
国際特許分類[G06F15/173]の内容
物理学 (1,541,580) | 計算;計数 (381,677) | 電気的デジタルデータ処理 (228,215) | デジタル計算機一般 (4,503) | 各々が少くとも算術演算ユニット,プログラム・ユニットおよびレジスタをもつ2つ以上のデジタル計算機が結合されたもの,例.数個のプログラムの同時処理を行うためのもの (694) | プロセッサ間通信 (496) | 相互接続ネットワークを用いるもの,例.マトリックス,シャフル,ピラミッド,スター,スノーフレーク (230)
国際特許分類[G06F15/173]に分類される特許
1 - 10 / 230
異なる複数の優先度レベルのトランザクション要求をサポートする集積回路内における処理リソース割振り
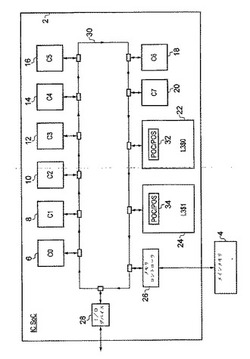
【課題】異なる複数の優先度レベルのトランザクション要求をサポートする集積回路内における処理リソース割振りを実現すること。
【解決手段】集積回路2は、複数のトランザクションソース6、8、10、12、14、16、18および20を含み、トランザクションソースは、関連付けられたPOC/POS30および34を各々が有する共有キャッシュ22および24とリングベースの相互接続30を介して通信し、要求サービング回路として働く。要求サービング回路は、異なる複数のトランザクションに割り振ることができる処理リソース36のセットを有する。これらの処理リソースは、動的に、または静的に割り振ることができる。静的割振りは、選択アルゴリズムに依存して行うことができる。この選択アルゴリズムは、入力変数のうちの1つとしてサービス品質値/優先度レベルを使用することができる。
(もっと読む)
ネットワークを構成している複数のノード(プロセッサ)間において、全対全通信(A2A:all−to−allcommunication)を含む、複数の計算処理をスケジューリングする方法、プログラム及び並列計算機システム。

【課題】n次元の(トーラスまたはメッシュ)ネットワークを構成している複数のノード(プロセッサ)間において、全対全通信(A2A:all-to-all communication)を含む複数の計算処理を、最適にスケジューリングすること。
【解決手段】ネットワークを構成している複数のノード(プロセッサ)を、第1の部分グループに含まれる複数のノード間のみについての全対全通信に要する通信(計算処理)フェーズ(A2A−L)と、第2の部分グループに含まれる複数のノード間のみについての全対全通信に要する通信(計算処理)フェーズ(A2A−Pとに分け、複数のスレッド(スレッド1、スレッド2、スレッド3、スレッド4)にわたって、それぞれのフェーズをオーバーラップさせて並列処理する。FFT(Fast Fourier Transform)(高速フーリエ変換)やT(transpose)((内部:internal)転置)という複数の計算処理についてもあわせて、並列処理することができる。
(もっと読む)
相互接続装置、および、相互接続装置の制御方法ならびに当該方法をコンピュータに実行させるプログラム
【課題】相互接続装置においてデッドロックを回避しつつ、レイテンシを低減する。
【解決手段】リクエスト管理部は、複数のマスタのいずれかから複数のスレーブのいずれかに対して発行されたリクエストがそのリクエストに先行して発行された先行リクエストの複数のスレーブのいずれかへの出力を待つべき待機リクエストである場合にはその待機リクエストに先行リクエストを対応付けて管理する。調停部は、複数のマスタから発行された複数のリクエストを調停して調停したリクエストを複数のスレーブのうち調停したリクエストの宛先である応答デバイスに出力する。リクエスト待機制御部は、待機リクエストを待機させて、その待機リクエストに対応する先行リクエストが複数のスレーブのいずれかに出力された後に待機リクエストを調停部へ出力する。
(もっと読む)
ネットワーク装置及びネットワーク管理装置
【課題】全対全の信号伝送における広い帯域の確保と低い遅延とを両立するネットワーク装置及びネットワーク管理装置を提供する。
【解決手段】1段目のスイッチ(B1〜B9)、2段目のスイッチ(M1〜M9)及び3段目のスイッチ(T1〜T9)は、3段目のスイッチ(T1〜T9)と1組のファットツリーを構成する2段目のスイッチ(M1〜M9)において、1段目のスイッチ(B1〜B9)との間で、ファットツリーの構成から少なくとも1つの前記第2信号転送部の接続先と他の第2信号転送部の接続先とを交換し手接続する下段接続経路とを備える。
(もっと読む)
ネットワーク管理装置及びネットワーク管理方法
【課題】誤結線が発生した場合のネットワークの性能の低下を軽減するネットワーク管理装置及びネットワーク管理方法を提供する。
【解決手段】初期アドレス割当部11は、1段目スイッチ22のそれぞれに接続された複数のノード21に対して所定のアドレスを割り当てる。接続状態取得部12は、各1段目スイッチ22、各2段目スイッチ23及び各3段目スイッチ24のそれぞれから各々の接続状態を取得する。誤結線検出部13は、接続状態取得部12により取得された結線状態と予め記憶している所定の結線状態とを比較し、誤結線を検出する。アドレス変更部14は、誤結線検出部13により誤結線が検出された場合、接続状態を基に、初期アドレス割当部11により割り当てられたノード21のアドレスを第1の所定条件を満たすように変更する。
(もっと読む)
集積回路装置及び電子機器
【課題】グラフィックス処理性能をスケーラブルに調整可能であり、目標とする処理性能に応じて、最適なシステムを構築することのできる集積回路装置を提供する。
【解決手段】目標性能に応じた数の集積回路をカスケード接続することにより、グラフィックス処理性能をスケーラブルに拡張又は縮小できるという知見に基づく。第1の集積回路1と、第2の集積回路2と、第1の集積回路1と第2の集積回路2を接続する通信用バス4と、第1の集積回路1の演算結果を第2の集積回路2に出力するための入出力用バス5を含む。
(もっと読む)
データ処理装置及びデータ処理方法
【課題】大量のCPUを使用して大規模な計算を行うデータ処理装置を構成する場合、パケット通信をベースとした手法が使用されていた。この方法では、転送の粒度やオーバーヘッドが大きく、また転送の粒度を小さくし、かつオーバーヘッドを減らそうとすると、CPUやOSへの修正が必要になりコストがかかる。
【解決手段】イニシエータIPモジュールと、リクエスト転送回路と、レスポンス転送回路と、自クラスタ番号レジスタ等を含むクラスタを2つ以上具備し、イニシエータIPモジュールからのリクエストに対して、特定のアドレスへのアクセスであった場合、別クラスタへの転送に要する情報を付与し、その情報を元に転送先が自クラスタか別クラスタかを判定してデータを転送するようにデータ処理装置を構成する。自クラスタから別クラスタへのアクセスを行う場合、別クラスタへのアクセスを行う前に、転送先のクラスタ番号およびアドレスを設定してからアクセスを行うようにする。
(もっと読む)
異種計算機システムにおけるプロセッサブリッジ
【課題】ブリッジ論理デバイスを提供する。
【解決手段】1つ以上の高性能プロセッサと、該1つ以上の高性能プロセッサがソフトウェアのタスクを実行するのを支援するプロセッサ支援論理回路と、該1つ以上の高性能プロセッサより少ない電力を消費するハイパーバイザプロセッサとを有する異種計算機システムのためのブリッジ論理デバイス。このブリッジ論理デバイスは該1つ以上の高性能プロセッサの下の該システムのステータスを保守するハイパーバイザ動作論理回路と、該1つ以上の高性能プロセッサと該ハイパーバイザプロセッサとのプロセッサ言語間の翻訳をするプロセッサ言語翻訳論理回路と、第1、第2、及び第3ポートを有し該3つのポートのうち任意2つの間でデータを双方向に中継する高速バススイッチとを備える。該バススイッチは該1つ以上の高性能プロセッサに該第1ポートが接続され、該ハイパーバイザプロセッサに該プロセッサ言語翻訳論理回路を介して該第2ポートが接続され、該プロセッサ支援論理回路に該第3ポートが接続される。
(もっと読む)
マルチプロセッサおよびそれを用いた画像処理システム
【課題】データの共有やデータ転送のバッファリングを容易に行なうことが可能なマルチプロセッサを提供すること。
【解決手段】複数の共有ローカルメモリ5−0〜5−(n−1)のそれぞれが、複数のプロセッサユニットPU0〜PU(n−1)(1−0〜1−(n−1))の中の2つのプロセッサに接続されており、複数のプロセッサユニットPU0〜PU(n−1)(1−0〜1−(n−1))と複数の共有ローカルメモリ5−0〜5−(n−1)とがリング状に接続される。したがって、データの共有やデータ転送のバッファリングを容易に行なうことが可能となる。
(もっと読む)
半導体集積回路装置
【課題】容易にカスタマイズ対応可能な半導体集積回路装置を提供する。
【解決手段】アレイ型プロセッサ部(300)は、プロセッサエレメント(330)とプログラマブルスイッチ(320)とを備えるプロセッサユニット(310)をマトリクス状に配置する。プロセッサエレメント(330)は、複数ビット幅の第1演算器(332)と複数ビット幅より狭い所定のビット幅の第2演算器(333)とを有する。第1演算器(332)および第2演算器(333)の接続構成は構成情報メモリ(340)に設定される構成情報に基づいて変更可能である。プログラマブルスイッチ(320)は、配線からプロセッサエレメントに複数ビット幅のデータおよび所定のビット幅のデータを構成情報に基づいて入出力する。制御回路(200)は、内部バス(180)に接続され、アレイ型プロセッサ部(300)の動作を制御し、内部バス(180)を介してデータを授受する。
(もっと読む)
1 - 10 / 230
[ Back to top ]