
Fターム[5D015GG01]の内容
Fターム[5D015GG01]に分類される特許
41 - 60 / 134
コンピュータによる複数の方言を背景とする共通語音声認識のモデリング方法及びシステム
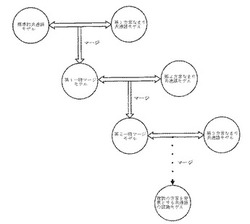
【課題】データ量が少ないまま方言なまりの共通語に対する認識率を高め、同時に標準的共通語に対する認識率が顕著に下がらないことを保証するシステムの提供。
【解決手段】まず標準的共通語のトレーニングデータに基づきトライフォンによる標準的共通語モデルを生成し、第1、第2方言なまり共通語のディベロップメントデータに基づいてモノフォンによる第1、第2方言なまり共通語モデルをそれぞれ生成する。更に、標準的共通語モデルを用いて第1方言なまり共通語のディベロップメントデータを認識することにより得られた第1混同行列に応じ、第1方言なまり共通語モデルを標準的共通語モデルの中にマージして一時マージモデルを得る。最後は、一時マージモデルにより第2方言なまり共通語のディベロップメントデータを認識することにより得られた第2混同行列に応じて、第2方言なまり共通語モデルを一時マージモデルの中にマージして認識モデルを得る。
(もっと読む)
音声認識システム及びナビゲーション装置

【課題】地名の変遷と地図データのバージョンの変遷との対応関係に関わらず、地名の音声認識を適切に行うことができる技術を提供する。
【解決手段】ナビゲーション装置は、ユーザが入力した地名の音声データに対して、ナビ自身が保有する音声認識辞書によって該当の地名を認識できなかった場合、音声データとバージョン情報をサーバへ送信する(S105)。サーバ側では、バージョンの異なる音声認識辞書から該当の地名を認識する(S202)。そして、サーバによる認識結果を、要求元のナビゲーション装置に搭載されている地図データのバージョンに適合する認識結果に変換して(S206)、ナビゲーション装置へ返信する(S209)。ナビゲーション装置側では、その変換された認識結果を用いて、自身が保有する地図データから地名に関するデータを検索する(S106)。
(もっと読む)
発話入力の音声認識のためのコンピュータ・システム、並びにその方法及びコンピュータ・プログラム
【課題】音声認識の認識精度を上げる。
【解決手段】発話入力の音声認識のためのコンピュータ・システムを提供する。該システムは、第1発話の入力に応答して、該入力された第1発話の音声が記憶部に登録された音声と一致するかどうかを判断する第1の判断部と、上記入力された第1発話の音声が上記記憶部に登録された音声と一致しない場合に、第2発話の入力を要求する要求部と、上記入力された第2発話の音声が上記記憶部に登録された音声と一致するかどうかを判断する第2の判断部と、上記第2発話の音声が上記記憶部に登録された音声と一致する場合に、上記第2発話の音素列と上記第1発話の音素列とを比較する比較部と、上記第2発話の音素列が上記第1発話の音素列と似ている場合に、上記第1発話の音声を上記第2発話に対応するコマンド又はアクションに関連付ける関連付け部とを含む。
(もっと読む)
音響処理装置およびプログラム
【課題】字幕と発話内容の一致率が低いオフライン字幕を利用した場合にも、高い認識率によって音響モデルの学習データを自動生成し、多様な発話スタイルに対応できる音響モデルを作成できる音響モデル学習装置を提供する。
【解決手段】一致区間のみを切り出して利用するのではなく、その他の区間から得られる情報も、音響モデル学習のために用いる。そのため、音声認識結果と書き起こし字幕テキストの一致区間を利用して学習データを得る際に、各形態素の信頼度を導入することにより、一致区間以外の音声も利用して学習データを自動生成させる。
(もっと読む)
音声認識モデル作成装置とその方法、音声認識装置とその方法、プログラムとその記録媒体
【課題】適応学習を効率よく行う。
【解決手段】この発明の音声認識モデル作成装置は、初期値音声認識モデル記録部と、モデル更新部と、更新音声認識モデル記録部とを具備する。初期値音声認識モデル記録部は、複数の音声認識モデルを含む初期値音声認識モデルを記録する。モデル更新部は、複数の音声認識モデルの組み合わせから成る状態確率遷移を基に音声認識された単語列を入力として初期値音声認識モデルを1つのベクトルとして更新した更新音声認識モデルを生成する。更新音声認識モデル記録部は、更新音声認識モデルを記録する。
(もっと読む)
音声認識システム
【課題】分野毎に比較的多数の文字情報が予め記憶されていない場合であっても比較的高い精度にて音声認識処理を行うことが可能な音声認識システムを提供すること。
【解決手段】この音声認識システム1は、分野毎に分類されたキーワードを記憶する。また、音声認識システムは、記憶されているキーワードと対応付けられたデータを取得し、当該取得したデータから文字情報を抽出し、当該抽出した文字情報を、当該キーワードが属する分野を識別する分野識別情報と対応付けて記憶する。更に、音声認識システムは、音声を表す音声情報と、分野識別情報と、を受け付けるとともに、当該受け付けた分野識別情報と対応付けて記憶されている文字情報に基づいて当該受け付けた音声情報を、当該音声情報が表す音声を文字列により表した文字情報に変換する音声認識処理を行う。
(もっと読む)
発話容易性判定装置及び発話容易性判定方法
【課題】評価の主体にかかわらず適切な評価結果を得ることができる発話容易性判定手法を提供する。
【解決手段】音声入力機器は、入力された文言の発話フレーズ毎に、発話の容易性を示す生体コストを生体コスト算出部16によって算出し、算出した生体コストに基づく発話の容易性の判定結果を表示部11等の提示手段によって出力する。
(もっと読む)
現場にて音声−音声翻訳をメンテナンスするシステム及び方法
【解決手段】方法及び装置は、第1言語を書き言葉及び話し言葉を含む第2言語に翻訳する音声翻訳システムの語彙を更新する。この方法は、第1言語における新語を第1言語の第1認識辞書に加えるステップと、発音及び語クラス情報を含む説明を新語と関連付けるステップとを含む。次に、これらの新語及び説明は、第1言語と関連付けられた第1機械翻訳モジュールにおいて更新される。この第1機械翻訳モジュールは、第1タグ付けモジュール、第1翻訳モデル及び第1言語モジュールを含み、新語を第2言語において対応する翻訳語に翻訳するように構成される。選択的に、本発明は、双方向の又は多方向の翻訳に利用されてもよい。 (もっと読む)
音響モデル学習装置およびプログラム
【課題】字幕と発話内容の一致率が低いオフライン字幕を利用した場合にも、高い認識率によって音響モデルの学習データを自動生成し、多様な発話スタイルに対応できる音響モデルを作成できる音響モデル学習装置を提供する。
【解決手段】音響モデル学習装置が、音素と該音素に対応する音響特徴量とを関連付けた音響モデルを記憶する音響モデル記憶部と、音響モデル記憶部から読み出した音響モデルを用いて音声の認識処理を行い、認識結果データを出力する認識処理部と、音声に対応するテキストデータと認識処理部が出力した認識結果データとに基づき、これら両データの一致区間を選択し、選択した前記一致区間に含まれる音素と当該音素に対応する音響特徴量との組を学習データとして出力する選択処理部と、選択処理部が出力した学習データを用いて、前記の音響モデルを更新する音響モデル適応化部を備える。
(もっと読む)
データ処理装置、データ処理装置制御プログラム、データ処理方法及び特定パターンモデル提供システム
【課題】話者の種類、発話語彙、発話様式、発話環境等の特定条件により多様化する特徴パラメータの分布を考慮して不特定話者用の音響モデルを生成するのに好適で、且つ、特定の個人の音声に最も適合した不特定話者用の音響モデルを提供するのに好適なデータ処理装置及びデータ処理装置制御プログラムを提供する。
【解決手段】データ処理装置1を、データ分類部1aと、データ記憶部1bと、パターンモデル生成部1cと、データ制御部1dと、数学的距離算出部1eと、パターンモデル変換部1fと、パターンモデル表示部1gと、領域区分部1hと、区分内容変更部1iと、領域選択部1jと、特定パターンモデル生成部1kと、を含んだ構成とした。
(もっと読む)
データ処理装置、データ処理装置制御プログラム及びデータ処理方法
【課題】話者の種類、発話語彙、発話様式、発話環境等の特定条件により多様化する特徴パラメータの分布を考慮して不特定話者用の音響モデルを生成するのに好適で、且つ、特定の個人の音声に最も適合した不特定話者用の音響モデルを提供するのに好適なデータ処理装置及びデータ処理装置制御プログラムを提供する。
【解決手段】データ処理装置1を、データ分類部1aと、データ記憶部1bと、パターンモデル生成部1cと、データ制御部1dと、数学的距離算出部1eと、パターンモデル変換部1fと、パターンモデル表示部1gと、領域区分部1hと、区分内容変更部1iと、領域選択部1jと、特定パターンモデル生成部1kと、を含んだ構成とした。
(もっと読む)
音声認識辞書の更新データ作成方法
【課題】少ない更新データ量で簡易に音声認識辞書を更新できる「音声認識辞書の更新データ作成方法」を提供する。
【解決手段】前回{(n-1)回目}の更新データ作成時に用いた音声認識元データ(n-1)と、今回{第n回目}の更新データ作成に用いる音声認識元データ(n)とから、ヨミ辞書(n)とキーデータ(n)とを作成して、更新データ(n)とし、ナビゲーションシステムに、適当な通信媒体または記憶媒体を介して提供する。キーデータ(n)には、音声認識元データ(n)で追加された地点について地点毎に当該地点の地点情報を登録し、ヨミ辞書(n)には、全地点について地点毎に当該地点の名称のヨミと、当該地点の地点情報を登録した今回または過去の回において作成したキーデータのエントリを指し示すキーポインタを登録する。
(もっと読む)
入力支援システム
【課題】一般的に、ユーザから発せられた音声を認識し、文字列へ変換を行う際には、変換後の文字列をユーザに示し、誤りがある場合には訂正させることで誤変換を防いでいる。しかしながら、この手法は逐一ユーザの入力が必要となり、正しく音声を認識するまでに非常に時間がかかってしまうという問題があった。
【解決手段】本発明は、確定文字列に連携して取得できる連携文字列候補と、文字認識用信号から生成できる認識文字列候補とを比較し、一致(あるいは近似)した文字列を確定文字列とする入力支援システムである。さらに、生成した認識文字列候補と比較する対象である連携文字列候補は、既に選択された確定文字列に後置きされている後置連携文字列候補又は/及び、前置きされている前置連携文字列候補とすることができる。
(もっと読む)
情報処理方法及び情報処理装置
【課題】 音声登録型音声認識において、音声登録時に音声を2回以上発声させる負担を負わせることなく、実行時の音声認識の精度を、登録時に2回以上発声した場合の精度に近づける。
【解決手段】 ユーザが発声した登録対象の音声を取得し、取得した登録対象の音声に対応する音声情報をメモリに登録し、別途ユーザが発声した認識対象の音声を、メモリに登録されている音声情報を用いて音声認識して1つ又は複数の認識結果を出力し、出力された1つ又は複数の認識結果の中から、ユーザが意図した認識結果を特定するとともに、特定された認識結果に対応する登録音声情報として、認識対象として発声された音声に対応する音声情報を登録する。
(もっと読む)
話者特定装置及び音声認識装置並びに話者特定用プログラム及び音声認識用プログラム
【課題】話者特定処理に必要な計算量や記憶容量等を最小限に抑制しつつ、且つ、話者特徴情報の更新の進行態様に柔軟に対応させて適切に類似度閾値を更新させることで、話者特定における正確性をより向上させることが可能な話者特定装置を提供する。
【解決手段】話者による発話の音響的特徴を示す話者モデルと、当該話者の発話に相当する特徴量信号Soと、を比較し、それらの間の類似度を検出すると共に、検出された類似度と、当該類似度の検出の際に比較された類似度閾値と、を比較して話者特定を行う話者認識部5と、特徴量信号Soを用いて話者モデルを更新するパラメータ更新部8と、類似度閾値を、検出された類似度を用いて更新する閾値設定部6と、を備える。
(もっと読む)
録画装置
【課題】記録される映像データが過度になることなく連絡先情報が表示された映像データを確実に録画できる録画装置を提供するを提供する。
【解決手段】HDDレコーダ200は、チューナ11と、エンコーダ部22と、周波数解析部30と、音声認識部31と、データプロセッサ23と、ディスクドライブ部24と、デコーダ部25と、リモコン信号受信部26と、制御部27と、等を備えて構成されており、放送番組データを構成する音声信号の周波数を検出して「ホームページ」というキーワード(特定語句)を検出することにより、キーワード検出後の所定時間(例えば、検出後30秒間)のみの録画を実現する。
(もっと読む)
話者特定装置及び音声認識装置並びに話者特定用プログラム及び音声認識用プログラム
【課題】話者特定処理に必要な計算量や記憶容量等を最小限に抑制しつつ、長期間に渡って認識率が低下し難い話者特定装置を提供する。
【解決手段】話者による発話の音響的特徴を示す話者モデルと、話者の発話に相当する特徴量信号と、を比較し、当該話者を特定する音声認識装置において、同一の話者について、本来の話者特定に用いられる登録話者モデルRMの他に、当該話者に対応し且つ当該話者の認識率が当該登録話者モデルRMよりも高い予備話者モデルRSVを予め記憶し(ステップS11)、当該登録話者モデルRMにおける認識率が低くなったとき当該登録話者モデルRMを予備話者モデルRSVに入れ換えて以降の話者特定を行う(ステップS15)。
(もっと読む)
議事録作成方法、その装置及びそのプログラム
【課題】音声をテキスト化するために必要となる言語モデル及び音響モデルを各議題毎、各参加者毎に最適にする。
【解決手段】入力した音声をその言語のテキストデータとする音声認識手段と、前記テキストデータを基に、議事録を作成する議事録作成する手段と、を備える議事録作成装置であって、入力される言語の方言と議題、レジュメ又は参考資料とを基に、それぞれ、それらに適した音響モデル及び言語モデルとを選択するモデル選択手段を更に備え、前記音声認識手段は、前記モデル選択手段により選択された前記音響モデル及び前記言語モデルを利用する。
(もっと読む)
音声認識辞書構築装置及びプログラム
【課題】使用環境に適した音声認識辞書を構築する。
【解決手段】複写機100において、スキャナ部70により原稿を読み取って得られた画像データに基づいて、原稿内に含まれる単語の文字認識を行い、当該文字認識された結果に基づいて音声認識辞書41を更新する。この際、単語が文字認識された回数が多いほど、文字認識された単語の音声認識における優先度を高くする。また、原稿を読み取る際の重み付け値が大きいほど、原稿内に含まれる単語の音声認識における優先度を高くする。
(もっと読む)
音響モデルパラメータ更新処理方法、音響モデルパラメータ更新処理装置、プログラム、記録媒体
【課題】入力音声から抽出した特徴パラメータの特徴量の変換に伴う、言語重み、単語挿入ペナルティー、ビーム幅等の認識パラメータの最適化のための計算量を軽減する。
【解決手段】入力音声信号の特徴パラメータを抽出し、抽出した特徴パラメータを特徴量変換処理し、特徴量変換処理した変換特徴パラメータを音響モデルパラメータ、言語モデルパラメータ、認識パラメータと照合し、照合尤度が最も大きいモデルが表現する音声単位を認識結果として出力する音声認識に用いる音響モデルパラメータを、適応すべき入力音声の特徴パラメータに適応化処理する音響モデルパラメータ更新処理方法において、特徴パラメータの特徴量変換処理後に、特徴量の各次元にパラメータレンジ変換係数kを乗算し、特徴量変換前後での音響スコアのレンジ変動を抑える。
(もっと読む)
41 - 60 / 134
[ Back to top ]