
Fターム[5D015LL10]の内容
Fターム[5D015LL10]に分類される特許
1 - 20 / 73
情報処理装置、情報処理方法及びプログラム
【課題】音声入力モードになったことをユーザに確実に報知する。
【解決手段】状態検出部と、タッチセンサと、マイクロフォンと、制御部とを有する情報処理装置が提供される。上記状態検出部は、当該情報処理装置の第1の状態変化を検出可能である。上記タッチセンサは、ユーザのタッチを検出可能である。上記マイクロフォンは、入力された上記ユーザの音声を音声信号に変換可能である。上記制御部は、上記音声信号を文字情報として認識する音声入力モードを実行可能である。また制御部は、上記第1の状態変化が検出された場合に、上記音声入力モードが準備状態であることを示す第1の画像を出力するための第1のコマンドを生成可能である。さらに制御部は、上記第1の状態変化に続いて上記タッチが検出された場合に、上記音声入力モードが実行可能な状態であることを示す第2の画像の出力するための第2のコマンドを生成可能である。
(もっと読む)
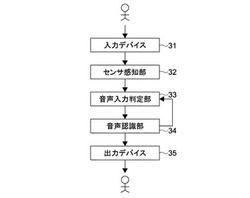
音声認識装置及び音声認識方法

【課題】本装置を含む機器本体の動き又は状態の少なくとも一方を検出して、容易にかつ確実に動作モード切替えを行える音声認識装置を提供する。
【解決手段】実施形態によれば、音声入力部11と、加速度センサを備え、機器本体の動き又は状態もしくはその両方を検出する状態検出部12と、予め定めた機器本体の動き又は状態の動き・状態パターンモデルとそのモデルに対応する予め定めた複数の音声認識処理パターンとを記憶する保持部13と、状態検出部からの機器本体の動きまたは状態もしくはその両方と、保持部13に記憶された動き・状態パターンモデルとがマッチングするか否かを検出し、そのマッチングしたモデルに対応した音声認識処理パターンを検出するパターン検出部14と、検出された音声認識処理パターンに従い、音声入力部からのデジタル信号に対して音声認識処理を実行する音声認識処理実行部15と、を具備する。
(もっと読む)
音声認識装置、端末装置、音声認識システム、音声認識方法、入力方法及びプログラム
【課題】音声認識技術を利用してウェブページの入力フォームへの入力を支援する技術において、音声認識の精度を高める。
【解決手段】文字列とその読みがなとその属性情報とを対応付けた音声認識辞書を保持する辞書保持部11と、入力フォームに入力される情報の範囲を属性情報を用いて規定する複数の入力ルール各々を、ルール識別情報と対応付けて保持するルール保持部12と、複数の端末装置30各々から、ルール識別情報と音声データとを対応付けて受信する受信部13と、ルール識別情報をキーとしてルール保持部12を検索し、入力ルールを取得するルール取得部15と、取得した入力ルールに含まれる属性情報をキーとして音声認識辞書を検索し、読みがなを抽出する検索部16と、検索部16が抽出した読みがな、ルール取得部15が取得した入力ルールを利用して、音声データを文字列データに変換する変換部14とを有する音声認識装置10。
(もっと読む)
電子機器及び制御方法
【課題】複数の動作モードのいずれかに設定可能な場合に、各動作モードにおいて音声認識による操作性を向上させる電子機器及び制御方法を提供する。
【解決手段】携帯電話機1は、通常モードで起動可能な複数の機能と音声認識時に参照される当該機能の読み仮名とがそれぞれ対応付けられた通常辞書データ71、及びかんたんモードで起動可能な複数の機能と音声認識時に参照される当該機能の読み仮名とがそれぞれ対応付けられたかんたん辞書データ72を記憶する記憶部70と、音声認識機能起動時において、通常モード又はかんたんモードの内のいずれに設定されているかを判定するモード判定部50と、通常モードに設定されていると判定された場合には通常辞書データ71を参照して音声認識を行い、一方でかんたんモードに設定されていると判定された場合にはかんたん辞書データ72を参照して音声認識を行う音声認識部60と、を備える。
(もっと読む)
車両用入力装置、車両用入力方法、及び車両用入力プログラム
【課題】走行中における入力時の操作性を向上させることができる、車両用入力装置、車両用入力方法、及び車両用入力プログラムを提供すること。
【解決手段】車両用入力装置1は、利用者から手動入力を受け付ける手動入力部61と、利用者の音声を認識して音声入力を受け付ける音声入力部62と、利用者を特定する利用者特定部63と、手動入力の受け付けを制限する制限条件が満たされている場合、手動入力部61による手動入力の受け付けを制限する入力制御部64とを備え、入力制御部64は、利用者特定部63により特定された利用者が車両の運転者ではない場合には、制限条件が満たされている場合であっても、音声入力部62による音声入力の受け付けに加え手動入力部61による手動入力の受け付けも可能とする。
(もっと読む)
音声認識装置と認識方法
【構成】
複数個の無指向性信号を増幅器で増幅し、無指向性信号を駆動回路で組み合わせて、音源の方向への指向性の有る指向性信号を求め、前記指向性信号あるいは前記無指向性信号に対して発話の有無を検出し、指向性信号を音声認識部で音声認識する。モード切替部により、無指向性信号中あるいは指向性信号中のノイズレベルを繰り返し測定し、ノイズレベルが低い際に、無指向性信号を音声認識部で音声認識するようにモードを切り替える。
【効果】 ノイズが少ない際に、音声認識部への入力信号の質を向上できる。
(もっと読む)
ナビゲーション装置
【課題】ナビゲーション情報の表示に用いられている言語での音声認識が可能でないことを容易に判断することができる「ナビゲーション装置」を提供することである。
【解決手段】予め定められた複数の言語のいずれかにてナビゲーション情報を表示部に表示可能で、前記複数の言語に含まれる一または複数の言語については、前記ナビゲーション情報の表示とともに、音声認識が可能となるナビゲーション装置であって、前記表示部に表示されるナビゲーション情報の言語の音声が認識可能か否かを判定する判定手段(S16)と、前記判定手段によって、前記表示部に表示されるナビゲーション情報の言語の音声が認識可能ではないと判定されたときに、所定の情報を出力する報知手段(S18)とを有する構成となる。
(もっと読む)
音声認識装置、音声認識方法および、そのプログラム並びに記録媒体
【課題】特定話者と不特定話者が混在した音声を発話単位ごとに精度よくテキストに変換する音声認識装置を提供する。
【解決手段】音声認識を行なう分野に応じた不特定話者用専門用語辞書230、231、232を設定し、音声200が入力されると発話単位ごとに、音声200の特徴を抽出し、予め登録した話者モデル210、211、212と照合し話者を推定する。その推定結果に応じて、話者ごとの特定話者用辞書220、221、222、話者が特定できない場合の話者不明用辞書223の中から辞書を選択する。入力された音声200が不特定話者用専門用語辞書230、231、232に登録された音声であれば、音声認識を行なう辞書を不特定話者用専門用語辞書230、231、232に切り替える。設定された辞書により音声認識処理を行いテキスト204に変換する。
(もっと読む)
音声認識システムの動作方法
【課題】音声認識システムの動作方法の改良であり、受信品質が劣化してもできるだけ高い品質で動作しユーザに最大限の快適性を提供する。
【解決手段】音声認識システムは、受信品質を表す受信品質値(SQ)またはノイズ値を決定する。前記受信品質値(SQ)が所与の受信品質閾値より下がったとき、または前記ノイズ値がノイズ閾値より上がったとき、前記音声認識システムはノイズに敏感ではない動作モードに切り替わり、および/またはユーザにアラート信号(SW)を出力する。
(もっと読む)
音声認識システム
【課題】極力、認識語彙に含まれる不要語の数が少ない辞書を用いて音声認識を行なうことにより、音声認識性能の低下を抑制すること。
【解決手段】音声データに基づいて話者を識別し、その話者の発話音声における不要語の使用頻度を算出して、話者毎に不要語使用頻度として記憶しておく。この不要語使用頻度は、話者毎に、どの程度頻繁に不要語を使用するかの傾向を表すものとなる。従って、音声データに基づいて話者が識別されたとき、その話者に対して不要語使用頻度が記憶されている場合、音声認識部31において使用される不要語辞書313bを、記憶されている不要語使用頻度に応じた不要語の数の不要語辞書313bに切り替える。この結果、話者の不要語使用頻度に適した不要語の数の不要語辞書313bを用いて、音声認識を行なうことができる。
(もっと読む)
音声認識装置、音声認識方法、音声認識プログラムおよびプログラム記録媒体
【課題】音声認識結果の誤りの原因が認識モードの誤りの可能性があることにユーザが気付く契機を与える音声認識装置を提供する。
【解決手段】あらかじめ備えている複数の認識モードの中から、入力音声に対する音声認識を行うための少なくとも1つ以上の認識モードを選択して、第1の認識モードとしてユーザが入力手段20から指定すると、認識モード設定手段11は該第1の認識モードが規定する条件に設定し、音声認識手段12は該条件に基づいて入力音声の認識処理を行って、音声認識結果を当該ユーザに出力手段14を介して出力する。さらに、フィードバック生成手段13によって、ユーザが指定した前記第1の認識モードとは異なる第2の認識モードに変更して、前記入力音声と同一の音声データに対して再度音声認識を行うか否かをユーザに問い合わせるフィードバック情報をあらかじめ定めたタイミングで生成して、当該ユーザに出力手段14を介して出力する。
(もっと読む)
音声対話装置
【課題】 音声対話装置において音声認識率の低下を抑える。
【解決手段】 音声対話装置100に、外部に音を出力音として出力する音出力部3と外部からの音を入力音として入力するための音入力部4とを設け、音入力部3に入力された入力音に対して話者認識を行うことで、音入力部4に入力された入力音が音出力部3から出力された出力音であるか否かを判別し、入力音が出力音でないと判別した場合だけ、その入力音に対して音声認識を行うようにした。これにより、音出力部3から出力音として出力されて音入力部4に入力された入力音に対して音声認識は実行されず、誤認識の発生が防止されるため、音声認識率の低下を抑えることができる。さらに、適応フィルタを使用しないことで、適応フィルタによる推定誤差も生じないため、音声認識率の低下を抑えることができる。
(もっと読む)
音声認識による機器制御装置
【課題】
離れた場所から電気機器の制御を行う際に、リモコンを使う方法では、咄嗟のときにリモコンが見つからないという不便があり、またスイッチを使わずに音声認識を行う方法では、雑音などに誤反応することが多く煩わしい。
【解決手段】
最初にリモコン等を用いる手動モードで音声認識を行い、同時に音声認識の対象とすべき音入力データと、そうでない音入力データとを教師信号データベース120に蓄積する。蓄積された教師信号データをもとに、自動の判定パラメータ学習122を実行して判定パラメータデータベース124を作成し、十分に高い精度が得られるようになったら自動モードに移り、音入力データの音声・非音声自動判定114を実行する。
(もっと読む)
音声対話装置、音声対話方法、および音声対話プログラム
【課題】対話者と装置との対話中に話題が変化した場合であっても正確な認識を行うことを可能とする音声対話装置、音声対話方法、および音声対話プログラムを提供する。
【解決手段】マイクから入力されたユーザの音声データが、実行中のタスクに対応する実行モデルを用いて音声認識される(S103)。正面顔が認識できなくなった場合(S113:NO)、ユーザが音声対話装置との対話を中断し、第三者と対話し始めたと判断され、実行中のタスクは中断される(S141)。第三者との対話がすべての言語モデルで音声認識され、認識結果に基づいて、音声対話装置との対話再開後のタスクに対応する予測モデルが決定される。音声対話装置との対話が再開されると、実行モデルと予測モデルとを用いた音声認識が行われる(S103、S121)。
(もっと読む)
情報処理装置及びその制御方法
【課題】 途中までの処理を確定する処理にメモリが必要な場合、メモリ不足に起因して処理を中断した時に、確定処理を実行できない。
【解決手段】 メモリ管理部202は、現フレームのデータ処理を実行する前に、当該データ処理に必要なメモリサイズをメモリの空き領域に確保できるかどうかを判定する。メモリ管理部202が当該データ処理に必要なメモリサイズをメモリの空き領域に確保できないと判定した場合、制御部201は、現フレーム以降のデータ処理を中断し、現フレームより過去のフレームに対して実行済みのデータ処理結果に基づいて確定処理を行うよう制御する。
(もっと読む)
音声認識および車載装置
【課題】車載装置の主要な処理に対して音声認識の処理の負担を軽減する。
【解決手段】音声認識により操作可能な車載装置において、入力されたユーザの音声を取得し、音声辞書記憶部104上の音声辞書に格納されたいずれかの認識対象語句と一致するか否かを判定する音声認識部100と、所定の認識対象語句が格納された第1の音声辞書105及びユーザの指示内容を特定するための認識対象語句が格納された第2の音声辞書106のいずれかを、音声辞書記憶部104に設定する音声辞書切替部102と、を備え、音声辞書切替部102は、音声認識部100が取得したユーザの音声と第1の音声辞書に格納されたいずれかの認識対象語句とが一致すると判定した場合に、音声辞書記憶部104に第2の音声辞書を設定する。
(もっと読む)
操作方法およびそのための操作装置、プログラム
【課題】情報家電製品等の操作対象を音声により容易且つ確実に操作する操作方法およびそのための操作装置、プログラムを提供すること。
【解決手段】操作方法は、全操作対象の辞書と文法の読込を行う手順a、発声位置−操作対象マップの読込を行う手順b、マイクロフォンアレイから音声データの取り込みを行う手順c、ユーザの発声位置と周囲雑音の到来方向推定を行う手順d、ユーザの発声があると判断したとき、周囲雑音の抑圧と特徴補正を行うと同時に、頭部方向推定および操作対象の特定と操作対象に基づく辞書および文法の切替を行う手順e、切り替えた操作対象の辞書と文法に基づいて求めた特徴補正の結果より音声認識処理を行う手順f、音声認識結果を受け取ったときにはその結果により操作対象を遠隔制御し、これら以外の判断結果のときには手順cへ戻る手順からなる。
(もっと読む)
音声認識装置
【課題】 音声認識を行う機器において、特別なハードウェアを追加することなく操作性の向上を図る。
【解決手段】 音声認識モードに移行するトリガーとして外部マイク・イヤホンの挿入割り込みの検知を用いる。この挿入割り込みを検知して、自動で音声認識モードに移行する。
(もっと読む)
音声認識装置、音声認識装置を備えたナビゲーション装置、音声認識方法、音声認識プログラム、および記録媒体
【課題】音声認識を開始させる際の、利用者の手間を軽減すること。
【解決手段】音声認識装置100は、入力部101と、検知部102と、画像認識部103と、音声認識部104と、を備える。入力部101には、利用者からの音声が入力される。検知部102は、利用者の身体のうち発話時に動作する部位を検知する。画像認識部103は、検知部102による検知結果に基づいて、利用者の発話に関する行動状態を画像認識する。音声認識部104は、画像認識部103によって利用者の発話に関する行動状態が画像認識された後に、入力部101に入力される音声に対する音声認識を開始する。
(もっと読む)
車載用情報提供対話装置
【課題】手詰まり状態を解消できる車載用情報提供対話装置を提供することにある。
【解決手段】
本発明の車載用情報提供対話装置は、ユーザがマイク101に入力した情報に基づいて、所定のタスクを達成する制御部310と、タスクの進捗状況に基づいて、ユーザに手詰まり状態が発生したか判断する判定部313と、手詰まり状態が発生したとの判断に基づいて、オペレータ110側の通信装置1091とハンドオーバ接続する通信装置107とを備えている。
(もっと読む)
1 - 20 / 73
[ Back to top ]