
国際特許分類[G10L15/00]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 音声認識 (6,879)
国際特許分類[G10L15/00]の下位に属する分類
音声認識のための特徴抽出;認識単位の選択 (203)
セグメンテーション,または語区切れ検出 (272)
標準パタンの作成;音声認識システムの学習,例.話者適応 (725)
音声の識別または探索 (1,500)
不利な環境に特に適した音声認識技術,例.雑音またはアクセントのある音声 (334)
音声認識処理中の手順,例.マン・マシン対話 (884)
音響以外の特徴を用いる音声認識,例.唇の位置 (190)
音声をテキストに変換するシステム (3)
音声認識システムの構造上の細部 (875)
国際特許分類[G10L15/00]に分類される特許
121 - 130 / 1,893
メッセージ映像編集プログラムおよびメッセージ映像編集装置
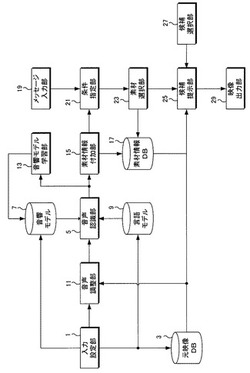
【課題】ユーザが入力するメッセージテキストに合致する音声を再現した任意のメッセージ映像データの作成を容易に実現する。
【解決手段】映像データに付随し時刻毎に分割された音声データの発声内容を示すと共に前記映像データと前記発声内容とを対応付ける対応情報を格納する素材情報データベース17と、ユーザにより入力されたテキストデータを構成する最小単位のテキストデータにそれぞれ対応する発声内容の音声データおよび前記音声データに対応付けられた映像データを、対応情報に基づいて元映像データベース3から抽出する素材選択部23と、前記抽出した音声データおよび映像データを前記テキストデータの並び順に連結して音声データが付随した映像データの候補を提示する候補提示部25と、を備える。
(もっと読む)
音声をテキストに変換する装置及び方法

【課題】音声をテキストに変換する装置及び方法を提供することを目的とする。
【解決手段】音声受信モジュール、音声識別モジュール、表示モジュール、格納モジュール、話者識別モジュール及び制御モジュールを備え、格納モジュールは異なる音声データに対応するテキストデータ及び異なる音声信号に対応する話者データを格納し、音声受信モジュールは、外部の音声信号を受け取り、音声識別モジュールは、前記音声信号を音声データに変換してから、格納モジュールから前記音声データに対応するテキストデータを探して制御モジュールに送信し、話者識別モジュールは、格納モジュールから前記音声信号に対応する話者データを探して制御モジュールに送信し、制御モジュールは、前記テキストデータ及び前記話者データを表示モジュールに表示させる。
(もっと読む)
音声処理装置、音声処理システム及び音声処理方法
【課題】入力される音の誤認識を抑制することを可能とする音声処理装置、音声処理システム及び音声処理方法の提供。
【解決手段】本実施形態の音声処理装置は、外部からの入力を受け付ける第1受付手段と、前記第1受付手段が前記入力を受け付けた場合に、音声出力機能を有する少なくとも1の外部機器に対して音量制限命令を送出する制限手段と、前記第1受付手段が前記入力を受け付けた後に、音の入力を受け付ける第2受付手段と、前記制限手段により制限された前記1以上の外部機器の音量の解除命令を、前記第2受付手段が受け付けた前記音に応じて異なるタイミングで送出する解除手段とを備える。
(もっと読む)
音声をテキストに変換する装置及び方法
【課題】音声をテキストに変換する装置及び方法を提供することを目的とする。
【解決手段】本発明の音声をテキストに変換する装置は、音声受信モジュール、音声識別モジュール、表示モジュール、入力モジュール及び制御モジュールを備え、前記音声受信モジュールは、外部の音声信号を受け取って前記音声識別モジュールに送信し、前記音声識別モジュールは、異なる所定の時間範囲における各々の所定の時間範囲内の音声信号をテキストデータに変換してから前記制御モジュールに送信し、前記入力モジュールは、ユーザーが入力した文字データを前記制御モジュールに送信し、前記制御モジュールは、同じ所定の時間範囲内のユーザーが入力した文字、音声から変換されたテキスト及び同じ前記所定の時間範囲を前記表示モジュールに表示させる。
(もっと読む)
状態検出装置、状態検出方法および状態検出のためのプログラム
【課題】負荷を抑えつつ、特定の話者の状態を精度よく検出する状態検出装置を提供する。
【解決手段】音声に含まれる情報を利用して特定の話者の状態を精度よく検出するために、状態検出装置に、非抑圧状態における特定の話者の音声の特徴をモデル化した第1の特定話者モデルを生成する第1のモデル生成手段と、対応関係情報に基づいて、第1の不特定話者モデルに対する第2の不特定話者モデルへの変位量を、第1の特定話者モデルに反映することにより、抑圧状態における特定の話者の音声の特徴をモデル化した第2の特定話者モデルを生成する第2のモデル生成手段と、入力音声の特徴に対する第1の特定話者モデルの尤度である第1の尤度と、入力音声に対する第2の特定話者モデルの尤度である第2の尤度と、を算出する尤度算出手段と、第1の尤度および第2の尤度に基づいて、入力音声の話者の状態を判別する状態判別手段と、を備える。
(もっと読む)
音声認識装置、音声認識方法および音声認識装置を搭載したテレビ受像機
【課題】ローカル型と分散型の音声認識の切り替えをユーザに意識させることなく、音声認識の使い分けを実現することである。
【解決手段】実施形態の音声認識装置は、音声を入力する音声入力手段と、当該音声入力手段に入力された音声を認識する第1の音声認識手段と、外部サーバと通信する通信手段と、当該通信手段で接続された外部サーバ上で前記音声入力手段に入力された音声を認識する第2の音声認識手段と、リモコン信号を入力するリモコン信号入力手段と、当該リモコン信号入力手段に入力されたリモコン信号から認識開始指示を検出した場合は前記第2の音声認識手段で前記音声入力手段に入力された音声を認識し、前記音声入力手段に入力された音声から認識開始指示を検出した場合は前記第1の音声認識手段で前記音声入力手段に入力された音声を認識するよう第1と第2の音声認識手段を切り替える音声認識切替手段とを備える。
(もっと読む)
呼接続制御装置、電話端末及び電話網
【課題】電話を使った詐欺や悪徳商法などの犯罪を最小限にし又は未然に防止し、電話加入者の電話利用の安全性を向上させる。
【解決手段】電話網に、詐欺の手口の変化に柔軟に対応可能な音片データを持つデータベースと、電話呼制御が可能な詐欺対策装置を配備し、詐欺対策のサービスを享受したい電話加入者に対して着信する呼について、発信者及び着信者に、この通話は詐欺対策機能が動作するもとで呼接続される旨のガイダンスを送出し、呼接続成立後に、発信者及び着信者からの音声を音声認識し、詐欺で多用される用語を検出した際には、通話中又は呼切断後直ちに着信者又は予め設定された着信者の関係者に対して、詐欺対策装置から、先に行われた通話は詐欺である可能性が高い旨注意を喚起する。また、詐欺の可能性の高い通話を記録し、有識者に通話内容を提示し、新しい手口の詐欺に対応できる新しい用語を抽出させて新たに登録する。
(もっと読む)
車載装置
【課題】車両に運転者以外の者が乗車している場合であっても、そのときの乗員構成に最適なサービスを提供する。
【解決手段】車載装置10の制御装置11は、車載マイク12により、車内に発生した音声を収集し、シートセンサ19により、着座位置を特定し、発話者推定部31により、音声および着座位置に基づいて発話者を推定し、会話内容推定部32により、音声に基づいて会話内容を推定し、乗員構成推定部33により、着座位置、発話者および会話内容に基づいて乗員構成を推定し、行動目的推定部34により、会話内容および乗員構成に基づいて行動目的を推定し、レコメンドサービス決定部35により、乗員構成および行動目的に基づいて推奨するサービスを決定する。
(もっと読む)
音声処理装置および音声処理プログラム
【課題】定常雑音を含む信号に対する処理において、周波数軸上で処理する技術と比較して処理時間を短縮することを課題とする。
【解決手段】音声処理装置100のゲイン算出部140は、同期減算結果のパワーと、音声入力部110Lにより入力された信号のパワーとを用いて、信号の振幅を抑圧するゲインを算出する。例えば、ゲイン算出部140は、パワー計算部130Lにより計算された信号(inL)のパワー(Power2)から、パワー計算部130Rにより計算された同期減算結果(tmp1)のパワー(Power1)を減算する。そして、ゲイン算出部140は、減算結果(Power21)を信号(inL)のパワー(Power2)で除算した値の平方根を計算することによりゲイン(gain)を算出する。
(もっと読む)
音声認識装置及び車載システム
【課題】 音声認識装置の作動制御が破綻してしまうことを抑制する。
【解決手段】 ユーザが触れて操作するトークスイッチの操作回数(クリック回数c)に基づいて音声認識エンジンが参照すべき認識辞書を選択する。これにより、音声の誤認識に起因して参照すべき認識辞書の選択ミスが発生することはないので、音声認識装置の作動制御が破綻してしまうことを抑制することができる。
(もっと読む)
121 - 130 / 1,893
[ Back to top ]