
国際特許分類[G10L15/08]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 音声認識 (6,879) | 音声の識別または探索 (1,500)
国際特許分類[G10L15/08]の下位に属する分類
未知音声と標準パタンとの距離または歪みを用いるもの (838)
動的計画法を用いるもの,例.動的時間伸縮[DTW] (22)
統計的モデルを用いるもの,例.隠れマルコフモデル[HMM] (175)
ニューラル・ネットワークを用いるもの (24)
自然言語モデルを用いるもの (322)
国際特許分類[G10L15/08]に分類される特許
31 - 40 / 119
音声認識装置、音声認識方法及びコンピュータプログラム
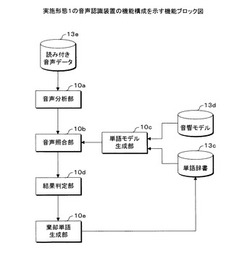
【課題】音声認識処理の精度を向上させる音声認識装置、音声認識方法及びコンピュータプログラムを提供する。
【解決手段】単語辞書13cに登録してある認識単語に棄却単語を付与する場合、音声分析部10aは、複数の棄却単語候補のそれぞれに対する複数の音声データのそれぞれから特徴パラメータを抽出する。音声照合部10bは、音声分析部10aによって抽出された特徴パラメータと、単語モデル生成部10cによって生成された各認識単語の単語モデルとの尤度を算出する。結果判定部10dは、各特徴パラメータに対して、尤度が最も高い単語モデルを認識結果とする。棄却単語生成部10eは、各特徴パラメータに対する認識結果に基づいて、棄却単語候補毎に、棄却単語を登録したい認識単語が認識結果であった発声数を計数し、計数した発声数が最も多い棄却単語候補を、前記認識単語に対応する棄却単語として単語辞書13cに登録する。
(もっと読む)
音声認識装置及びこれを用いる車両システム

【課題】応答性の要求に応じつつ、精度の良い認識結果を出力することができる音声認識装置の提供。
【解決手段】本発明は、認識精度の異なる複数の音声認識手段を備える音声認識装置であって、入力音声に対して前記複数の音声認識手段を並列に動作させ、前記複数の音声認識手段のそれぞれの認識結果を、それぞれの認識結果が得られ次第、ディスプレイに順次出力することを特徴とする。
(もっと読む)
車載情報システム
【課題】
個々のユーザの発話の特徴を学習することにより、音声認識精度の向上を図った車載情報システムを提供することを課題とする。
【解決手段】
手動操作により指令を入力する第1入力手段と、音声を入力する第2入力手段と、前記第2入力手段に入力される音声を音声認識する音声認識手段と、前記第1入力手段に入力される指令の内容、又は前記音声認識手段によって音声認識される音声の意味内容に基づき、所定の情報を出力する情報処理手段と、前記第2入力手段に音声が入力された後の所定時間内に前記第1入力手段へ指令が入力されると、当該指令の内容を表すデータと、前記第2入力手段に入力される音声を表す音声データとに基づき、前記音声認識手段における認識手法を学習する学習手段とを含む。
(もっと読む)
音声認識方法および装置ならびに音声認識プログラムおよびその記録媒体
【課題】前向き探索および後向き探索を含む複数の探索を独立に実行し、各探索により得られた認識結果を正当に評価することにより、文法に記述できない物音や音声が文頭や文末に混入する場合でも、確度の高い認識結果を得られるようにした音声認識方法および装置ならびに音声認識プログラムおよびその記録媒体を提供する。
【解決手段】前向き探索では、音声データの最終フレームまで到達していない状態仮説Eに関して、その累積尤度Sf9と、後向き探索で得られた最大累積尤度Mr14との加算値をフレーム数T(=23)で除した値(Sf9+Mr14)/Tがフレーム平均尤度となる。後向き探索では、音声データの先頭フレームまで到達していない状態仮説Gに関して、その累積尤度Sr14と、前向き探索で得られた最大累積尤度Mf9との加算値をフレーム数T(=23)で除した値(Sr14+Mr9)/Tがフレーム平均尤度となる。
(もっと読む)
話者認識システム及びコンピュータプログラム
【課題】話者認識システムにより、例えば話者認識における成りすまし或いは詐称を好適に回避し或いは予防する。
【解決手段】話者認識システム(1)は、話者認識を行う認識手段(132、14)と、認識手段において一のユーザに係る話者認識が所定回数に亘って連続して失敗したか否かを検知する検知手段(60)とを備える。更に、該検知手段により話者認識が所定回数に亘って連続して失敗したことが検知された場合に、話者認識が失敗した旨を示す失敗情報を、一のユーザに対して通報する通報手段(70)を備える。
(もっと読む)
パタン認識方法および装置ならびにパタン認識プログラムおよびその記録媒体
【課題】認識率を低下させることなく状態仮説を効率良く枝刈りして状態仮説数を削減できるパタン認識方法および装置ならびにパタン認識プログラムおよびその記録媒体を提供する。
【解決手段】探索部15の枝刈り部154は、状態遷移モデルの探索空間を複数の領域に分割する領域分割部154aと、同一時刻で遷移する状態仮説を前記分割された領域のいずれかに振り分ける状態仮説振り分け部154bと、前記分割された各領域の枝刈り条件を設定する枝刈り条件設定部154cと、前記分割された領域ごとに、同一領域内で尤度の低い状態仮説を探索対象から除外する領域別枝刈り部154dとを含む。
(もっと読む)
音声認識装置、音声認識方法、音声認識プログラム、及び音声認識プログラムを記録した記録媒体
【課題】雑音が支配的になっている期間を音源定位過程で検出し、音声認識過程でこの期間の処理をうまく調整できるようにする。
【解決手段】 2地点で捉えられた第1と第2の音響信号から周波数成分毎の位相差とパワーとを算出し、周波数成分毎の周波数と位相差とを座標値とする散布図を生成する。該散布図上で所定の直線性を示す周波数成分の配置を、周波数成分のパワーに応じた直線スコアとともに検出し、該直線スコアが所定の閾値以上を得た配置を音源の存在を示す直線として検出する。このような直線の情報及び直線スコア等より成る音源ストリームを抽出し、音源ストリームの時刻毎の直線スコアの高低に基づいて該音源ストリームの各時刻に対して信頼可否情報を付与する。
(もっと読む)
音声認識装置
【課題】音響的に似通った認識対象単語において、誤認識の誘発を防止できる音声認識装置を提供する。
【解決手段】音声認識装置であって、単語データを記憶する記憶部と、記憶部を参照して、ユーザが発話した音声の表す単語データを認識する認識部と、認識部が認識した単語データの少なくともモーラ数、音素数、又は発話時間が所定値より小さいか否かを判定することによって、当該単語データを修正した修正単語データを出力するか否かを判定する修正判定部と、修正判定部が修正単語データを出力すると判定した場合、認識部が認識した単語データに、所定のモーラ数、音素数、又は発話時間のデータを付加して作成した修正単語データを出力する単語データ修正部とを備える。
(もっと読む)
音声対話装置
【課題】ユーザの発話音声を音声認識手段が誤認識する可能性を、ユーザの発話中に報知できる音声対話装置を提供することにある。
【解決手段】
本発明の音声対話装置は、ユーザの発話音声を認識する音声認識部151の音声認識結果に基づいて、所定のタスクを達成する制御部152を有する信号処理装置15およびユーザの発話音声を音声認識部151が誤認識する可能性を判断する誤認識可能性判断部141と、ユーザの発話中に、上記誤認識する可能性をユーザに報知するフィードバック部142とを有する信号処理装置14を備える。
(もっと読む)
音声認識装置および音声認識方法
【課題】車載装置の発話制御において、重畳された音声に基づく認識結果である複数の制御コマンドを効率的に実行するために、より高い精度で音声認識する。
【解決手段】本発明の音声認識装置10は、音源分離・音源方向推定処理部11aが、重畳されて集音された音声から音源ごとに音声を分離し、各音声の音源方向を推定する。音源方向推定の信頼度が所定閾値以下であった場合に、運転席用音声認識・操作コマンド変換処理部11b、助手席用音声認識・操作コマンド変換処理部11c、後部座席用音声認識・操作コマンド変換処理部11dが、すべての音源方向に対応する音声認識用辞書を使用して音声認識をおこない、音声認識の信頼度をそれぞれ算出する。操作コマンド変換結果補正処理部11eは、音源方向の信頼度および音声認識の信頼度の積に基づいて、推定された音源方向を補正する。
(もっと読む)
31 - 40 / 119
[ Back to top ]