
Fターム[5B091BA15]の内容
Fターム[5B091BA15]の下位に属するFターム
文脈解析 (4)
Fターム[5B091BA15]に分類される特許
1 - 20 / 22
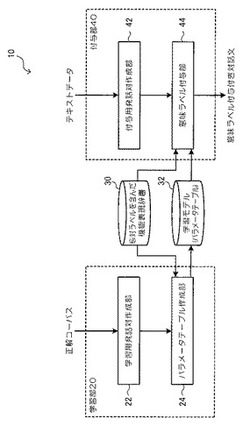
意味ラベル付与モデル学習装置、意味ラベル付与装置、意味ラベル付与モデル学習方法、及びプログラム
【課題】会話の流れによって疑問表現になったり、断定表現になったりする述部の機能表現に対しても、適切な意味ラベルを付与する。
【解決手段】学習用発話対作成部22で、形態素解析結果に対して、機能表現及び応対表現の正解ラベルが付与された正解コーパスに基づいて、学習用発話対を作成する。パラメータテーブルに、素性として、発話対の前の発話の終わりに表れる機能表現の意味ラベルと、それに対する後の発話の初めに表れる応対表現の意味ラベルとの並びの素性を用い、複数種類の素性各々について、重みの初期値を設定する。パラメータテーブル作成部24で、発話対の形態素情報と機能表現辞書30とを用いて、各形態素について候補となる意味ラベルを全て含んだラティスを構築し、ラティス構造からパラメータテーブルの素性毎の重みに基づいて最尤パスとして探索する。最尤パスが正解の意味ラベル列となるようにパラメータテーブルの重みを学習する。
(もっと読む)
コーパス変換装置、コーパス変換方法、およびプログラム

【課題】大規模な書き言葉コーパスを相槌を含む大規模なコーパスに変換すること。
【解決手段】コーパス変換装置100は、相槌を含む学習コーパス10の文を取得する学習コーパス取得部110と、コーパス取得部110で取得した文に基づいて、文長毎に、文中の各位置の相槌の出現確率を算出する出現位置確率算出部120と、算出した出現確率を文長および文中の位置に対応つけて記憶する出現位置確率記憶部130と、学習コーパス取得部110で取得した文に基づいて、相槌の種別毎に、文中の各位置の相槌の出現確率を算出する出現種別確率算出部140と、算出した出現確率を相槌の種別および文中の位置に対応つけて記憶する出現種別確率記憶部150と、出現位置確率記憶部130と出現種別確率記憶部150とに基づいて、大規模コーパス30の文に相槌を挿入し、相槌を含む大規模なコーパスを構築する変換手段と、を備える。
(もっと読む)
意味分析装置およびそのプログラム
【課題】より少ない正解事例からも、意味分析のためのモデルを精度良く構築できるようにする。
【解決手段】正解データ記憶部は、学習用データに対応する正解データを記憶する。拘束条件記憶部は、学習用データに関する潜在変数間の条件を拘束条件データ。解析部は、学習用データを読み込み、学習用データを解析して得られる解析結果データを出力する。モデル生成部は、正解データ記憶部から読み出した正解データと解析部から出力された解析結果データとを用い、解析結果データに潜在変数を対応させるとともに、拘束条件記憶部から読み出した拘束条件データに基づいて、拘束条件データを潜在変数同士の拘束条件として、学習処理を行ってモデルを生成する。
(もっと読む)
文書分析補助装置及び方法及びプログラム
【課題】 ブログやチャット等の短い文書の文書解析における曖昧性を解消する。
【解決手段】 本発明は、テキスト及び時刻を含む文書情報とユーザ情報を取得し、該文書情報を文書情報記憶手段に格納し、ユーザ情報に基づいてマイクロブログサービスから関係ユーザ情報を取得し、関係ユーザ情報に基づいてマイクロブログサービスから文書情報の時刻の任意の期間範囲の関係文書情報を取得して、文書情報記憶手段に格納し、文書情報記憶手段に格納されている文書情報と関係文書情報を時刻順にソートして1文として結合した解析対象文書を生成する。その上で解析対象文書を解析する。
(もっと読む)
具体主題の有無判定装置、方法、及びプログラム
【課題】文書が具体主題を有するか否かを判定する。
【解決手段】名詞句抽出部12で、具体主題の候補となる名詞句を抽出し、意味カテゴリ付与部18で、名詞句各々に意味カテゴリを付与し、エントロピー算出部20で、付与された意味カテゴリの偏りを示すエントロピーを第1の素性として算出する。また、視覚的特徴算出部24で、入力された文書が縦長か横長かを示す第2の素性を算出する。素性ベクトル生成部26で、第1の素性及び第2の素性を並べた素性ベクトルを生成し、具体主題が既知の学習用文書の素性ベクトルを用いて学習された分類器に入力して、入力された文書が具体主題を有するか否かを判定する。
(もっと読む)
主題抽出装置、方法、及びプログラム
【課題】文書から主題を抽出する。
【解決手段】名詞句抽出部12で、具体主題の候補となる名詞句を抽出し、名詞句ペア作成部14で、名詞句ペアを作成する。名詞句頻度抽出部18で、名詞句各々の出現頻度、及び名詞句ペア各々の共起頻度を抽出し、出現確率勝敗算出部20で、名詞句各々の出現頻度及び名詞句ペアの共起頻度から求まる名詞句各々の出現確率を求め、名詞句ペアで出現確率に基づく勝敗を示す第1の素性を算出する。また、係り受け構造抽出部22で、名詞句ペアの係り受け構造毎の出現頻度を抽出し、係り受け関係勝敗算出部24で、名詞句ペアで係り先になり易さによる勝敗を示す第2の素性を算出する。素性ベクトル生成部26で、第1の素性及び第2の素性を並べた素性ベクトルを生成し、具体主題が既知の学習用文書に含まれる名詞句の素性ベクトルを用いて学習された分類器に入力して、具体主題を示す名詞句を抽出する。
(もっと読む)
機械翻訳装置、方法およびプログラム
【課題】翻訳結果を得るまでの時間を短縮できるとともに、信頼度の高い機械翻訳結果を得ることができる機械翻訳装置を提供する。
【解決手段】言い換え文生成手段81は、入力されたテキスト文と同一の言語でそのテキスト文の内容を示す別の表現へ言い換えた1つまたは複数の言い換え文を生成する。機械翻訳手段82は、言い換え文を翻訳後の言語である目的言語へと機械翻訳する。翻訳信頼度決定手段83は、目的言語へ翻訳された言い換え文の信頼度を示す翻訳信頼度を決定する。言い換え文特定手段84は、言い換え文生成手段81が生成した言い換え文の中から、翻訳信頼度に基づいて言い換え文の候補を抽出し、候補の中から翻訳の対象とする言い換え文である翻訳対象言い換え文を特定する。
(もっと読む)
単語意味関係抽出装置及び単語意味関係抽出方法
【課題】表音文字からなる言語の単語間で文字の表記に基づいて単語意味関係を正確に抽出する単語意味関係抽出装置を提供することを目的とする。
【解決手段】データに含まれる単語から、二つの単語によって構成される単語ペアを抽出し、抽出した単語ペアの単語意味関係を判定する単語意味関係抽出装置において、単語意味関係辞書に登録された単語意味関係単語ペアの単語から複数の文字からなる意味素を抽出し、前記単語意味関係単語ペアの単語の意味素間の類似度を算出し、意味素間の類似度に基づいてデータから抽出された単語ペアの類似度を算出し、単語ペアの類似度に基づいて単語ペアの単語意味関係を判定することを特徴とする。
(もっと読む)
意味属性推定装置、意味属性推定方法、意味属性推定プログラム
【課題】日本語辞書,日英対訳辞書を要することなく、単語の意味属性を自動で推定する。
【解決手段】意味属性推定装置5は、予め概念ベクトルと意味属性が付与された多数の既存単語の情報を格納した概念ベース4を備える。そして、概念ベクトル付与手段1は意味属性を推定したい単語(処理対象単語)に対して概念ベクトルを算出する。距離計算手段2は、処理対象単語と、予め概念ベース4に格納された既存単語との概念ベクトルにおける距離を算出する。意味属性候補出力手段3は、前記概念ベクトルにおける距離に基づき、処理対象単語の概念ベクトルとの距離が小さな単語を抽出し、抽出された単語の意味属性を処理対象単語の意味属性候補とする。
(もっと読む)
共起行列生成装置、共起行列生成方法、共起行列生成プログラムおよびそのプログラムを記録した記録媒体
【課題】単語・成分番号間共起に基づく手法において、対応する単語の間の意味的な類似性と識別性をより緻密に反映できる共起ベクトルまたは概念ベクトルを生成することを可能とする共起行列生成装置を提供する。
【解決手段】各行が単語に対応し、各列がN個の成分番号に対応している第1共起行列14を入力とし、該第1共起行列14の行ベクトルの集合をN´個のクラスタにクラスタリングして、単語とクラスタの成分番号を対応付ける第1クラスタリング手段11と、各行が、形態素解析されたテキストの単語に対応し、各列がN´個の成分番号に対応している第2共起行列17を生成する第2共起行列生成手段12と、任意の単語と任意の成分番号に対し、前記第1共起行列14と前記第2共起行列17の対応する要素を、線形結合した値を、対応する要素とする第3共起行列18を生成する第3共起行列生成手段13とを備える。
(もっと読む)
文書処理装置およびプログラム
【課題】言い換え生成規則の作成にかかっていたコストを削減することを可能とする。
【解決手段】解析部32は、入力文、言い換え前用例および言い換え後用例を解析することによって、解析済み入力文、解析済み言い換え前用例および解析済み言い換え後用例を作成する。類似用例選択部33は、解析済み入力文および解析済み言い換え前用例の類似度を算出する。類似用例選択部33は、算出された類似度に基づいて、解析済み言い換え前用例および解析済み言い換え後用例を解析済み類似用例ペアとして選択する。差分抽出部34は、解析済み類似用例ペアとして選択された解析済み言い換え前用例および解析済み言い換え後用例の差分を抽出する。言い換え生成部35は、解析済み入力文に、差分抽出部34によって抽出された差分を適用することによって、入力文が言い換えられた言い換え文を生成する。出力部36は、入力文の言い換え文を出力する。
(もっと読む)
自然言語テキストの自動的意味ラベリングのためのシステム及び方法
電子的又はデジタル的形式で提供される自然言語テキストの自動的意味ラベリングのためのシステム及び方法は、テキストの基礎言語解析を実行するセマンティックプロセッサを含み、テキストの意味関係におけるもの(オブジェクト)の種類、及び/又はもの(オブジェクト)のクラス、事実、及び因果関係を認識し、言語解析済みのテキストを、ターゲット意味関係の特定の例を一般化することにより生成荒れたターゲット意味関係パターンと照合し、言語解析済みのテキストとその照合とに基づき、意味関係ラベルを生成する。 (もっと読む)
情報処理装置及びプログラム
【課題】意味役割が厳密に定められず、曖昧な意味役割を持った格要素を含む文についての解析にも適用可能な構文意味辞書情報を提供する。
【解決手段】述語を含んだ標本文を取得し、当該取得した標本文において当該述語に係っている格要素の表層格と、自然言語文における表層格と意味役割との間の対応関係に関する規則と、に基づいて、当該述語に係る格要素の表層格と意味役割との対応関係に関する評価値を算出することにより、当該述語の構文意味辞書情報を生成する情報処理装置である。
(もっと読む)
自然言語処理技法を用いたテキスト入力処理システム
【課題】テキスト入力間の類似性を判定する方法、および装置の提供。
【解決手段】第一テキスト入力に対して、形態学、構文および意味に関し、自然語解析処理を行い、文章毎に適切な論理形態を作成して第一論理形態集合(1696)を得て、更に第二テキスト入力に対して、第二論理形態集合を得る。第一および第二論理形態集合を比較し(1604)、この比較(1604)に基づいて第一および第二テキスト入力間の類似性を判定する。
(もっと読む)
文章解析システム
【課題】文章に含まれる未知語の意味情報を推定して文章解析をすること。
【解決手段】本発明に係る文章解析システムは、解析対象である文章の構文解析結果を利用して、前記文章に含まれる未知語の意味情報を、前記文章に含まれる既知語の意味情報に基づいて推定する。
(もっと読む)
既存の領域定義を活用した意味概念定義および意味概念関係の統合のためのシステムおよび方法。
信頼勾配が組み込まれた既存領域概念から形式概念解析およびファセット分類統合などの異なった意味処理プロトコルを活用し、データの一領域からの概念定義および概念関係の統合のためのコンピュータによるシステムおよび方法。認識または入力エージェントはアクティブ概念の入力を備え、既存の領域概念と照合する。その結果として得られた関連した領域概念の集合は、意味処理プロトコルによって仮想概念定義を導出するために使用される。その導出されたものは、属性集合内における、属性の他の属性からの相対近接性の概念によりオーバーレイされる。その相対近接性の尺度によって、更なる一貫性の層が備えられる。最終的に、木構造の、関連する仮想概念定義の集団が結果として得られる。  (もっと読む)
(もっと読む)
機械翻訳装置、方法及びプログラム
【課題】電子メールやWeb掲示板などのやり取りの際に含まれる引用記号を利用して、同一内容の文書が文の出現順に左右されずに翻訳精度を向上させることである。
【解決手段】文書階層判定部30は、第一言語文書の文の先頭に引用記号が存在するか否かを判定し、引用記号が存在するときは文の先頭からの引用記号の個数を引用形式の階層と判定し、引用形式の階層ごとに第一言語文書の文を文書記憶部32に格納する。翻訳部29は、文書記憶部32に格納された文のうち引用形式の階層が深い順に、翻訳知識情報格納部33に格納された翻訳知識情報を利用して翻訳を行い、その翻訳の際に使用した翻訳辞書の語彙部や変換規則から訳語を選択するに有用な翻訳知識情報を取り出し翻訳知識情報格納部33に格納する。出力部28は、翻訳部29で翻訳された翻訳結果を出力装置17に出力する。
(もっと読む)
電子メッセージの読解を支援する装置及び方法
【課題】電子メッセージに含まれる単語の意味をユーザに提示するかどうかを、そのユーザが現在その単語の意味を知っているかどうかの動的な判断に基づいて決定する。
【解決手段】クライアント10において、通信制御部11は、ユーザAからユーザBへ送られたメッセージを受信し、形態素解析部12は、メッセージから単語を抽出し、履歴取得部15は、その単語のユーザBによる閲覧及び使用等に関する履歴情報を取得する。また、表示判定部18は、この取得された履歴情報と、ユーザレベル記憶部16に記憶されたユーザBの言語レベルと、辞書記憶部17に記憶されたその単語の難易度のレベルとに基づいて、その単語の意味を表示するかどうかを判定する。そして、入出力制御部19は、その単語の意味が判定結果に応じてユーザBに提示されるように制御する。
(もっと読む)
言語理解装置
【課題】大量の学習データや複雑なルールを用いずに、比較的容易に構築可能でかつ頑健さも兼ね備えた言語理解装置を提供する。
【解決手段】言語理解モデル記憶部(10)は、単語遷移のデータとコンセプト重みデータとを記憶する。有限状態変換器処理部(20)は、入力される単語系列に含まれる単語に基づき、単語遷移のデータに従って、定義された出力を理解結果候補として出力し、単語重み値を累積する。コンセプト重み付け処理部(30)は、コンセプト重みデータに従って、理解結果候補に含まれるコンセプトに対応するコンセプト重み値を累積する。理解結果決定部(40)は、出力された複数の系列の理解結果候補の中から、累積された単語重み値と累積されたコンセプト重み値とに基づき理解結果を決定する。
(もっと読む)
機械翻訳解析結果選択方式
【課題】従来の通常型フィルタリング解析方式における特定の入力原言語文に対して発生した、部分パターンに対する不適切なスコアの付与法、部分パターンが存在しない状態が発生しないようにして正しい解析結果を与える機械翻訳結果選択方式を提供することを目的とする。
【解決手段】入力原言語文の特定単語の出現順序と同一の特定単語出現順序を持つ文例を文例群の中から選び、その文例が持つその文例に対応する解析結果の全体またはその一部分を上記通常型フィルタリング解析方式の部分パターンとして用い、これに高いスコアを与えることにより結果として入力原言語文に特化した部分パターンを持つ解析結果を選ぶ。これにより正しい解析結果を得ることができる。
(もっと読む)
1 - 20 / 22
[ Back to top ]