
Fターム[5J064BA11]の内容
圧縮、伸長、符号変換及びデコーダ (21,671) | 圧縮、伸長方式 (3,708) | 文字圧縮(ワープロ) (27)
Fターム[5J064BA11]に分類される特許
1 - 20 / 27
データ転送制御装置、データ転送制御方法、およびデータ転送制御システム
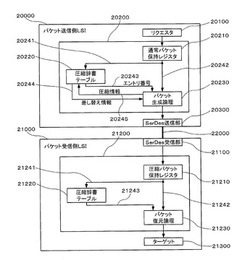
【課題】圧縮用の辞書のサイズを大きくしなくても、辞書のポインタを用いてデータの差し替えを行うことができる確率を高めることができるデータ転送制御装置を提供する。
【解決手段】エントリ毎に複数にフィールドに区分されたパケットヘッダを複数エントリ分記憶する圧縮辞書テーブル処理部20220であって、圧縮対象の情報と圧縮辞書テーブル処理部20220に記憶されている情報とをエントリ毎かつ区分毎に比較する手段と、その比較結果を複数のエントリ間で比較する手段とを備えるものと、その比較の結果に基づいて選択された1つのエントリを表す情報と、該選択したエントリにおいて圧縮対象の情報と一致した1個以上の区分を表す情報と、圧縮対象の情報において該選択したエントリと一致しなかった0個以上の区分に対応する情報を表す情報とから圧縮パケットヘッダを生成するパケット生成論理21230を備えている。
(もっと読む)
適応データ圧縮のための方法および装置

【課題】適応データ圧縮を実行するための方法および装置を提供する。
【解決手段】未知の記号がエンコーダによりエンコードされるたびに、エンコーダは辞書に記号を加え、これをエンコードされたストリングで普通に伝送する。コードワードの前にある接頭語ビットの状態は、コードワードが、辞書に記憶される普通記号であるか、または記号もしくは記号のストリングのインデックスであるかを示す。デコーダはコードワードが普通に記号を記憶する場合、先にデコードされた記号と現在デコードされた記号の第1の記号との連結により生じる一連の記号を加えることにより、かつ、この記号をその辞書に加えることにより、記号を学習する。コードワードがインデックスを記憶する場合、デコーダは辞書においてそれぞれのインデックスで、辞書に記憶される記号または一連の記号を抽出することにより、コードワードをデコードする。
(もっと読む)
文字列データ圧縮装置及びその方法並びに文字列データ復元装置及びその方法
【課題】文章などで使用している文字列全体のビット数の削減を図り、全体として使用するデータの容量を圧縮する。
【解決手段】文字コード列を含む文字列データを圧縮するための文字列データ圧縮装置であって、或る文字コードを、該或る文字コードにより表される数値から基準となる文字コードにより表される数値を差し引くことにより得られる差分に対応したビット列である文字ビット列に変換する文字コード圧縮処理部と、隣接する文字ビット列の区切りを認識するための区切りビット列を生成する区切り情報生成処理部と、前記文字ビット列の並びと前記区切りビット列の並びとを結合する情報結合処理部と、を備える。
(もっと読む)
情報処理装置及びその制御方法及びプログラム及び記憶媒体
【課題】辞書として用いる文字列テーブルへの登録処理の回数を抑制することにより、効率良く伸張する。
【解決手段】一時バッファ制御部502はLZW符号語がクリアコード又は終了コードとなるまで一時バッファ503に符号語を格納し一時バッファに記憶された符号語群の中からLZW符号の文字列テーブル506を参照する文字列テーブル参照符号語を特定し、一時バッファ503の符号語群の中の文字列テーブル506への登録対象の符号語を特定する識別情報を生成する。文字列テーブル制御部504は、一時バッファ503から読出した符号語が文字列テーブル506への登録対象であるか否かを判定し、登録対象であると判定された場合、今回復号出力する文字列の先頭文字を追加することで得られる新文字列データを、文字列テーブル506の一時バッファから出した符号語で示されるエントリアドレス位置に登録する。
(もっと読む)
データ処理装置およびデータ処理方法
【課題】LZ77系の符号化方式による符号化データをより高速に復号可能とする。
【解決手段】スライドの出力は、隣接データセレクタに供給されると共に、このスライドの直後に連続的に配置される4の4入力1出力セレクタに供給される。アドレス値、レングス値およびデータ値を含む符号化データから複数(4とする)のデータ値が連続的に抽出された場合、これら4のデータ値が同時にスライド記憶部に供給される。スライド記憶部では、各セレクタの選択により各スライドの記憶内容を4スライド分出力側にシフトさせると共に、供給された4のデータ値を先頭側から4のスライドに同時に記憶させる。隣接データセレクタに接続されるスライドのうちアドレス値に対応するスライドからレングス値に対応する数だけ入力側に向けてスライドが選択され、選択されたスライドから同時にデータ値が読み出されて出力される。
(もっと読む)
データ圧縮装置、データ伸長装置、データ圧縮プログラム、及びデータ伸長プログラム
【課題】ブロックストリーム処理においてテキストデータの圧縮率を向上させる。
【解決手段】テキストデータの入力を受け付け、テキストデータを複数のブロックに分割するデータ取得部110と、文字列と符号とが対応付けられて格納された基準辞書に基づき、処理対象ブロックに出現する文字列のうち、基準辞書に登録されていない文字列と、基準辞書において処理対象ブロックに出現しない文字列に対応付けられた符号とを対応付けた差分辞書を生成する差分辞書生成部112と、作成した差分辞書と基準辞書とに基づき、処理対象辞書を生成する辞書作成部111と、生成した処理対象辞書を参照し、処理対象ブロックに出現する文字列を対応する符号に置き換えることで、処理対象ブロックを圧縮する符号化部113と、符号化部113が圧縮した処理対象ブロックのデータと、生成した差分辞書とを出力する出力部114と、を備える。
(もっと読む)
データの圧縮方法
本発明はデータの圧縮方法に係り、さらに詳しくは、コンピュータデータを圧縮するに際して、文字列辞書を生成してインデックスを格納する方法と、文字列に対する圧縮コードを格納する方法とを併用することにより、圧縮率を向上させることのできるデータの圧縮方法に関する。本発明によれば、圧縮率が向上し、且つ、解凍時の速度が高くなるという効果がある。
 (もっと読む)
(もっと読む)
シグナリング圧縮装置、シグナリング伸長装置およびシグナリング圧縮伸長装置
【課題】初めて出現する文字列パターンを多く含むシグナリングメッセージであっても効率の良い圧縮が可能なシグナリング圧縮装置を得る。
【解決手段】固定/可変パターン分離部1は、シグナリングメッセージ内の固定的な文字列パターンと可変な文字列パターンとを識別して、固定的な文字列が連続するよう文字列の並べ替えを行う。圧縮器2は、固定/可変パターン分離部1から出力されたシグナリングメッセージを圧縮する。固定/可変パターン結合部5は、伸長器4で伸長されたシグナリングメッセージに対して、シグナリングプロトコルによって規定される書式に従った順序に戻す文字列の並べ替えを行う。
(もっと読む)
情報処理プログラム、情報処理装置、および情報処理方法
【課題】文字コードの圧縮効率の向上と圧縮処理や伸長処理の高速化を図ること。
【解決手段】2n分枝ハフマン木H1において、根は図1の第1階層の節点の構造体セルC(1,1)に相当する。また、(A)〜(C)は節点または葉を示している。□は葉を示しており、■は節点を示している。下位節点/葉に枝が出ていない■は、使用されない節点である。また、葉の直下の数字は、葉の番号を示している。葉をL♯(♯は葉の番号)と表記する。
(もっと読む)
データ圧縮及びデータ伸張
【課題】文字圧縮の改良されたデータ圧縮及び/又は伸張技法を提供する。
【解決手段】前に復号されたデータアイテムの群の参照子の順序付けられたストリーム、復号されるデータアイテムの直接的表現の順序付けられたストリーム、及び各連続的な伸張オペレーションが参照子に作用すべきであるのか、又は直接的表現に作用すべきであるのかを示すフラグの順序付けられたストリームを備える圧縮データに作用するように構成されるデータ伸張装置が開示される。該装置は、出力メモリエリア、伸張オペレーションが直接的表現に作用すべきであることを示す個数nの連続したフラグを検出する検出器、及び前に復号されたデータの次の参照される群又は直接的表現の順序付けられたストリームからのn個の連続した直接的表現の群のいずれかを出力メモリエリアへコピーするためのデータコピー器を備える。
(もっと読む)
階層セグメント表現を含む記憶および伝送時のデータ圧縮に関するコンテント・ベースのセグメント化方式
【課題】データ圧縮に関するコンテント・ベースのセグメント化方式の提供。
【解決手段】符号化は、ターゲット・セグメント・サイズを判定する段階と、窓サイズを判定する段階と、入力データ内のオフセットにおける記号の窓内のフィンガープリントを識別する段階と、オフセットをカット・ポイントとして指定すべきかどうかを判定する段階と、カット・ポイントの組によって示されるように入力データをセグメント化する段階とを含む。そのように識別された各セグメントについて、エンコーダは、セグメントが参照されるセグメントであるかそれとも参照されないセグメントであるかを判定し、それぞれの参照されるセグメントのセグメント・データを参照ラベルで置き換え、必要に応じて、それぞれの参照されるセグメントの持続セグメント・ストアに参照バインディングを記憶する。
(もっと読む)
階層セグメント表現を含む記憶および伝送時のデータ圧縮に関するコンテント・ベースのセグメント化方式
【課題】データ圧縮に関するコンテント・ベースのセグメント化方式の提供。
【解決手段】符号化は、ターゲット・セグメント・サイズを判定する段階と、窓サイズを判定する段階と、入力データ内のオフセットにおける記号の窓内のフィンガープリントを識別する段階と、オフセットをカット・ポイントとして指定すべきかどうかを判定する段階と、カット・ポイントの組によって示されるように入力データをセグメント化する段階とを含む。そのように識別された各セグメントについて、エンコーダは、セグメントが参照されるセグメントであるかそれとも参照されないセグメントであるかを判定し、それぞれの参照されるセグメントのセグメント・データを参照ラベルで置き換え、必要に応じて、それぞれの参照されるセグメントの持続セグメント・ストアに参照バインディングを記憶する。
(もっと読む)
データ圧縮装置、データ併合装置、データ整序装置、データ統合システム、無線タグデータ統合システム、データ圧縮プログラム、データ併合プログラム及びデータ整序プログラム
【課題】 大量のデータを少ないリソースでの効率よい統合を可能にする。
【解決手段】 本発明のデータ統合システムは、データ整序装置と、データ圧縮装置と、データ併合装置とを備え、データ整序装置は、データリストの各データを共通データと個別データに分割する手段と、個別データについて昇順又は降順に並べ替えて整序済データリストを作成する手段とを有し、データ圧縮装置は、一定の差分で並んだ一定差分データリストを抽出する手段と、上記一定差分データリストを少なくとも先頭データ、上記差分、及び、データ数のデータを有する1つの組のデータに圧縮して置換し、データリストのデータ量を圧縮する手段とを有し、データ併合装置は、複数のデータリストを1つのデータリストに併合して併合済データリストを作成する手段を有することを特徴とする。
(もっと読む)
適応データ圧縮のための方法および装置
【課題】適応データ圧縮を実行するための方法および装置を提供する。
【解決手段】未知の記号がエンコーダによりエンコードされるたびに、エンコーダは辞書に記号を加え、これをエンコードされたストリングで普通に伝送する。コードワードの前にある接頭語ビットの状態は、コードワードが、辞書に記憶される普通記号であるか、または記号もしくは記号のストリングのインデックスであるかを示す。コードワードが普通に記号を記憶する場合、デコーダは、先にデコードされた記号と現在デコードされた記号の第1の記号との連結により生じる一連の記号を加えることにより、かつ、この記号をその辞書に加えることにより、記号を学習する。コードワードがインデックスを記憶する場合、デコーダは、辞書において、それぞれのインデックスで、辞書に記憶される記号または一連の記号を抽出することにより、コードワードをデコードする。
(もっと読む)
データ圧縮方法及びシステム
【課題】LZ77ベース機構を用いて入力データストリームの圧縮方法及びシステムを提供。
【解決手段】バイトの現在シーケンスと同一である既に処理されたデータバイトの一致シーケンスがサーチされ、リテラル(一致シーケンスの部分を形成しないバイト)又は一致コード(エンコードされた一致シーケンス)のシーケンスがリテラル又は一致コードの数を示すカウント値によって識別される。圧縮及び圧縮解除には一致円形ヒストリバッファが使用され、これは、送信されるエンコードデータの各フレームと共に含まれるコヒレンスバイトを用いて同期される。エンコードされたフレームが圧縮解除装置によって受け取られない場合は、圧縮解除装置が圧縮装置へフラッシュ要求送信する。圧縮装置は、そのフラッシュ要求に応答してヒストリバッファをフラッシュし、ヒストリバッファに記憶された既処理されたバイトを一致シーケンスの部分にならないようにする。
(もっと読む)
データ圧縮方法及び圧縮データ送信方法
【課題】スライド辞書に、出現頻度の高い長い文字列を初期値として登録できるようにする。
【解決手段】サンプルデータ中の文字列を先頭3文字(“ABC”)が等しい文字列同士のグループに分類する。各グループから、サンプルデータ中において最も出現頻度が高い文字列(最頻出文字列)を1個づつ抽出する。各グループから抽出した最頻出文字列を出現頻度順に初期値として辞書に登録する。
(もっと読む)
時系列データの等長圧縮方法
【課題】 エンコーダレスかつ判別対象データの再現性向上による判定範囲の適切な最狭化を可能にして媒体識別性能を向上させることができる時系列データの等長圧縮方法を提供する。
【解決手段】 一定周期のサンプリング処理により得られたデータの取得データ点数Yを基に、取得データ点数Yと変換係数M,Nとの対応関係を示すテーブルを参照して変換係数M,Nを求め、取得データをM倍長バッファにM個ずつ同一データを格納し、それをN倍長バッファにコピーし、そのデータをN個ずつ平均値の演算をして圧縮バッファに格納する。これにより、取得データ点数Yが変動するデータを一定のデータ点数Wの圧縮データに変換できるので、判別対象データの再現性が向上し、判定範囲の最狭化、媒体識別性能の向上が可能になる。
(もっと読む)
符号化装置、復号装置、および、符号化方法ならびに復号方法
【課題】 符号化における一致長とその一致長符号との関係を動的に変化させて、一致長符号により表現可能な長さを自立的に切り替える。
【解決手段】 データバッファ110におけるスライド窓を辞書として、文字列検索部130は入力データの部分文字列と一致する文字列を検索する。内部状態保持部140に保持された内部状態に対応して、一致長拡張テーブル150は一致長とその一致長符号との関係を保持している。一致長符号化部160は内部状態に基づいて一致長拡張テーブル150を参照して、一致長とその一致長符号との対応付けを動的に決定する。文字列符号化部170はスライド窓における相対位置と一致長符号により符号列を生成する。
(もっと読む)
データ圧縮方法及びシステム
【課題】LZ77ベース機構を用いて入力データストリームを圧縮する方法及びシステムを提供する。
【解決手段】入力ストリームがLZ77ベース機構を用いてエンコードストリームに圧縮される。リテラル(一致シーケンスの部分を形成しないバイト)又は一致コード(エンコードされた一致シーケンス)の数を示すカウント値によって識別される。エンコードされたストリームは第1コンピュータから第2コンピュータへ送られ、そこで圧縮解除される。エンコードされたフレームが圧縮解除装置によって受け取られない場合は、圧縮解除装置が圧縮装置へフラッシュ要求を送信する。圧縮装置は、そのフラッシュ要求に応答してヒストリバッファをフラッシュし、ヒストリバッファに記憶された既に処理されたバイトを一致シーケンスの部分にならないようにする。
(もっと読む)
データ圧縮装置、及びデータ復元装置
【課題】 本発明は文字データや画像データ等の各種のデータの圧縮装置、及び、復元装置に関し、高速で且つ圧縮効率の高いデータ圧縮、復元装置、及びデータ圧縮、復元方法を提供するものである。
【解決手段】 本発明は適応型の辞書型符号化方法を用いた第1の圧縮手段1と準適応型の確率統計型符号化方法を用いた第2の圧縮手段2を使用し、先ず入力データを圧縮手段1に入力し、圧縮手段1によって符号化処理を行い、更に第2の圧縮手段2を使用して圧縮処理を行う構成であり、特徴の異なる符号化方法を組合せ、補完しあうことにより、より高速で且つ圧縮効率の高い、データ圧縮、復元装置、及びデータ圧縮、復元方法を提供するものである。
(もっと読む)
1 - 20 / 27
[ Back to top ]