
国際特許分類[G10L15/08]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 音声認識 (6,879) | 音声の識別または探索 (1,500)
国際特許分類[G10L15/08]の下位に属する分類
未知音声と標準パタンとの距離または歪みを用いるもの (838)
動的計画法を用いるもの,例.動的時間伸縮[DTW] (22)
統計的モデルを用いるもの,例.隠れマルコフモデル[HMM] (175)
ニューラル・ネットワークを用いるもの (24)
自然言語モデルを用いるもの (322)
国際特許分類[G10L15/08]に分類される特許
21 - 30 / 119
音声認識装置とその方法と、プログラムと記録媒体
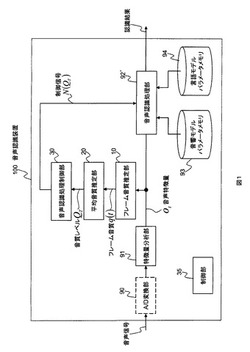
【課題】音声認識装置の処理効率を向上させる。
【解決手段】この発明の音声認識装置のフレーム音質推定部は、フレーム毎に音声ディジタル信号の音質を評価してフレーム音質を出力し、平均音質推定部は、複数フレームのフレーム音質から音質レベルを推定する。そして、音声認識処理制御部が、音質レベルに基づいて音声認識処理時の動作を制御する制御信号を音声認識処理部出力にする。音声認識処理部はその制御信号に基づいて音声認識処理を行う。
(もっと読む)
個人適応機能付きテキスト入力装置

【課題】認識精度の改善と応答時間の短縮を両立する個人適応機能付きテキスト入力装置を提供する。
【解決手段】キー入力補助付き音声入力モードに設定する入力モード切替部12と、キー入力補助付き音声入力モード下において、キー押下を検出するキー押下検出部2と、検出されたキー入力の種類により一定時間だけ文節間の遷移を限定して音声認識を行う音声認識部8と、音声認識結果を表示する表示部9と、検出されたキー押下の時刻を基準に当該文節、一つ前の文節、一つ後ろの文節の相対開始時刻の個人データを蓄積するキー入力・文節先頭時間差データ蓄積部10と、これらの個人データが一定量以上蓄積された後に、その分布を推定し、別に予め求めておいた文節の先頭音素を限定しない場合と限定した場合の認識率と合わせて認識率の改善度合いが最大になるように単語辞書限定の時間の個人適応を行う辞書限定時間個人適応部11とを具備する。
(もっと読む)
音声認識装置、その方法及びそのプログラム
【課題】少ない計算量で認識結果が得られる音声認識装置を提供する。
【解決手段】入力音声からフレーム毎に音響特徴量を抽出する特徴抽出部111と、探索ネットワーク101中の隣接した複数のノードをマージすることにより生成された圧縮ネットワーク102上で前記音響特徴量に対して探索及び枝狩りを行い、圧縮ネットワーク102の前記枝狩りされたノードに対応する探索ネットワーク101のノードを探索対象から除外して、前記入力音声の終端まで探索及び枝狩りを行って、音声認識する探索部112とを有する。
(もっと読む)
音声認識方法および装置
【課題】少ない計算量かつ記憶領域で信頼度を計算できる音声認識方法および装置を提供する。
【解決手段】音声信号の音響特徴量を多数の標準パターンと照合し、認識結果の各単語区間およびその照合スコアを取得する音声照合部105と、音声信号の音響特徴量を多数の参照パターンと照合して累積スコアを時系列で算出する評価用照合部107と、各時刻における累積スコアの最大値を記憶する最大スコア記憶部108と、各単語区間の開始時刻および終了時刻における累積スコアの最大値に基づいて各単語区間の評価用スコアを算出する評価用スコア算出部109aと、各単語区間の照合スコアおよび評価用スコアに基づいて各単語区間の信頼度を算出する信頼度算出部109とを含む。
(もっと読む)
音声応答装置、及びプログラム
【課題】入力された音声を棄却する場合に、より適切な対応を行う。
【解決手段】生成された所定個の発話内容の候補から無音を示す候補、及び生成された所定個の発話内容の候補の各々に対して形態素解析を行って候補の各々から自立語を抽出し(102、106)、生成された所定個の発話内容の候補中に、無音を示す候補が存在する場合、及び自立語を含まない候補が存在する場合には、入力された発話音声を無視するように、表示装置18及びスピーカ16から応答内容26が応答されないように制御する(104でY、108でY)。
(もっと読む)
音声認識装置及び方法
【課題】少ないメモリ容量で音声認識に対する理解を行う。
【解決手段】記憶部21に、予め各単語と、音声における単語の役割により異なる符号位置に当該単語の意味情報を含む符号列とされた識別情報とを対応付けた単語辞書データベース21bを記憶しておく。マイク2により音声を入力入力すると、音声認識部11によって音声認識をして音声認識結果として複数の単語を生成し、理解結果ID生成部12によって、認識された複数の単語に対応した単語辞書データベース21bにおける複数の識別情報の符号列同士を演算して、音声の理解結果を示す符号列を生成する。
(もっと読む)
音声認識装置
【課題】認識精度の低下を抑制しつつ処理時間の短縮を図ることが可能な音声認識装置を提供すること。
【解決手段】複数の状態間の遷移確率が設定された隠れマルコフモデル(HMM)を用いて音声認識を行なう音声認識装置であって、複数のパスについて並行して総体確率演算を行なうと共に、状態遷移の上限回数の半分以上を経過した段階で、総体確率が最大のモデルに対して10分の1未満のモデルについては、以降の総体確率演算を停止することを特徴とする、音声認識装置。
(もっと読む)
音声認識装置
【課題】記憶装置に保持されている情報量が過大となることを防止しながら、音声情報が表す音声を高い精度にて表す文字列を出力することが可能な音声認識装置を提供すること。
【解決手段】この装置1は受け付けた音声情報が表す音声を時間フレーム毎に分割したフレーム毎音声をその音声の始端から終端へ向けて順に1つずつ取得する。装置は取得したフレーム毎音声と音声を表す単語を構成する要素列の仮説であり記憶装置に記憶されている単語内仮説とに基づいて取得したフレーム毎音声を表す要素列の候補を取得する。装置は取得した候補を単語内仮説に連結する。装置は単語内仮説が単語を表す場合その単語を、音声を表す単語列の仮説であり記憶装置に記憶されている単語終端仮説に連結する。装置は消去指示を受け付けた場合に記憶されている上記受け付けられた音声情報が表す音声を表す文字列としての単語列を生成可能な単語終端仮説のうちの一部を消去する。
(もっと読む)
音声認識処理機能を用いたコンテンツ検索装置、プログラム及び方法
【課題】利用者の嗜好を考慮して、利用者毎に認識精度が高いと感じさせるコンテンツを検索することができるコンテンツ検索装置等を提供する。
【解決手段】コンテンツ検索装置は、音声波形を入力する音響特徴量抽出手段と、認識結果候補の単語列ωに対してその音響特徴量xが観測される音響確率P(x|ω)を出力する音響モデル蓄積手段と、統計的/文法的言語確率Pn-gram(ω)/Pcfg(ω)を出力する言語モデル蓄積手段と、x、P(x|ω)及びPn-gram(ω)/Pcfg(ω)に基づいて、認識結果単語列ω^を出力する音声認識デコーダと、ωを検索キーとして、コンテンツデータベースからコンテンツを検索するコンテンツ検索手段とを有する。更に、利用者の嗜好の度合いを表す嗜好度確率P*(ω)を計算する嗜好度確率計算手段と、Pn-gram(ω)/Pcfg(ω)に、P*(ω)を重み付けた言語確率P(ω)を出力する言語確率算出手段とを有する。
(もっと読む)
グラフ統合装置及びそのプログラム
【課題】本発明は、複数の統合グラフを扱うことができ、演算量が少なく、簡易な構成のグラフ統合装置を提供することを目的とする。
【解決手段】グラフ統合装置1は、入力要素を示すノードとノード間において分岐及び合流が可能な示すエッジとで構成された入力グラフGが複数入力され、入力グラフGを統合するものであって、グラフ入力手段11と、入力グラフ記憶手段12と、DPマッチング法によって、入力グラフGの類似度を算出する類似度算出手段13と、類似度に基づいて、入力グラフGが類似するか否かを判定する類似判定手段14と、入力グラフGが類似する場合、入力グラフGを統合するグラフ統合手段15と、入力グラフGが類似しない場合、入力グラフGを新たな統合グラフとして追加するグラフ追加手段16と、統合グラフ記憶手段17と、を備える。
(もっと読む)
21 - 30 / 119
[ Back to top ]