
Fターム[5D015EE04]の内容
Fターム[5D015EE04]の下位に属するFターム
雑音除去 (172)
Fターム[5D015EE04]に分類される特許
1 - 20 / 53
音声強調装置とその方法とプログラム
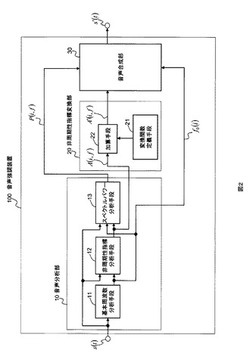
【課題】音量と声質を変化させることなく音声信号の音声の明瞭度を向上させることができる音声強調装置とその方法とプログラムを提供する。
【解決手段】音声分析部は、音声信号を入力として、当該音声信号をpサンプル間隔で分析を行い、上記pサンプルごとの基本周波数f0(i)と、非周期性指標A(i,f)と、スペクトルパワーP(i,f)を出力する。そして、非周期性指標変換部は、所定の周波数範囲の非周期性指標の値A(i,f)を、周波数の増加に対して小さくなる変換後非周期性指標A′(i,f)と当該変換後非周期性指標A′(i,f)の最小の変換後非周期性指標A′(i,f)とに変換して出力する。音声合成部は、基本周波数f0(i)とスペクトルパワーP(i,f)と変換後非周期性指標A′(i,f)とを用いて音声合成音を合成する。
(もっと読む)
音声記録サーバ装置及び音声記録システム

【課題】目的の音声の劣化を抑えつつ不要な音を除去または低減して記録するとともに、ユーザが所望する情報を効率よく提供することを可能とする技術を提供すること。
【解決手段】音声記録サーバ装置(20)は、話者の音声を表す第1音信号を話者の音声以外の音を表す第2音信号に基づいて加工し、第1音信号に含まれる話者の音声以外の音に起因する音信号成分が除去または低減された加工済み音信号を生成する音信号加工部(27)と、加工済み音信号を音声ブロックに分割する分割部(102)と、複数のユーザの各々に対し登録されたキーワードを格納したデータベース(29)から、特定されたユーザに対して登録されたキーワードを取得する取得手段(104)と、取得されたキーワードを含む音声ブロックを抽出する抽出手段(105)と、抽出された音声ブロックを結合して再構成された音信号を生成する結合手段(106)とを有する。
(もっと読む)
直接音抽出装置および残響音抽出装置
【課題】直接音に残響音が含まれた信号から直接音または残響音を抽出する。
【解決手段】直接音抽出装置は、フーリエ変換処理された入力信号に基づいて、第1振幅スペクトル信号Lfaと位相スペクトル信号とに変換するスペクトル変換手段と、第1振幅スペクトル信号Lfaに対して予め設定された正規化カットオフ周波数を用いて周波数毎にローパスフィルタリング処理を行うことにより第2振幅スペクトル信号Lfa1を生成するローパスフィルタ手段4と、第2振幅スペクトル信号Lfa1を第1振幅スペクトル信号Lfaから減算することにより第3振幅スペクトル信号を求める第1減算手段18と、位相スペクトル信号と第3振幅スペクトル信号とに基づいて求められた周波数スペクトル信号から、逆フーリエ変換処理により直接音信号を生成する逆フーリエ変換手段とを備える。
(もっと読む)
音源パラメータ推定装置と音源分離装置とそれらの方法とプログラム
【課題】音源モデルパラメータが予め与えられていなくとも音源パラメータと一緒に音源モデルパラメータも推定できる音源パラメータ推定装置を提供する。
【解決手段】音源モデルパラメータ更新部は、音源パワー特徴量と音源パワーパラメータと音源占有度と、音源モデル記憶部に記憶された音源パワーパラメータの事前確率密度関数と音源パワー特徴量のモデルとを入力として音源モデルパラメータを更新する。音源占有度更新部は、音源位置特徴量と音源パワー特徴量と各音源の更新された音源パワーパラメータと音源位置パラメータと、音源モデルパラメータと、音源モデル記憶部に記憶された音源パワーパラメータの事前確率密度関数と音源パワー特徴量のモデルとを入力として各音源の音源占有度を更新する。
(もっと読む)
音声認識操作装置及び音声認識操作方法
【課題】周囲の雑音に影響されることなくユーザの音声指示を正確に認識することができ、ひいては被制御機器をユーザの所望する通りに正しく制御することを可能とした音声認識操作装置及び音声認識操作方法を提供すること。
【解決手段】実施の形態によれば、音声認識操作装置は、音検出手段とキーワード検出手段と音声ミュート手段と送信手段とを備える。音検出手段は、音を検出する。キーワード検出手段は、音検出手段で音が検出された場合、特定のキーワードを音声認識により検出する。音声ミュート手段は、キーワード検出手段でキーワードが検出された場合、音声ミュートを指示する操作信号を送信する。送信手段は、キーワード検出手段でキーワードが検出された後の音声指示を認識し、当該音声指示に対応する操作信号を送信する。
(もっと読む)
音声処理装置および音声処理プログラム
【課題】定常雑音を含む信号に対する処理において、周波数軸上で処理する技術と比較して処理時間を短縮することを課題とする。
【解決手段】音声処理装置100のゲイン算出部140は、同期減算結果のパワーと、音声入力部110Lにより入力された信号のパワーとを用いて、信号の振幅を抑圧するゲインを算出する。例えば、ゲイン算出部140は、パワー計算部130Lにより計算された信号(inL)のパワー(Power2)から、パワー計算部130Rにより計算された同期減算結果(tmp1)のパワー(Power1)を減算する。そして、ゲイン算出部140は、減算結果(Power21)を信号(inL)のパワー(Power2)で除算した値の平方根を計算することによりゲイン(gain)を算出する。
(もっと読む)
音声認識装置及び音声認識方法
【課題】自己ノイズが発生する環境において高い精度で音声認識を行なう音声認識装置及び音声認識方法を提供する。
【解決手段】本発明による音声認識装置は、音源分離・音声強調部(100)と、自己ノイズ推定部(200)と、該音源分離・音声強調部及び該自己ノイズ推定部の出力を使用して、ミッシングフィーチャーマスクを生成する、ミッシングフィーチャーマスク生成部(300)と、該音源分離・音声強調部の出力を使用して、音源ごとの音の特徴を抽出する音特徴抽出部(401)と、該音特徴抽出部の出力及び該ミッシングフィーチャーマスクを使用して音声認識を行なう音声認識部(501)と、を備えている。
(もっと読む)
音声区間検出方法、音声認識方法、音声区間検出装置、音声認識装置、そのプログラム及び記録媒体
【課題】雑音や対象とする人以外の音声を含むような音信号から、対象とする人の音声区間を正確に検出する音声区間検出方法及び装置を提供することを目的とする。
【解決手段】音信号を所定の長さのフレームごとに取り出し、そのフレームの音信号を解析し、そのフレームの音信号に対象とする話者の音声が含まれるか否かを判定し、判定結果を音声/非音声判定値として求め、音信号の中に含まれる認識単位の系列と、各認識単位の発話時間情報とを求め、音声/非音声判定ステップにおいて得られるフレームごとの音声/非音声判定値と、音声認識ステップにおいて得られる認識単位の系列及び各認識単位の発話時間情報とを受け取って、認識単位の発話時間に対応するフレームの音声/非音声判定値の集計値の大小に基づいて、認識単位ごとに対象とする話者によって発話されたか否かを判定する。
(もっと読む)
音声認識装置
【課題】現在の騒音状況に適した入力ゲインを設定することができる「音声認識装置」を提供する。
【解決手段】第1騒音振幅分布検出部11と第2騒音振幅分布検出部12は、音声認識エンジン7が音声認識処理中に発声音声を検出している時間区間である発声音声区間以外の時間区間において、騒音の振幅分布gb(n)を繰り返し算出する。音声振幅分布検出部14は、発声音声区間の発声音声の平均の振幅分布f(n)を算出する。入力ゲイン制御部10は、音声認識処理開始時に、最後に算出された騒音の振幅分布と、発声音声の平均の振幅分布の双方を考慮し、音声認識エンジン7に入力する入力音声データのレンジが、音声認識エンジン7の規格レンジに対して適正なレンジを持つように入力アンプ5の入力ゲインGを制御する。
(もっと読む)
チャネル統合方法、チャネル統合装置、プログラム
【課題】複数のチャネルから音声認識に適した1のチャネルを選択し、選択されたチャネルの音声認識を行うチャネル統合方法、チャネル統合装置、プログラムを提供する。
【解決手段】チャネルごとに音声信号を入力とし、音声ディジタル信号を出力する音声入力部12と、チャネルごとに音声ディジタル信号を入力とし、パワー値を出力するパワー計算部21と、チャネルごとに音声ディジタル信号、パワー値を入力とし、パワー値が最大となるチャネルの音声ディジタル信号を出力音声ディジタル信号として出力するチャネル選択部22と、出力音声ディジタル信号、音響モデル、言語モデルを入力とし、認識結果テキストを出力する音声認識部23と、出力音声ディジタル信号を入力とし、保存音声信号ファイル情報を出力する音声信号保存部25と、保存音声信号ファイル情報と認識結果テキストとを対応付けて保存する音声/テキスト保存部26とを備える。
(もっと読む)
雑音抑圧装置、雑音抑圧方法及びプログラム
【課題】ハンズフリー通話時において、ユーザの位置や数が逐次変わるような状況においても、高音質で話者の音声を伝送することができる雑音抑圧装置、雑音抑圧方法およびプログラムを提供する。
【解決手段】音声認識処理部11は、マイクロホンアレイ5が収集した周囲の音の音声信号をADC6がデジタル変換し、エコーキャンセラ7がエコーを除去した音声信号を受信する。音声認識処理部11は、受信した音声信号について音声認識を行い、特定の単語を含むか否かを判定する。特定の単語を含む場合、音源方向推定部13は、音声信号に基づいて、音源の方向を推定する。雑音抑圧処理部14は、音源の方向以外の音声を抑圧し、音源の方向の音質を高める。伝送音声選択部12は、音源の方向の音質を高めた音声信号を携帯電話基幹部2に送信する。
(もっと読む)
音声判別装置
【課題】特徴量に含まれる残留エコー成分を抑制する。
【解決手段】音声判別装置100は、第1音響信号の周波数スペクトルを解析する第1音響信号解析部103と、前記第1音響信号のエコー成分を第2音響信号から抑圧した第3音響信号から、前記第1音響信号の周波数スペクトルを除外して、前記第3音響信号の周波数スペクトルの特徴量を抽出する特徴抽出部101と、を備える。
(もっと読む)
音声認識装置及び音声認識方法
【課題】環境の変化に対応することのできる構造を有したソフトマスクを使用した音声認識装置を提供する。
【解決手段】音声認識装置は、複数音源からの混合音を分離する音源分離部(100)と、分離された音声信号の周波数のスペクトル成分ごとに、0から1の間の連続的な値をとりうるソフトマスクを、分離された音声信号の分離信頼度に対する音声信号及びノイズの分布を使用して生成するマスク生成部(400)と、前記音源分離部によって分離された音声を、前記マスク生成部で生成されたソフトマスクを使用して認識する音声認識部(500)と、を備えている。
(もっと読む)
反射音情報推定装置、反射音情報推定方法、プログラム
【課題】収音信号から反射音情報を推定する技術を提供する。
【解決手段】音声信号をM個のマイクロホンで収音して得られるM個の収音信号がそれぞれ周波数領域に変換された信号(観測信号)を用い、空間中の任意の位置と各マイクロホンとの間の周波数ごとの伝達特性を模擬した関数(伝達特性関数)に複素振幅を乗じたものを観測信号から減じて得られる残差信号のパワーが最小になるように伝達特性関数に対応する空間中の位置により決定される方向および複素振幅を推定し、推定された方向を反射音の到来方向とし、推定された複素振幅を反射音の到来振幅とする。
(もっと読む)
通話区間検出装置、その方法、及びプログラム
【課題】複数の通話端末装置間で行われる通話の通話区間を正確に推定する。
【解決手段】音声入力部11に、何れかの上記通話端末装置を基準とした送話側チャネルの音声信号と受話側チャネルの音声信号とが入力され、音声検出部12が、送話側チャネルの音声信号と受話側チャネルの音声信号とを用い、チャネル毎の音声区間と非音声区間とを検出し、通話区間推定部13が、或るチャネルの音声区間の開始時刻を第1起点とし、当該音声区間の開始時刻を除く或る時刻を第2起点とし、当該第2起点から一定時間T1以内に別のチャネルの音声区間が存在しない場合に、上記或るチャネル音声区間の音声は通話の音声ではないと判断し、当該第2起点から一定時間T1以内に別のチャネルの音声区間が存在する場合に、上記第1起点又は上記第1起点の一定時間T4前の時刻を通話区間の開始時刻として推定する。
(もっと読む)
音声認識システム及び音声認識方法
【課題】 音響モデルの学習無しで、環境雑音などの音声以外の雑音を効果的に除去する。
【解決手段】 無音音素を除く単音素により雑音に対する音声認識を行い、ゆう度が上位の単音素を抽出する。抽出した上位の単音素に、言語として意味をなすか否かに係わらず、同一または他の単音素を付加した音素列により、雑音に対する音声認識を行い、再度ゆう度が上位の音素列を抽出し、不要語の辞書に記憶させる。
(もっと読む)
目的音声抽出方法、目的音声抽出装置、及び目的音声抽出プログラム
【課題】互いに到来方向が異なる複数の音声のうち、目的とする他の音声の混入を効率的に抑制して目的音声を抽出する技術を提供する。
【解決手段】所定の距離離して配置された第1および第2の音声入力器からそれぞれ取得した音声信号に、目的音声以外の他の音声の影響を受けやすい周波数帯域に対して小さい値をとる重み付きCSP(Cross−Power Spectrum Phase)係数を用いて、利得調整処理および発話区間の切り出し処理の少なくとも一方を行い目的音声の抽出処理を行う。
(もっと読む)
信号分離装置、信号分離方法
【課題】内部ノイズ源を有する場合でも、計算負荷が少なくかつ正確にユーザー音声を認識できる信号分離システムを提供する。
【解決手段】信号分離システムは、ユーザー音声を集音することを目的とした外部マイクと、システム内部ノイズ源からの内部ノイズだけを検知する内部センサと、を有する。独立成分分析部は、分離フィルタ行列の最適化により、内部ノイズを出力する分離信号とそれを含まない信号群に分離する。パーミュテーション解決部は、内部ノイズを含まない分離信号群に対してパーミュテーション解決を実行する。パーミュテーション解決部では、分離信号をラプラス分布でフィッティングした際のラプラス分布のスケールパラメータの値を求め、そのパラメータの最大値をもつ分離信号をユーザー音声とする。
(もっと読む)
音声抽出装置
【課題】同時通話状態時に外部音声を抽出する。
【解決手段】スピーカからマイクロフォンへの伝達系を模擬したフィルタ係数の設定および更新を行う第1の適応フィルタ111,114および第2の適応フィルタ112,115と、スピーカに入力される入力音声信号を第1および第2の適応フィルタで演算処理し得られた模擬信号とマイク入力音声信号との差分である第1および第2の残差信号を抽出する減算部12および減算部13と、減算部12におけるマイク入力音声信号および第1の残差信号の差分量と減算部13におけるマイク入力音声信号および第2の残差信号の差分量とを監視するキャンセル量比較部16と、差分量の高い側の残差信号を送出する抽出信号送出部とを備えた。
(もっと読む)
コマンド認識装置
【課題】音声を用いたコマンドコントロールシステムにおいて、コマンドと関係のない音声による誤動作を軽減することのできる技術を提供する。
【解決手段】撮影装置1の制御部11は、入力されたコマンド音節に含まれる音素に対応する音素を音素辞書から選択して、音素の列で構成されたコマンド音素列を生成する。また、制御部11は、生成したコマンド音素列と所定の類似度を有するダミーコマンド音素列を、予め定められたアルゴリズムに従って生成する。制御部11は、マイクロホン15によって収音された音声を表す音声信号を解析し、解析結果とコマンド音素列との類似度及び解析結果とダミーコマンド音素列との類似度に応じて、コマンドの認識処理を実行する。
(もっと読む)
1 - 20 / 53
[ Back to top ]