
Fターム[5D015LL05]の内容
Fターム[5D015LL05]の下位に属するFターム
合成音声による出力 (71)
Fターム[5D015LL05]に分類される特許
1 - 20 / 200
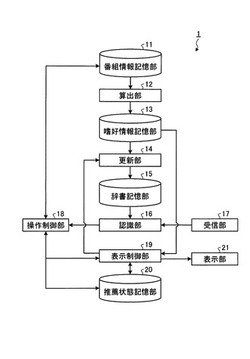
音声認識装置、音声認識方法およびプログラム
【課題】音声認識の精度を向上させる。
【解決手段】音声認識装置は、番組情報記憶部と、辞書記憶部と、算出部と、更新部と、認識部と、操作制御部とを備える。番組情報記憶部は、放送番組のメタデータとユーザの視聴状態とを記憶する。辞書記憶部は、音声認識の対象となる認識語と優先度とを含む認識辞書を記憶する。算出部は、メタデータと視聴状態とに基づいて、放送番組の特徴語と特徴語に対するユーザの嗜好の度合いを表す第1スコアとを算出する。更新部は、特徴語を含む認識語の優先度を第1スコアに応じて更新する。認識部は、認識辞書を用いて音声を認識する。操作制御部は、認識結果に基づいて放送番組に対する操作を制御する。
(もっと読む)
音声入力ワープロにおける連想候補選択方式
【課題】音声入力ワープロにおいて、音声認識エンジンが音声認識困難な単語、文章の入力を可能とする。
また、音声のみによる音声ワープロを可能にする。
【解決手段】(1)あらかじめ、音声認識が容易な単語、文章と音声認識困難な単語、文章は、対で登録しておく。
(2)音声入力者は、音声認識困難な単語、文章のかわりに、よく使用される音声認識が容易な単語、文章を連想文言として発声する。
(3)音声認識エンジンは、音声認識が容易な単語、文章のため、認識結果群を返却し、それらが音声認識が容易な単語、文章と一致する確率が高くなる。
(4)ひとつでも一致した場合、音声認識困難な単語、文章を表示させ、選択候補とする。これにより、音声認識エンジンでは、認識困難な語彙の入力が可能になる。
(5)選択候補のキー(番号など)を音声により、発声し、その認識結果が選択候補のキーと一致した場合、選択確定とする。
これにより、音声の発声のみによる音声ワープロが可能となる。
(もっと読む)
音声認識装置

【課題】 リストの手動操作と音声操作とを融合し、ユーザにとって利便性の高い音声認識装置を提供する。
【解決手段】 入力される音声の信号レベルに基づき音声区間であることを判断し(S120〜S140)、当該音声区間に対応する音声データが記憶して(S150)音声を認識する(S170)。そして、認識結果と共に当該認識結果に対応するリスト表示を行う(S180)。このとき、確定操作が行われないうちは(S190:NO)、音声の抽出を繰り返すようにすると共に、リスト表示される対応項目の手動操作を可能にする(S110)。
(もっと読む)
音声認識装置、自動応答方法及び、自動応答プログラム
【課題】音声認識での応答を行う際に、正解の厳密度を調整することが可能な音声認識装置、自動応答方法及び、自動応答プログラムを提供する。
【解決手段】ユーザから音声入力された音声データをテキスト化する音声端末10であって、ユーザの応答を正解とするか否かの判断基準となる厳密度と、ユーザの応答である応答データに対して、厳密度毎に異なる一以上の回答データを、当該厳密度に対応付けて記憶しておく。そして、質問を出力し、ユーザからの音声による応答データを受付け、応答データと予め記憶された回答データとをテキスト文字で比較し、応答データが正解か否かを判断して結果データを出力する際に、厳密度に基づいて結果データを出力する。
(もっと読む)
ナビゲーション装置、ナビゲーション装置を用いた音声認識方法、および、プログラム
【課題】入力した音声のうちの一部分が誤認識された場合に、音声の再入力にかかるユーザの手間を軽減する技術を提供する。
【解決手段】ナビゲーション装置100は、複数の選択ボタンを備え、複数の構成要素に分割可能であって階層構造を有する言語系列を格納する記憶部と、音声を入力する音声入力部と、記憶部に格納されている言語系列の中から、音声入力部から入力された音声に対応する言語系列の候補を特定する音声認識部と、音声認識部によって特定された言語系列の候補を、選択ボタン数の構成要素に分割して表示する表示部と、を備える。音声認識部は、表示された言語系列に含まれる1つの構成要素が選択ボタンを用いて選択されると、選択された構成要素と、当該構成要素より下位の構成要素と、について変更した言語系列の候補を再度特定する。
(もっと読む)
音声認識装置、音声認識方法及びプログラム
【課題】設定された音声認識率と実際の音声認識率との間で大きな誤差が生じないようにする。
【解決手段】音声認識装置10は、複数の単語それぞれの特徴量を記録した記憶部12と、外部から入力された音声の特徴量と記憶部12に記録された複数の単語の特徴量とから各単語の類似度を算出し、算出した各単語の類似度から類似度の最大値を取得する類似度最大値取得部11bと、類似度最大値取得部11bが取得した類似度の最大値と所定値とを用いて類似度の範囲を決定する類似度範囲決定部11cと、類似度範囲決定部11cが決定した類似度の範囲に含まれる類似度を有する単語を選択し、選択した単語を認識結果として表示部15に表示する制御を行う表示制御部11dとを備える。
(もっと読む)
音声認識装置、音声認識方法及び音声認識プログラム
【課題】音声認識結果における認識の誤りがある区間の認識及び修正を容易にする。
【解決手段】音声認識装置1は、音声認識処理結果における区間ごとに保留指定の入力を受け付ける指定受付部16と、保留指定された保留区間をその他の区間と識別可能に表示する保留区間表示部18とを有するので、音声認識処理結果において修正を要する区間の認識が容易となる。そして、音声認識装置1は、保留区間の語句を編集可能に制御する編集制御部19と、当該保留区間に対する文字列の入力を受け付ける修正入力受付部20とを更に備えるので、保留区間の語句の修正が実施される。従って、保留区間の修正が容易となる。
(もっと読む)
テキスト表示時間決定装置、テキスト表示システム、方法およびプログラム
【課題】入力される音声を逐次テキスト化して表示する際、利用者にとって読みやすく理解しやすい字幕を生成できるテキスト表示時間決定装置、テキスト表示システム、テキスト表示時間決定方法、およびテキスト表示時間決定プログラムを提供する。
【解決手段】テキスト表示装置は、認識結果作成手段81と、表示時間決定手段82とを備えている。認識結果作成手段81は、入力される音声を逐次認識してテキスト化した認識結果を作成する。表示時間決定手段82は、音声の発話時間に基づいて、認識結果に含まれる文章ごとに表示時間を決定する。
(もっと読む)
音声をテキストに変換する装置及び方法
【課題】音声をテキストに変換する装置及び方法を提供することを目的とする。
【解決手段】音声受信モジュール、音声識別モジュール、表示モジュール、格納モジュール、話者識別モジュール及び制御モジュールを備え、格納モジュールは異なる音声データに対応するテキストデータ及び異なる音声信号に対応する話者データを格納し、音声受信モジュールは、外部の音声信号を受け取り、音声識別モジュールは、前記音声信号を音声データに変換してから、格納モジュールから前記音声データに対応するテキストデータを探して制御モジュールに送信し、話者識別モジュールは、格納モジュールから前記音声信号に対応する話者データを探して制御モジュールに送信し、制御モジュールは、前記テキストデータ及び前記話者データを表示モジュールに表示させる。
(もっと読む)
ローカルなインターラプト検出に基づく音声認識技術
【課題】音声認識システムを提供すること。
【解決手段】無線通信システム(100)の中で、加入者ユニットのユーザーと他の者との間の音声通話中の加入者ユニットの中のインターラプト表示の検出が、提供される。前記のインターラプト表示に応答して、音声認識エレメントが、動作させられて、音声をベースとするコマンドの処理を開始する。前記の音声認識エレメントを、クライアント−サーバ音声認識構成(115)の中のようなインフラの少なくとも一部の中で実行することができる。前記のインターラプト表示を、加入者の装置の一部を形成するデバイスを使用するか、あるいは加入者の装置(140)の中の音声認識装置を経由して、提供することができる。前記の加入者の装置の所でインターラプト表示を検出することで、この発明で、無線通信環境の中の電子アシスタントと同様のサービスを利用することが容易にできる。
(もっと読む)
音声認識装置
【課題】音声認識用のデータベースに登録されていない施設の名称等をユーザーが繰り返し発声したような場合に、誤認識が続くことを防止する。
【解決手段】音声認識手段による音声認識結果が連続して誤認識であるとユーザーに指摘されたときに、今回入力された音声データと前回入力された音声データとを比較する比較手段を備え、比較手段により今回入力された音声データと前回入力された音声データとがほぼ一致したと判断されたときに、ユーザーが入力したい施設の名称の別の呼び方を話すようにユーザーに促す旨のガイダンスを出力するガイダンス出力手段を備えた。
(もっと読む)
音声認識支援システム、音声認識支援装置、利用者端末、方法およびプログラム
【課題】利用者が外出先等で音声を入力して音声認識を行う場合においてその場所で入力された音声の音声認識結果の誤りを低減させる。
【解決手段】音声認識支援システムは、場所を示す場所情報と、該場所についての音声認識結果の精度を示す情報とを対応づけて出力する場所認識結果精度情報出力手段501と、前記場所認識結果精度情報出力手段によって出力された場所情報と音声認識結果の精度を示す情報とに基づいて、認識対象の音声を入力する場所として指定された場所が音声認識に適しているか否かの情報を出力する音声認識場所適否情報出力手段502とを備えている。
(もっと読む)
電子機器及び制御方法
【課題】音声認識時に、機能制限に伴う実行エラーの原因をユーザに容易に認知させられる電子機器及び制御方法を提供する。
【解決手段】携帯電話機1は、複数の機能の内、いずれかの機能の実行を制限する制限状態とする制御部30と、音声認識の結果に応じて、複数の機能の内、実行されるべき機能を特定する音声認識部60と、制限状態において、特定された機能が所定の機能の実行が制限される制限状態であるか否かを判定する判定部70と、を備え、制御部30は、制限状態において、特定された機能の実行が制限されていない場合には特定された機能を実行し、特定された機能の実行が制限されている場合には特定された機能を実行させず、特定された機能及び特定された機能の実行が制限されていることを報知する。
(もっと読む)
車両用情報機器
【課題】簡単な構成で利便性をより高めることのできる操作装置を提供する。
【解決手段】音声認識部11で認識された音声情報が発話情報と一致するかどうかを判定する発話情報判定部16と、発話情報と一致すると判定された情報を使用情報として決定する使用情報決定部14とを設け、入力された音声情報の少なくとも一部が発話情報と一致しない判定された場合は、この発話情報と一致しない判定された情報の入力源を直接入力部に切り替え、直接入力部により入力された情報と発話情報と一致すると判定された情報とで構成された情報を、制御に用いる使用情報として決定する。
(もっと読む)
会議支援装置、方法およびプログラム
【課題】ユーザの利用状況および学習状況に合わせた強調表示を行うことができる。
【解決手段】会議支援装置は、発音認識情報記憶部、単語強調判定部、表示内容生成部を含む。発音認識情報記憶部は、単語ごとに、単語と、発音情報と、発音認識頻度とを対応付けて記憶情報として記憶する。単語強調判定部は、第1単語と発音情報との第1セットと一致する第2単語と発音情報との第2セットが含まれるかどうかと、第2セットが含まれる場合の第2単語の発音認識頻度とに基づいて、第1単語を強調表示するかどうかの情報を示し、第1単語を強調表示する場合は第2単語の発音認識頻度に応じて決定される強調表示の度合いを示す強調レベルを含む強調判定情報を生成する。表示内容生成部は、強調判定情報に基づいて、第1単語を強調表示する場合は、強調レベルが高いほどより強く強調表示することを示す記号を第1単語に結合した強調文字列を生成する。
(もっと読む)
端末装置、音声認識方法および音声認識プログラム
【課題】ユーザの操作負担を軽減する。
【解決手段】本発明に係る端末装置1は、音声の入力を受け付ける音声入力部10と、音声入力部10により入力された音声に対する音声認識結果を取得する音声認識結果取得部11と、音声認識結果取得部11により取得された音声認識結果の所定の情報に基づいて、音声認識結果に対応する仮名を追加するか否かを判定する仮名追加判定部12と、仮名追加判定部12の判定結果に基づいて、音声認識結果取得部11により取得された音声認識結果に仮名を追加して表示用文字列データを生成する認識結果変換部13と、認識結果変換部13により生成された表示用文字列データを表示する表示部14と、を備えることを特徴とする。
(もっと読む)
再生装置及び方法、並びにプログラム
【課題】オリジナルの画像データを再生している最中に、オリジナルの画像の構図及び構成を維持したまま、音声データに含まれる音声内容を反映した画像も表示させる処理を容易かつ手軽に実現する。
【解決手段】音声出力部19は、音声データを再生することによって、当該音声データにより表される音声を出力する。音声内容認識部52は、音声出力部19の再生対象の音声データを解析することによって、当該音声データに含まれる音声内容を認識する。表示部18は、画像データを再生することによって、当該画像データにより表される画像を、オリジナルの画像として表示する。音声内容反映部54は、表示部18により画像データが再生されている最中に、オリジナルの画像の構成及び構図を維持したまま、音声内容認識部52により認識された音声内容を反映させた画像を表示する処理を、音声内容反映処理として実行する。
(もっと読む)
音声検索インタフェース装置及び音声入力検索方法
【課題】ユーザが音声認識を利用してデータベースから特定の情報を絞り込む際に、効率的に検索結果を絞り込むことのできる音声検索インタフェース装置を得る。
【解決手段】検索手段105は、音声認識結果の単語または単語列に対して検索用データベース104を検索してその検索結果と検索候補数を出力する。修正候補生成手段111は、修正対象単語選択手段109で修正対象単語が選択された場合、その修正対象単語と、読み・音節記憶手段110の単語とのマッチングを行い、単語単位の修正候補を生成し、かつ、修正候補に対する検索候補数を取得する。修正候補表示手段112は、修正候補生成手段111で得られた修正候補と検索候補数とを表示する。
(もっと読む)
音声入力インタフェース装置及び音声入力方法
【課題】ユーザが音声認識における誤認識結果を修正する際、ユーザによる明示的な区間の修正を行うことなく、正しい修正候補を提示することのできる音声入力インタフェース装置を得る。
【解決手段】音声認識手段103は、音声入力に対する認識結果の単語列を出力する。連結修正候補生成手段109は、音声認識手段103から出力された全ての単語を連結した語句と、複数の単語を連結した語句の情報が登録された連結読み・音節記憶手段108の語句とのマッチングを行い、語句単位の修正候補を生成する。差分抽出手段110は、マッチング結果の差分を抽出する。修正候補表示手段111は、差分抽出手段110で抽出された差分を修正候補として表示する。
(もっと読む)
音声記録装置、そのデータ処理方法、およびプログラム
【課題】音声信号を入力し、その内容情報を取得する際に、あらかじめ記録する文を作成するという使用者にかかる負担が大きいこと、を解決することが可能な音声記録装置、そのデータ処理方法、およびプログラムを提供する。
【解決手段】音声記録装置100は、音声信号を記憶する音声記憶部104と、編集指示に従って、音声記憶部104に記憶された音声信号を編集する音声編集部110と、音声編集部110により編集された音声信号を音声認識し、当該音声信号が表す語句を示す認識結果情報を出力する音声認識部112と、を備える。
(もっと読む)
1 - 20 / 200
[ Back to top ]