
Fターム[5B091CC16]の内容
Fターム[5B091CC16]の下位に属するFターム
ユーザー辞書 (15)
Fターム[5B091CC16]に分類される特許
1 - 20 / 240
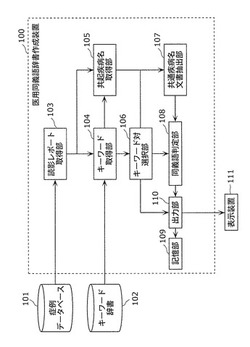
医用同義語辞書作成装置および医用同義語辞書作成方法
【課題】複数種類の疾病名が混在する医用文書に対して同義語となるキーワードの組を正しく、かつ小さい処理負荷で抽出する同義語辞書作成装置を提供する。
【解決手段】読影レポートからキーワードを取得するキーワード取得部104と、取得したキーワードと共起する疾病名を取得する共起疾病名取得部105と、取得したキーワードから一組のキーワード対を選択するキーワード対選択部106と、(i)取得した疾病名の中から、キーワード対を構成する各キーワードと共起する疾病名を選択し、(ii)選択した疾病名からキーワード対を構成するキーワード間で共通する疾病名を抽出し、(iii)抽出した疾病名を含む読影レポートを、症例データベース101に記憶されている症例データの中から抽出する共通疾病名文書抽出部107と、抽出した読影レポートを用いて、キーワード対が同義語であるか否かを判定する同義語判定部108とを備える。
(もっと読む)
単語属性推定装置及び方法及びプログラム

【課題】 他の単語データを利用して、属性が未知である単語に対し、付与すべき属性を推定する。
【解決手段】 本発明は、入力単語と共起する単語のパターンを特徴パターンとして抽出し、入力された単語共起データから特徴パターンと合致する共起語を入力単語の同類語候補として抽出し、入力単語及び各同類語に対し、共起する単語のパターンを特徴パターンとして抽出し、その特徴パターンを要素とし、その共起頻度を値とするベクトルを作成する。入力単語と各同類語候補との関連度を算出し、関連度の高いものを同類語として抽出する。同類語のカテゴリの重複数を調べて、重複数が多いカテゴリを入力単語のカテゴリとして推定し、当該カテゴリを属性として付与した単語を属性付単語として出力する。
(もっと読む)
機械翻訳辞書作成装置、機械翻訳辞書作成方法、およびプログラム
【課題】機械翻訳用の辞書への新語の登録において、簡易な処理で、世の中で広く用いられている訳語を登録する。
【解決手段】検索に用いられた検索キーワードについて、検索回数と検索キーワードの翻訳辞書8への登録の有無を検索履歴6として記録する検索履歴生成部5と、翻訳辞書8に登録されていない検索キーワードについて、翻訳辞書8に登録されている複数の単語に分解し、各々の単語に対して複数の訳語が登録されている場合には、それぞれの訳語を組み合わせて複数の訳語候補を作成し、各々の訳語候補について翻訳辞書8への登録の有無を確認し、登録されている場合には、検索回数が最も多いものを訳語に決定して翻訳辞書8に登録する翻訳辞書生成部7と、を備える。
(もっと読む)
辞書作成装置、辞書作成方法、およびプログラム
【課題】効率的に言語解析用の辞書を作成する辞書作成装置等を提供する。
【解決手段】未知語判定プログラム25は、記憶部から書籍のOCRデータを入力し、書誌情報データベース21と照合して作者及びジャンルを特定するとともに、処理対象の語句が、未知語か否かを判定する。未知語の語句については、辞書登録プログラム26に処理を引き渡す。辞書登録プログラム26は、作者別辞書登録プログラム26A、ジャンル別辞書登録プログラム26Bを含み、作者別辞書データベース22、ジャンル別辞書データベース23、および標準辞書データベース24に未知語を登録する。
(もっと読む)
辞書管理装置、辞書管理方法、辞書管理プログラム
【課題】オンライン辞書について辞書管理の負担を軽減させた高品質な類似検索機能を提供する。
【解決手段】類似検索部3は、辞書管理者の入力表記に基づき全体辞書を検索し、入力表記に類似する表記を特定する。主要部特定部4は、類似検索手段で特定された類似表記と入力表記との共通部分を特定し、特定された共通部分が主要部辞書に存在すれば、該共通部分を主要部候補と判定する。この主要部候補を類似表記から除外した付加部候補が付加部辞書に存在するか否かを判定し、判定結果に応じて主要部候補を主要部と確定する。距離算出部5は、確定された各類似表記の主要部と入力表記の主要部との編集距離を算出する。更新確認部6は、算出された編集距離順に類似表記・主要部・付加部を辞書管理者に提示する。
(もっと読む)
情報処理装置、データベース更新方法およびデータベース更新用プログラム
【課題】データベースの最適化に係る作業を効率化し、ユーザの負担を軽減することを課題とする。
【解決手段】文書データを解析するための解析キーを含む解析用データが蓄積されるデータベースに接続される情報処理装置に、データベースから、解析キーの構成を把握するための基準となる1または複数の解析キーを、単位解析キーとして抽出する単位解析キー抽出部25と、単位解析キーを用いて、データベースに含まれる解析キーの構成を把握する構成把握部26と、構成把握部26によって把握された構成に従って、単位解析キーに関連づけられた情報を用いて、データベースに含まれる解析キーに関連づけられる情報を更新するデータベース更新部29と、を備えた。
(もっと読む)
情報処理装置、データベース更新方法およびデータベース更新用プログラム
【課題】ユーザがデータベースの構造を意識することなくデータベースの更新を行うことを可能とし、ユーザの負担を軽減することを課題とする。
【解決手段】文書データを解析するための解析キーを含む解析用データが蓄積されるデータベースに接続される情報処理装置に、データベースの更新に用いられる解析キーである更新用解析キーを取得する更新用解析キー取得部21と、解析用データに含まれる情報と、更新用解析キーに関連付けられた情報との適合程度を判定する適合程度判定部23と、適合程度判定部23による判定結果に応じて、更新用解析キーを用いてデータベースを更新する際の更新処理の内容を決定する更新処理内容決定部24と、更新処理内容決定部24によって決定された更新処理の内容に従って、更新用解析キーおよび当該更新用解析キーに関連付けられた情報をもって、データベースを更新するデータベース更新部29と、を備えた。
(もっと読む)
文書処理装置およびプログラム
【課題】類義語として適切な用語を文書から抽出することが可能な文書処理装置およびプログラムを提供することにある。
【解決手段】用語抽出手段は、文書格納手段に格納されている複数の文書から第1および第2の用語を抽出する。クラスタ生成手段は、複数の文書の各々が属するクラスタを生成する。特徴度算出手段は、複数の文書および生成されたクラスタに属する文書における第1の用語の出現頻度に基づいて当該クラスタに対する第1の用語の特徴度を算出し、複数の文書およびクラスタ生成手段によって生成されたクラスタに属する文書における第2の用語の出現頻度に基づいて当該クラスタに対する第2の用語の特徴度を算出する。類義語抽出手段は、算出された類似度、算出された第1の用語の特徴度および第2の用語の特徴度に基づいて当該第1および第2の用語を類義語として抽出する。
(もっと読む)
用語対訳抽出装置、用語対訳抽出方法、および用語対訳辞書の生産方法
【課題】従来、正しい用語対訳を自動抽出する場合、学習データや対訳辞書が必要であった。
【解決手段】対訳データベースから1以上の品詞情報パターンに合致する1以上の対訳フレーズを取得する対訳フレーズ取得部と、対訳フレーズ取得部が取得した1以上の対訳フレーズから、第一言語の用語と用語に対応する第二言語の用語の組の候補である1以上の用語対訳候補を取得する用語対訳候補取得部と、2以上の異なる方法により、2以上の各用語対訳候補に対して、スコアを算出し、2以上のスコアを取得するスコア算出部と、2以上のスコアを用いて、2以上の用語対訳候補のうちの一部を選択して蓄積する用語対訳蓄積部とを具備する用語対訳抽出装置により、正しい用語対訳を自動抽出する場合、学習データや対訳辞書が不要である。
(もっと読む)
単語帳作成装置及び単語帳作成プログラム
【課題】学習効率を低下させずに容易に単語帳データを作成する。
【解決手段】電子辞書1は、複数の見出し語を有する辞書データベース820を複数記憶するフラッシュROM80と、科目毎に、辞書データベース820の何れかを検索対象辞書データベース820Tとして記憶する科目別検索条件テーブル87と、外部からテキストデータ851を取得するとともに、当該テキストデータ851の科目を検知するCPU20とを備える。CPU20は、テキストデータ851に含まれる各単語を検出するとともに、テキストデータ851の科目に対応する検索対象辞書データベース820Tを検出し、検出された単語から、当該検索対象辞書データベース820Tに見出し語として存在する単語を抽出する。単語帳テーブル86は、CPU20により抽出された単語と、テキストデータ851の科目とを対応づけて記憶する。
(もっと読む)
言語モデル学習装置及びコンピュータプログラム
【課題】対象となる分野またはアプリケーションで発せられる可能性のある自然言語文を効率よく生成できる自然言語文生成装置を提供する。
【解決手段】自然言語文生成装置30は、単語列テンプレートを記憶する拡張テンプレート集合記憶部56と、拡張テンプレート集合記憶部56に記憶された単語列テンプレートに合致する単語列パターンをWebコーパス32から抽出するフィルタ60と、予め選択された目的に沿った形式の自然言語の単語列が生成されるように準備された変形規則を記憶する変形規則記憶部64と、変形規則記憶部64に記憶された変形規則に基づいて、フィルタ60により抽出された単語列を変形する変形モジュール66とを含む。
(もっと読む)
情報処理装置、方法及びプログラム
【課題】与えられた文脈からは類型が不明な名詞の類型を判定する。
【解決手段】検索エンジンの検索結果における名詞に関する文脈に基づくことにより、与えられた文脈からは類型が不明な名詞についても名詞の類型が判定できるので、判定した類型を、例えば関連検索における関連検索ワードの提示や、ウェブ検索結果のリスト順の制御に反映するなど、ユーザの意図に基づく情報処理結果の最適化に活用可能となる。要約の所定数に対し、類型ごとに、対応するパターンで判定対象の名詞が用いられているなどで判定された数量を集計し、その多いものを優先して判定結果として後処理へ渡すなどの形で出力することにより、複数の類型に該当する名詞についても、最も一般的な類型、又は数番目までの主要な類型を判定結果として利用できるので、多くのユーザの意図に合致する情報処理結果の最適化が可能となる。
(もっと読む)
孔版印刷システム
【課題】作像エンジンがモノクロベースでカラースキャナ搭載という構成・仕様であっても、カラースキャナのポテンシャルを十分活用することができる孔版印刷システムを提供する。
【解決手段】原稿と、複数の色により原稿上の特定のエリアが指定されたカラーコマンドシートと、をカラー画像として読み取る読取手段と、読取手段により読み取られた原稿のうち、カラーコマンドシートに指定された特定のエリア内の単語を解析する解析手段と、解析手段により解析された単語のうち、第1の色で指定された特定のエリア内の単語を翻訳する翻訳手段と、を有する。
(もっと読む)
同義語辞書生成装置、データ解析装置、データ検出装置、同義語辞書生成方法及び同義語辞書生成プログラム
【課題】異なる複数の文章に含まれる単語を用いて同義語を検出することが可能であって、汎用性を有し、幅広く同義語を定義することが可能な同義語辞書生成装置等を提供する。
【解決手段】文書解析システム100は、入力インターフェース110を介して取得した各アンケートデータに対して、評価表現を示す評価表現テキストと当該評価テキストが修飾する被修飾語テキストのセットをテキストセットとして抽出しつつ、評価表現テキスト、カテゴリ情報及び被修飾語テキストの出現頻度数に基づいて同義語を定義するようになっている。
(もっと読む)
意味的に類似している語対を二項関係に分類する二項関係分類プログラム、方法及び装置
【課題】名詞間関係及び動詞/形容詞間関係を一括して語間関係として扱い、獲得したい語間関係を予め定義することなく、意味的に類似している語対を二項関係に分類することができる二項関係分類プログラム等を提供する。
【解決手段】文章集合蓄積部から所定閾値以上で共起しやすい複数の語対を抽出し、文章集合蓄積部から語対の語毎に共起する係り受け語集合を抽出する。次に、第1の係り受け語集合に出現し且つ第2の係り受け語集合に出現しない係り受け語からなる第1の特徴係り受け語集合と、第2の係り受け語集合に出現し且つ第1の係り受け語集合に出現しない係り受け語からなる第2の特徴係り受け語集合とを抽出する。更に、係り受け語毎に、語と共起する文書集合中の出現頻度とを計数し、ベクトルを導出し、ベクトル間類似度に基づく分割最適化クラスタリングによって、語対クラスタを生成する。
(もっと読む)
対訳辞書生成装置、方法及びプログラム
【課題】対訳辞書の自動生成を実現する。
【解決手段】ある言語のページ内の画像と類似する画像を含む他の言語のページを類似画像検索で抽出し、双方のページがヒットする検索キーワードをウェブ検索等のログから取得することにより、相互に似た画像を指す異なる言語の単語やフレーズが対応付けできるので、対訳辞書の自動生成が可能となる。一つの基準ページに対して所定数の前記類似画像ページ(例えば、日本語ページの画像を基に類似度1位から10位までの中国語ページを抽出するなど)を抽出して検索キーワードを取得することにより、抽出結果のばらつきを抑制して普遍性ある単語同士を対応付けできるので、高精度な対訳辞書を生成可能となる。
(もっと読む)
プログラム及び同義語生成装置
【課題】文又は節に含まれる主語と述語の組合せと同義の、接頭辞付きの単語を生成する。
【解決手段】接頭辞・述語表現対照表20は、接頭辞ごとに、接頭辞の意味を表す述語表現のリストを有する。構文意味解析部12は、対象文入力部10に入力された対象文に対して構文意味解析を実行し、主語と述語の組を抽出する。単語候補生成部14は、抽出された述語に対応する接頭辞を接頭辞・述語表現対照表20から求め、求めた各接頭辞をその主語に連結することで、主語と述語の組と同義である単語の候補を生成する。同義語判定部16は、生成された候補の中から、標準辞書22の語彙に含まれるものを選別し、これをその主語と述語の組に対応する接頭辞付き同義語として出力する。
(もっと読む)
感性辞書編集支援システム及びプログラム
【課題】自然文からユーザの価値判断が示されている表現を抽出する際に参照する感性辞書を効率的に編集できるように支援する技術の実現。
【解決手段】事物に対する肯定/否定の価値判断を表す感性用語と、肯定/否定の何れであるかを示す極性との組合せを格納しておく感性辞書記憶部18と、複数の用語について、各用語の類義語を定義したデータが格納された類義語辞書記憶部34と、起点語が入力された場合に、この起点語をキーに類義語辞書記憶部34を検索して起点語の類義語を抽出し、各類義語をキーに類義語辞書記憶部34を検索して各類義語の類義語を抽出し、抽出された用語のリストを含む感性用語登録画面80を生成してクライアント端末58に送信し、この画面80を介してリスト中の1または複数の用語を選択する情報と、各用語の極性を指定する情報が入力された場合に、選択された用語を指定された極性に関連付けて感性辞書記憶部18に格納する辞書編集支援部38を備えた。
(もっと読む)
文字列ベクトル変換装置、文字列ベクトル変換方法、プログラム、及びプログラムを格納したコンピュータ読み取り可能な記録媒体
【課題】意味表現として適切な文字列ベクトルを生成することを課題とする。
【解決手段】文字列ベクトルデータベース1と、テキストとを入力とし、前記文字列ベクトルデータベース1の複製である文字列ベクトルデータベース2を生成した後、前記テキスト中の、連続する有限個の単語の列である所定の範囲に存在する、前記文字列ベクトルデータベース1中の文字列A、Bの任意の対に対し、当該文字列Aの前記文字列ベクトルデータベース2中のベクトルに、前記文字列Bの前記文字列ベクトルデータベース1中のベクトルv(B)をスカラー倍したものを加算し、前記文字列Bの前記文字列ベクトルデータベース2中のベクトルに、前記文字列Aの前記文字列ベクトルデータベース1中のベクトルv(A)をスカラー倍したものを加算することを、前記テキスト中の全ての前記所定の範囲にわたって繰り返し、その結果得られた文字列ベクトルデータベース2を出力する。
(もっと読む)
不具合を示す述語表現を抽出するための不具合述語表現抽出装置、不具合述語表現抽出方法及び不具合述語表現抽出プログラム
【課題】不具合を示す述語表現を自動で抽出することのできる技術を提供する。
【解決手段】不具合述語表現抽出装置100は、突然性を示す連用修飾表現または再現性を示す連用修飾語のいずれか一方の近傍に現れる述語表現を、不具合を示す述語表現の候補として抽出し、また、常性を示す連用修飾表現の近傍に現れる述語表現を、正常を示す述語表現として抽出し、不具合を示す述語表現の候補のリストから、正常を示す述語表現を取り除いて、不具合を示す述語表現を抽出する。
(もっと読む)
1 - 20 / 240
[ Back to top ]