
Fターム[5B091EA04]の内容
Fターム[5B091EA04]の下位に属するFターム
スペルチェック (16)
Fターム[5B091EA04]に分類される特許
1 - 20 / 34
契約チェック支援装置及び契約チェック支援プログラム
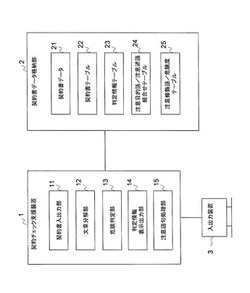
【課題】契約書に含まれる文章の危険度を判定し契約書のチェックを支援する契約チェック支援装置を提供する。
【解決手段】文章分解部12が、契約書データ格納部2に格納された契約書データ21に含まれる文章の各々を分解して、文章に含まれる目的語、述語及び修飾語を抽出すると、文章分解部12が抽出した目的語と述語との組合せが注意目的語/注意述語組合せテーブル24に存在し、文章分解部12が抽出した修飾語が注意修飾語/危険度テーブル25に存在する場合に、危険判定部13が、注意修飾語/危険度テーブル25から修飾語に対応する危険度を求める。
(もっと読む)
言語解析システム及び言語解析方法

【課題】英文で記載された文章の時制の正誤の自動解析をコーパスを収容したデータベースにより行う言語解析システム及び言語解析方法の提供。
【解決手段】データベースから文章を抽出しこれを構成する単語又は句に品詞タグを与える上で、動詞のうち、習慣的動作を表すものではない動作動詞についてはこれを示す動作動詞タグを与え、動作動詞と、動詞のタグを与えられた単語に関する複数の素性と、の相関についての分類器を得ておく。少なくとも解析部において、英語で記載された解析対象の文章の品詞を推定し素性について素性ベクトルに変換する。分類器に素性ベクトルを与えて動詞について動作動詞であり且つ単純現在であるときを文章の時制誤りとする。
(もっと読む)
誤字脱字対応テキスト解析装置及び方法及びプログラム
【課題】 誤字や脱字などの表記ゆれを含むテキスト文書の形態素解析を高精度に行う。
【解決手段】 本発明は、入力テキストを形態素解析して単語列データを出力し、入力テキストの単語の所定の文字長の単語について近似照合し、近似辞書照合単語列データを出力し、単語列データと近似辞書照合単語列データを用いて誤字脱字修正を行う。誤字脱字修正を行う際に、単語列データと近似辞書照合単語列データの単語の照合タイプに基づいて、所定の重みを付与し、さらに、2つの単語列データの単語の近似文字状況に応じて、該単語列データと該近似辞書照合単語列データとに重みを付与し、重み付け単語列データを出力し、重み付け単語列データの各位置に存在する単語候補について、統計的言語モデル記憶手段を参照して、単語列毎に付与した重みを考慮した表記列と品詞列の同時確率Pweight(F,T)の同時確率が最大となる最尤単語列を修正済み単語列データとして出力する。
(もっと読む)
ConditionalRandomFieldsもしくはGlobalConditionalLog−linearModelsを用いる学習装置及びその学習装置におけるパラメータ学習方法、プログラム
【課題】Conditional Random FieldsもしくはGlobal Conditional Log-linear Modelsを用いる学習装置において、学習精度を向上させ、モデル性能の向上を図る。
【解決手段】複数のシンボル系列の素性ベクトルと、対応する正解シンボル系列の素性ベクトルと、各シンボル系列のシンボル系列重みとからなるリストの集合を学習データとして取り込むリスト入力部11と、目的関数のパラメータ初期化部21と、パラメータと素性ベクトルの内積により線形スコアを算出し、その線形スコアとシンボル系列重みから指数スコアを算出するリスト内処理部22と、リスト内処理部22で算出された全ての指数スコア及び素性ベクトルを用いて目的関数及びその傾きを算出する目的関数算出部23と、前記傾きから目的関数の収束を判定する収束判定部24と、パラメータを更新するパラメータ更新部25とを備える。
(もっと読む)
モデルパラメータ推定装置、方法及びプログラム
【課題】従来より高精度にモデルパラメータを推定することを可能とする。
【解決手段】それぞれ重要度ei,jが割り当てられ素性ベクトルで表現された複数のシンボル系列fi,jからなる1以上のリストiとそれぞれ重要度ei,0が割り当てられ素性ベクトルで表現された各リストiの正解シンボル系列fi,0とが入力され、モデルパラメータwを推定する装置であり、重要度変換部とモデルパラメータ推定部とを備える。重要度変換部は、重要度ei,jをリストごとに所定のシンボル系列の重要度の値が上記所定のシンボル系列以外のシンボル系列の重要度の値に比べ相対的に大きな値になるように変換する。モデルパラメータ推定部は、シンボル系列fi,jと正解シンボル系列fi,0と変換後の重要度とからモデルパラメータwを推定する。
(もっと読む)
対訳文書校正装置
【課題】第一言語文書及び第二言語文書の双方を校正した場合であっても校正内容の適性を判断できる対訳文書校正装置を提供することである。
【解決手段】文書解析手段28は、校正前の第一言語文書、校正前の第二言語文書、校正後の第一言語文書及び校正後の第二言語文書を解析し、校正内容分類手段30は、その解析情報に基づいて、校正前の第一言語文書と校正後の第一言語文書、及び校正前の第二言語文書と校正後の第二言語文書とを比較し、校正内容を分類してその校正分類を求め、校正内容適性判断手段32は、解析情報及び校正分類とに基づいて校正内容の適性を判断する。
(もっと読む)
自動翻訳対応電話機および自動翻訳対応電話システム
【課題】話者が発する音声に含まれる話者の意図する単語が、話者の意図する単語と異なる単語として誤って認識されるのを抑制するとともに、話者が発する音声に関する情報を登録する際に、音声の認識の状態を話者が確認することが可能な自動翻訳対応電話機を提供する。
【解決手段】この発信元電話機10(自動翻訳対応電話機)は、日本語によって話者が発する音声が入力される集音器12aと、話者が発する音声に関する情報を予め登録して記憶するためのメモリ18と、話者が発する音声に関する情報に基づいて、話者が発する音声を日本語に対応する文字として認識するための音声認識部19と、文字を音声として出力するスピーカ12bと、話者が発する音声に関する情報を登録する際に、話者が発する音声を日本語に対応する文字として認識した結果に基づいて、文字を音声として出力するようにスピーカ12bを制御する制御部13とを備える。
(もっと読む)
機械翻訳装置、機械翻訳方法、およびプログラム
【課題】翻訳規則として記述しにくいまたは記述しきれない文法現象に対する正確な翻訳規則を必要とすることなく、機械翻訳を行う。
【解決手段】翻訳規則として記述しにくいまたは記述しきれない文法現象を持つ語彙を、特定パターンとして予め特定パターンDB103に登録しておき、この特定パターンが第1言語の入力文に含まれていた場合には、当該特定パターンの解析結果と対応する第2言語の語彙または構文情報を翻訳DB108から取得し、この第2言語の語彙または構文情報と第2言語統計的モデル104に格納されている統計的共起情報とを用いて、誤り検出・校正部107により、第1言語を翻訳して得られた第2言語翻訳文の誤りを検出し、当該第2言語翻訳文を校正する。
(もっと読む)
オントロジー生成装置、及び方法
【課題】生成されたオントロジーを構成する概念間の矛盾をユーザが容易に判別することができるオントロジー生成装置、及び方法を提供する。
【解決手段】取得部45が、文書データを取得し、第1抽出部50が、文書データから、概念情報記憶部31に記憶されている概念の組である概念ペアが共起する文の文字列のうち前記概念ペアの概念を表す語彙それぞれを変数に置き換えた第1及び第2文字列と他の文字列との依存関係を示すパターンを抽出して、パターン情報記憶部36に記憶させ、第2抽出部55が、パターン情報記憶部36に記憶されているパターンを用いて、文書データから新たな概念ペアを抽出し、概念情報記憶部31に記憶させ、生成部60が、概念情報記憶部31に記憶されている複数の概念ペアを用いてオントロジーを生成し、判定部65が、オントロジーを構成する概念間の矛盾の有無を判定し、出力部20が、オントロジーとともに判定結果を出力する。
(もっと読む)
翻訳装置、方法、及びプログラム
【課題】入力言語及び出力言語の設定が逆の状態で行われた翻訳の修正負荷を減少させることができる翻訳装置、方法、及びプログラムを提供する。
【解決手段】設定部60が、入力言語及び出力言語を設定し、第1受付部40が、元データの入力を受け付け、記憶制御部42が、元データを記憶部30に記憶させ、検知部45が、元データの言語と入力言語の相違を検知し、切替部55が、相違が検知された場合に、入力言語及び出力言語の設定を切り替え、認識部62が、切り替えが行われなかった場合には、記憶部から読み出した元データを設定された入力言語で認識し、切り替えが行われた場合には、読み出した元データを切り替え後の入力言語で認識し、翻訳部65が、切り替えが行われなかった場合には、認識結果を設定された出力言語に翻訳し、切り替えが行われた場合には、認識結果を切り替え後の出力言語に翻訳し、出力制御部70が翻訳結果を出力部20に出力する。
(もっと読む)
情報解析システム、端末装置、サーバ装置、情報解析方法、及びプログラム
【課題】複数の端末装置によって共通の電子文書に対する解析が別々に行われる場合において、各端末装置で取得される情報の信頼性の向上を図り得る、情報解析システム、情報解析装置、サーバ装置、情報解析方法、及びプログラムを提供する
【解決手段】情報解析システムは、電子文書を解析して異なる複数の解析候補を抽出し、指示に応じて解析候補を選択する端末装置10と、各端末装置10が選択した解析候補を格納するサーバ装置20とを備える。各端末装置10は、共通の電子文書に対して解析を行った場合、これから抽出した複数の解析候補のいずれかと一致する解析候補を、サーバ装置20内の、他の端末装置10が選択した解析候補の中から検索する。また、各端末装置10は、抽出した複数の解析候補のうち、検索によって一致する解析候補が見つかった解析候補の重みを、それ以外の解析候補の重みよりも高い値に設定する。
(もっと読む)
音声翻訳装置、方法、およびプログラム
【課題】発話内容の修正にかかる利用者の負担を軽減させることができる音声翻訳装置、方法、およびプログラムを提供する。
【解決手段】音声入力受付部100は、日本語の発話音声の入力を受け付け、音声認識部120は、発話音声の入力が受け付けられる毎に、当該発話音声を認識して文字列を生成し、蓄積部42は文字列を順次蓄積し、判定部130は、新たに蓄積する候補である第2文字列が先に蓄積された第1文字列の言い直しであるか否かを判定し、修正部140は、言い直しでない場合には、第2文字列を蓄積部42に蓄積させ、言い直しである場合には、第1文字列を第2文字列に修正して蓄積部42に蓄積させ、翻訳部150は、蓄積部42に蓄積される毎に、蓄積されている文字列を英語に翻訳し、出力部30は、翻訳結果を出力する。
(もっと読む)
翻訳プログラム、翻訳システム及び対訳データ生成方法
【課題】処理負荷が小さく、かつ、翻訳精度の高い翻訳システム及び翻訳プログラム、並びに、対訳データ生成方法を提供すること。
【解決手段】翻訳システム1は、第1言語で表現された複数の第1言語単文データと、第2言語で表現された複数の第2言語単文データとを含み、対訳関係を有する前記第1言語単文データと前記第2言語単文データとが関連付けられて記憶された第1の対訳データ記憶部32と、前記第1言語で表現された原文データを受け取り、前記原文データの訳文データを出力する翻訳処理部40とを含む。前記翻訳処理部40は、前記原文データに基づいて前記第1の対訳データ記憶部に記憶されたいずれかの第1言語単文データを翻訳対象として選択する翻訳対象選択処理部44と、翻訳対象として選択された第1言語単文データと対訳関係を有する第2言語単文データを前記第1の対訳データ記憶部から読み出して、読み出した第2言語単文データに基づき前記訳文データを出力する対訳出力処理部48とを含む。
(もっと読む)
文書画像処理装置、及び文書画像処理プログラム
【課題】処理の無駄を省き、さらには翻訳結果の誤りを軽減させる。
【解決手段】文書画像処理装置10は、文書画像に含まれる文字列を認識する文字列認識部16と、文字列認識部16により認識された文字列毎に翻訳処理の対象とするか否かを判断する翻訳対象判断部18と、翻訳対象判断部18により翻訳処理の対象とすると判断された文字列について翻訳処理を行う翻訳処理部20と、を含む。
(もっと読む)
翻訳支援装置、翻訳支援方法および翻訳支援プログラム
【課題】 翻訳対象となる日本語の文法的正確さを、翻訳前に確認する手段を提供する。
【解決手段】 日本語による翻訳対象文を異言語への翻訳に先立ち前編集する翻訳支援装置であって、利用者が入力した翻訳対象文を受け付ける翻訳対象文受付手段と、前記翻訳対象文受付手段が受け付けた前記翻訳対象文を形態素解析する形態素解析手段と、前記形態素解析手段が解析した形態素情報を構文解析し、翻訳対象文における主語候補および述語候補を特定する構文解析手段と、前記構文解析手段が特定した主語候補および述語候補を表示する表示手段とを備える、翻訳支援装置に関する。
(もっと読む)
音声を翻訳する装置、方法およびプログラム
【課題】音声翻訳時の認識精度を向上させる音声翻訳装置を提供する。
【解決手段】原言語の用例と目的言語の用例とを記憶する用例記憶部121と、音声を受付ける音声受付部101と、音声を認識して原言語の発話文字列となりうる複数の候補と尤度とを生成する認識部103と、候補と類似する用例を用例記憶部121から取得する用例取得部104と、用例中で候補との間の差異部分に相当する差異語句と、候補中で用例との差異部分に相当する代替語句とを検出する検出部105と、差異語句の意味属性と同一の意味属性に対応づけられた代替語句を取得する語句取得部106と、尤度が最大の候補の代替語句を、取得された代替語句で置き換えて訂正した候補をさらに生成する生成部107と、訂正された候補に対応する目的言語の用例を用例記憶部121から取得することにより、候補を目的言語に翻訳する翻訳部108と、を備えた。
(もっと読む)
言語処理結果から妥当な候補を選択する装置、方法およびプログラム
【課題】処理結果の候補から適切な処理結果を選択する言語処理装置を提供する。
【解決手段】文の構成単位と生起確率とを記憶する第1記憶部121と、係り先および係り元の構成単位で表される係り受け関係と係り先に対して係り元の構成単位が出現する条件付確率とを記憶する第2記憶部122と、処理結果の候補を受付ける入力受付部101と、処理結果の候補の係り受け構造を解析する解析部103と、係り受け構造の候補それぞれについて、文末の構成単位に対応する生起確率を第1記憶部121から取得し、係り受け関係に対応する条件付確率を第2記憶部122から取得し、すべての条件付確率の積と生起確率との積である係り受け構造の候補の生起確率を算出する算出部103aと、算出した生起確率が最大となる係り受け構造の候補を求め、求めた候補に対応する処理結果の候補を選択する選択部104とを備えた。
(もっと読む)
コミュニケーション支援装置、コミュニケーション支援方法およびコミュニケーション支援プログラム
【課題】発話者間の理解が不一致のまま会話が進められることを回避するコミュニケーション支援装置を提供する。
【解決手段】第1発話から重要語句を抽出する抽出条件と、第1発話から抽出した重要語句を第1発話に対応して発話された第2発話に関連付けて出力する関連付け方法とを対応づけて記憶する重要語句規則記憶部111と、第1発話および第2発話の入力を受付ける入力受付部101と、記憶された抽出条件に基づいて、受付けた第1発話から重要語句を抽出する重要語句抽出部102と、抽出する際に用いた抽出条件に対応づけられた関連付け方法に基づいて、抽出した重要語句を、第2発話に関連付けて出力する重要語句付加部103と、重要語句が関連付けられた第2発話を、第2の言語で翻訳する翻訳部104と、重要語句が関連付けられた第2発話を出力する出力制御部106とを備えた。
(もっと読む)
翻訳装置、方法及びプログラム
【課題】多言語話者間での効率的な対話を可能にする。
【解決手段】第1の言語の例文に含まれている複数の単語及び句のそれぞれを意味的に抽象化した複数のクラス情報の構文木を蓄積する例文蓄積部と、第1の言語の文に含まれている複数の単語及び句のそれぞれを意味的に抽象化して、複数のクラス情報を特定する意味的抽象化部と、例文蓄積部に蓄積された例文の構文木と、特定されたクラス情報の構文木とが類似する場合に、特定されたクラス情報の構文木の抽象化前の複数の単語及び句の出力単位で分割する分割部と、第1の言語の単語及び句の出力単位と意味的に対応する、第2の言語の単語及び句の出力単位を生成する翻訳出力単位生成部と、第1の言語の単語及び句の出力単位と、生成された第2の言語の単語及び句の出力単位とを、対応する意味同士で対応付ける対応付部と、を備える。
(もっと読む)
文法規則特定システム、文法規則特定方法及び文法規則特定プログラム
【課題】文の生成において一般的に用いられる文法規則と例外的に用いられる文法規則とを的確に判別することが可能な文法規則特定システム、文法規則特定方法及び文法規則特定プログラムを提供する。
【解決手段】文法規則特定システム100は、文法規則保持部18に予め保持された文法規則に基づいて、解析対象の文の構文意味解析を行う構文意味解析部16と、構文意味解析部16による解析結果に基づいて、文法規則保持部18に予め保持された文法規則のうち、文の生成において例外的に用いられる文法規則を特定する例外規則特定部22とを有する。
(もっと読む)
1 - 20 / 34
[ Back to top ]