テーブルと同型文字テーブルを備え、検索文書から電子テキスト抽出部での抽出文字コードには同型文字テーブル以外のテーブルを、文字認識部での文字認識された候補文字付きの文字コードには全テーブルを参照して正規化処理し、かつ正規化処理時の分解統合文字の座標位置情報を分解統合前の情報から算出し正規化文字コードと対応した検索インデックスを検索インデックス生成部で生成、検索処理部が全テーブルで検索キーワードを正規化し検索インデックスとの照合結果を検索スコアと共に出力する。
(もっと読む)
文書検索装置、文書検索方法、および文書検索プログラム
【課題】 クエリと検索結果が潜在的に持つ情報要求に沿った高精度な検索を行う。
【解決手段】 文書検索装置1のクエリ情報要求生成部114は、ログDB110のログに含まれるクエリに関連する拡張語の集合をクエリ情報要求DB117へ格納する。検索結果情報要求生成部115は、ログに含まれる検索結果がクリックされたときに投入されたクエリを判別し、該判別したクエリに関連する拡張語の集合を検索結果情報要求DB116へ格納する。照合処理部119は、ユーザ端末13から投入されたクエリを、クエリ情報要求DB117の格納情報を用いて拡張する。検索エンジン100は、前記拡張クエリに該当する検索結果を取得する。ランキング処理部123は、前記検索結果を検索結果情報要求DB116の格納情報を用いて拡張し、前記拡張クエリとの関係性に基づいて該検索結果を並べ替え、ユーザ端末13へ返信する。
(もっと読む)
1 - 20 / 108
[ Back to top ]