
Fターム[5B091EA02]の内容
Fターム[5B091EA02]に分類される特許
1 - 20 / 116
知識量推定情報生成装置、知識量推定装置、方法、及びプログラム
文書分析システム、文書分析方法およびプログラム
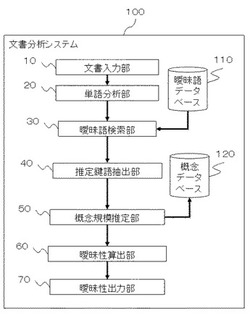
【課題】 曖昧語を含む文書について、各使用場面で曖昧語が文書の品質に与える影響の大きさを考慮して、精度よく文書の優先的な修正点や品質を推定する技術を提供する。
【解決手段】 本発明における文書分析システムは、外部から入力された文書を構成する文章に使用されている各単語の単語情報に基づいて、文書中における曖昧語を検索し、曖昧語が有る場合は当該曖昧語を抽出する曖昧語検索部と、推定鍵語を抽出するための推定鍵語抽出ルールに基づいて、文書から各曖昧語に対するそれぞれの推定鍵語を抽出する推定鍵語抽出部と、概念規模推定ルールに基づいて、推定鍵語抽出部で抽出された推定鍵語の概念の規模である概念規模指標を推定する概念規模推定部と、概念規模指標に基づいて、各曖昧語と推定鍵語との組合せ毎に曖昧性情報を算出する曖昧性算出部と、を含む。
(もっと読む)
自然言語処理装置、自然言語処理方法および自然言語処理プログラム

【課題】解析対象となる文書の言語およびドメインを考慮して、その文書に適した解析器を作成する自然言語処理装置を提供する。
【解決手段】自然言語処理装置100は、対訳記憶手段と対訳検索手段と単語抽出手段と正解作成手段と解析器生成手段とを備える。対訳記憶手段は、未知言語の文書と一又は複数の既知言語の文書とからなる複数の対訳文書、およびそのドメインを記憶する。対訳検索手段は、ドメインを指定して、対訳記憶手段から対訳文書を検索する。単語抽出手段は、対訳検索手段で検索された対訳文書から、未知言語の単語と既知言語の単語とを対応付けた単語ペアを抽出する。正解作成手段は、単語ペア、および検索された対訳文書における既知言語の文書の解析結果を用いて、検索された対訳文書における未知言語の文書の解析結果を推定する。解析器生成手段は、未知言語の文書の解析結果を用いて、未知言語の解析器を生成する。
(もっと読む)
学習装置、判定装置、学習方法、判定方法、学習プログラム及び判定プログラム
【課題】照応解析において先行詞及び照応詞を判定する精度を向上可能な照応解析技術を提供する。
【解決手段】学習装置は、文章と、前記文章内で照応関係を有する各要素の後方境界と、先行詞となる第1の要素及び照応詞となる第2の要素の対応関係とを示す訓練データの入力を受け付け、訓練データに基づいて、任意の文章において照応関係の有無を判定するための判定基準を学習する。判定装置は、文章と、前記文章内で照応関係を有する可能性のある各要素の後方境界とを示すユーザデータの入力を受け付け、ユーザデータに基づいて、学習装置が学習した判定基準に従って、文章において照応関係の有無を判定する。
(もっと読む)
読み推定装置、読み推定方法、および読み推定プログラム
【課題】誤った読み仮説と読み推定対象単語の表記がたまたま同一文書内に現れていることが原因で読み推定の精度が劣ることを防止し、高精度で読み推定を行うこと。
【解決手段】読み仮説生成部101は、読み推定対象単語に対し、複数の読み仮説を生成する。また、共起スコア計算部103は、複数の読み仮説の各々について、予め準備された文書群における読み推定対象単語との共起関係を用いて共起スコアを求める。そして、仮説選択部105は、共起スコアに基づき、複数の読み仮説から1つ以上の読み仮説を選択する。ここで、共起スコア計算部103は、読み推定対象単語および読み仮説の双方が現れる文書の数のみならず、該文書内における読み推定対象単語と読み仮説との間の距離を上記共起関係として求め、当該求めた共起関係に基づき共起スコアを求める。
(もっと読む)
自動単語対応付け装置とその方法とプログラム
【課題】トピックを導入した同義語辞書モデルを構築させ、その同義語辞書モデルと従来の単語対応付けモデルとを同時に用いた自動単語対応付け装置を提供する。
【解決手段】この発明の自動単語対応付け装置は、訓練データ記憶部と、アライメント確率学習部と、自動対応付け部と、を具備する。訓練データ記憶部は、単語で区切られた原言語と目的言語の対訳文の組みで構成される対訳文コーパスと、上記目的言語の同義語の組の集合である同義語辞書とから成る。アライメント確率学習部は、トピック毎に、対訳文コーパスの対数尤度と同義語辞書の対数尤度との重み付き和を最大にするパラメータを学習する。自動対応付け部は、対象翻訳文とそのパラメータを入力として対象翻訳文の原言語と目的言語の単語間のアライメントを生成する。
(もっと読む)
多言語文法解析装置、多言語文法解析方法および多言語文法解析プログラム
【課題】複数の言語で記述された文集合から個別言語の文法と共に言語共通の文法を推定する技術を提供すること。
【解決手段】多言語文法解析装置1は、個別文法パラメータ集合46と、共通文法パラメータ集合45と、入力多言語データ44とを記憶する記憶手段4と、言語毎に、記憶されている情報に基づいて、構文木確率を推定する処理と、記憶されている情報および推定された構文木確率に基づいて、個別文法のパラメータを推定して更新する処理とを交互に実行することで、各言語の文法を推定する個別文法推定部21と、更新された各言語の個別文法のパラメータと、記憶されている共通文法パラメータとに基づいて、新たな共通文法パラメータを推定して更新する共通文法推定部22と、各言語の文法を推定する処理と、言語共通の文法を推定する処理とを終了条件が満たされるまで交互に繰り返し実行させる推定処理制御部23とを備える。
(もっと読む)
株価影響企業検知システム及びプログラム
【課題】株価に影響を与えるイベントの有無を自動的に検知すると共に、このイベントによって株価に影響を受ける具体的な企業名を提示可能な技術の実現。
【解決手段】イベント情報を格納するイベント情報記憶部38と、各企業の属性情報を登録しておくオントロジ記憶部42と、イベントの属性と当該イベントによって株価に影響を受ける企業の属性との組合せパターン毎に、株価に与える影響がプラスかマイナスかを定義した推論ルールを格納する推論ルール記憶部40と、各イベント情報に対して推論ルールを適用し、当該イベントによって株価に影響が及ぶ企業の属性を特定すると共に、オントロジ記憶部42を参照して当該属性を備えた企業を株価影響企業として抽出し、株価影響企業のリストを生成してWebサーバ44に出力する株価影響企業抽出部26を備えた株価影響企業検知システム10。
(もっと読む)
コンテキスト上関連するタスクアイテムの自動発見
ユーザが、作業コンテキストに関連付けられたドキュメントおよび他の情報を自動的に回復し、特定のプロジェクトに関連付けられたドキュメントおよび他の情報アーティファクトを回復できるようにするアーキテクチャである。当該アーキテクチャにより、特定の作業コンテキストに関する情報アーティファクトとのユーザ対話に関連する活動情報を監視し、記録することができる。ユーザは、作業コンテキストに関連する作業コンテンツの一部(例えば、ドキュメント内の項目または他種の参照アイテム)を有するドキュメントを選択することができる。活動情報と参照アイテムに対して字句分析を行って字句類似度を特定する。候補アイテム(例えば、関連ドキュメント)のリストを、字句類似度に基づいて情報アーティファクトから推論する。作業コンテキストに関連する候補アイテムをユーザに提示し、当該ユーザは特定のアイテムを選択して作業コンテキストを再構築することができる。 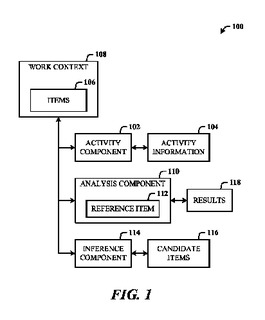 (もっと読む)
(もっと読む)
情報圧縮型モデルパラメータ推定装置、方法及びプログラム
【課題】従来と同等な推定精度を確保しつつ汎用の計算機でモデルパラメータの推定処理を可能とする。
【解決手段】それぞれ重要度ei,jが割り当てられ素性ベクトルで表現された複数のシンボル系列fi,jからなる1以上のリストiと各リストiの正解シンボル系列fi,0とが入力され、モデルパラメータを推定する装置であり、グルーピング部とマージング部とモデルパラメータ推定部とを備える。グルーピング部はリストに属する複数のシンボル系列fi,jを複数のグループに分ける。マージング部はグループ内の複数のシンボル系列fi,jから代表シンボル系列fi,xを、グループ内の複数のシンボル系列fi,jに対応する複数の重要度ei,jから代表重要度ei,xをそれぞれ求める。モデルパラメータ推定部は代表シンボル系列fi,xと正解シンボル系列fi,0と代表重要度ei,xとからモデルパラメータを推定する。
(もっと読む)
モデルパラメータ推定装置、方法及びプログラム
【課題】従来より高精度にモデルパラメータを推定することを可能とする。
【解決手段】それぞれ重要度ei,jが割り当てられ素性ベクトルで表現された複数のシンボル系列fi,jからなる1以上のリストiとそれぞれ重要度ei,0が割り当てられ素性ベクトルで表現された各リストiの正解シンボル系列fi,0とが入力され、モデルパラメータwを推定する装置であり、重要度変換部とモデルパラメータ推定部とを備える。重要度変換部は、重要度ei,jをリストごとに所定のシンボル系列の重要度の値が上記所定のシンボル系列以外のシンボル系列の重要度の値に比べ相対的に大きな値になるように変換する。モデルパラメータ推定部は、シンボル系列fi,jと正解シンボル系列fi,0と変換後の重要度とからモデルパラメータwを推定する。
(もっと読む)
言語解析装置及びプログラム
【課題】文に含まれる括弧表現について構文解析時に文から分離すべきか否かを実例に即して分類する。
【解決手段】言語解析装置10は、文情報を格納した文書群格納部12から括弧表現が含まれる文情報を取得し、予め定められた規則に従って、上記取得した文情報に含まれる括弧表現を当該文情報から分離する第1の類型と分離しない第2の類型に仮分類し、当該括弧表現の仮分類結果に基づいて、括弧表現を第1の類型と第2の類型とに分類する規則を学習する機械学習部20により学習された規則に基づいて、所与の文に含まれる括弧表現を第1の類型又は第2の類型に分類する。
(もっと読む)
自動応答文生成システム
【課題】 従来の自動応答文生成は,インターネット上の掲示板やブログ,チャットなど,利用者がどのような事項に対する対話を行うか不明確であるとともに,対話が進むにつれ話題が変化することもしばしばあるため,あらかじめ応答文もしくは応答すべき事項の知識を準備することは不可能であり,しばしば,まったく整合性のない応答文が生成されるという問題が生じていた.
【解決手段】 人間が発信した言語情報からキーワードを抽出し,このキーワードに対してインターネットにおけるWeb上の情報を収集しキーワードを補完し,これらのキーワードに対して分野連想語辞書を照合することで,まず人間が発信した言語情報がどのような話題の言語情報であるかを確定する.その後,人間が発信した言語情報から抽出したキーワードおよびその分野情報と応答文の雛形となる文テンプレートから文生成を行うことで,不特定の話題であっても話題に対して適切な応答文を生成することを特徴とする.
(もっと読む)
認識パラメータチューニング方法
【課題】電子文書に対する認識プログラムに関して、既存の認識パラメータを既存文書に対して適用したときの文書情報に関する認識精度をなるべく維持し、文書全体として認識精度が向上するような、パラメータチューニング手法を提案する。
【解決手段】電子文書から文書情報を認識する認識プログラムの認識精度を変更する認識パラメータチューニング方法であって、認識処理部が、二つのトレーニング文書群の各々に対して一つの認識パラメータをもとに認識処理を実行し、該認識処理の認識精度を表す正答率を計算するステップと、表示処理部が、前記認識処理に対する各々の認識結果および正答率を表示するステップと、を有することを特徴とする。
(もっと読む)
言語処理装置
【課題】参照表現の理解及び生成の双方に対応可能な確率モデルを使用した言語処理装置の提供。
【解決手段】物体を、属性値表現と該属性値表現が修飾する部分指示表現とからなる部分的な参照表現の対の集合であって、物体全体に関する対を含む対の集合が表す確率をそれぞれの部分的な参照表現の対が、該物体を表す確率の積で表し、部分的な参照表現の対が該物体を表す確率を、物体の選択される確率、物体の部分の顕現性を表す確率、物体の部分と属性値との関係を表す確率、物体の部分に対して部分指示表現が使用される確率、属性値に対して属性値表現が使用される確率を使用して求める確率モデルを有する確率演算部103と、該確率モデルに使用される確率の値を記憶する少なくとも一つの記憶部101とを備え、該確率演算部が、該少なくとも一つの記憶部に記憶した確率の値および該確率モデルを使用し、部分的な参照表現の対の集合が物体を表す確率を演算する。
(もっと読む)
機械翻訳装置
【課題】見出し語の一部の文字を入力するだけで、終止形・原型の適切な見出し語を得ることである。
【解決手段】見出し語情報取得部23は、辞書部への語句の登録・参照・削除操作時に入力部16から見出し語として入力された情報を取得し、入力予測範囲取得部24は、翻訳対象の第一言語の原文を入力予測範囲として取得する。翻訳部25は、入力予測範囲に存在する文の形態素解析を辞書部21を用いて行い、語頭・末尾推定部26は、翻訳部25で形態素解析された語句の語頭・末尾となる部分を判断し見出し語候補を推定する。そして、終止形・原型復元部27は、見出し語候補が終止形・原型でないときは見出し語候補を終止形・原型に復元し、制御部22は、得られた見出し語候補の語句を表示部17に表示する。
(もっと読む)
言語モデル作成方法、言語モデル作成装置および言語モデル作成プログラム
【課題】教師データを用いずとも、言語モデルの作成と単語分割とを行えるようにする。
【解決手段】言語モデル作成装置は、文字列データ131に格納された複数の文をランダムな順に選択し、言語モデル132を用いて、この選択した文における単語の区切り目の候補となる文字列を示した文字列分割パターン群を作成する。また、その文がその文字列分割パターン群の文字列分割パターンに該当する確率を記憶部に記録しておき、この確率に従って、文字列分割パターン群の中から、文字列分割パターンを選択する。そして、この選択した文字列分割パターンを用いて言語モデル132を更新する。このような処理を、文字列データ131に格納された複数の文すべてについて実行し、言語モデル132を最適化する。そして、このようにして最適化された言語モデル132を用いて、文の最尤単語分割を実行する。
(もっと読む)
テキスト・データに含まれる固有表現又は専門用語から用語辞書を作成するためのコンピュータ・システム、並びにその方法及びコンピュータ・プログラム
【課題】単語カテゴリの用語辞書を構築する場合に、新規追加されたテキストから、登録すべき単語を漏れなく見つけ、且つ作業を効率的に行う。
【解決手段】テキスト・データの形態素解析を行い、トークン列データを取得する形態素解析部と、上記トークン列データの各トークンをカテゴリ辞書を用いて判別し、未カテゴリ語を抽出するカテゴリ判別部と、抽出した未カテゴリ語を未カテゴリ語照合ルールと照合し、該未カテゴリ語照合ルールに合致する未カテゴリ語を登録候補語として抽出する未カテゴリ語照合部と、上記未カテゴリ照合部と、上記トークン列データのトークン列をトークン列照合ルールと照合し、該トークン列照合ルールに合致するトークン列を登録候補語として抽出するトークン列照合部とを含み、上記カテゴリ辞書に上記登録候補語を登録するかどうかの選択をユーザに許す許可部とで構成されるコンピュータシステム。
(もっと読む)
コンパラブルコーパスを使用する固有表現の翻字
第1の言語の文書、および第2の言語の追加文書を検査することができる。追加文書が、第1の言語の文書に十分類似しているかどうか判定することができる。追加文書が第1の言語の文書に十分類似していると判定される場合には、文書内の固有表現を選択することができる。この方法では、文書内の固有表現と追加文書内の単語とを比較し、文書内の固有表現と単語が十分類似しているかどうか判定することにより、類似している固有表現を調査することができる。文書内の固有表現に類似する単語が検出されると、文書内の固有表現および類似する固有表現を、固有表現の翻字として記憶することができる。  (もっと読む)
(もっと読む)
質問推定方法及びプログラム
【課題】質問者の発言を記録することなく、回答者の発言から質問内容を推定する。
【解決手段】特定の認識結果データブロックの識別子に対応して、表示データのブロック識別子を抽出する工程と、抽出された表示データのブロック識別子に対応する各説明文について文構成要素を抽出し、各説明文について、各組み合わせルールに従って、抽出された文構成要素を組み合わせて複数の仮想回答文を生成し、特定の認識結果データブロックの内容と複数の仮想回答文とを比較して、仮想回答文毎に一致度を算出する工程と、所定の条件を満たす一致度が算出された仮想回答文の基となる組み合わせルールに係る質問文類型を特定し、特定の認識結果データブロックの識別子に対応して格納する工程とを含む。
(もっと読む)
1 - 20 / 116
[ Back to top ]