
国際特許分類[G10L17/00]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 話者の同定または識別 (337)
国際特許分類[G10L17/00]に分類される特許
21 - 30 / 337
情報処理装置
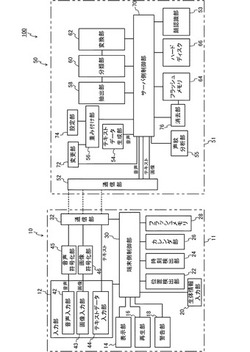
【課題】セキュリティが考慮された、使い勝手の良い情報処理装置を提供する。
【解決手段】画像を入力する第1入力装置(52)と、位置情報と時刻情報との少なくとも一方の情報を入力する第2入力装置(52)と、前記画像の出力指示があったときに、前記第2入力装置(52)が入力した情報に基づいて前記画像の出力に制限を加えるか否かを判断する判断装置(70)と、を備える情報処理装置(50)である。
(もっと読む)
メッセージ映像編集プログラムおよびメッセージ映像編集装置

【課題】ユーザが入力するメッセージテキストに合致する音声を再現した任意のメッセージ映像データの作成を容易に実現する。
【解決手段】映像データに付随し時刻毎に分割された音声データの発声内容を示すと共に前記映像データと前記発声内容とを対応付ける対応情報を格納する素材情報データベース17と、ユーザにより入力されたテキストデータを構成する最小単位のテキストデータにそれぞれ対応する発声内容の音声データおよび前記音声データに対応付けられた映像データを、対応情報に基づいて元映像データベース3から抽出する素材選択部23と、前記抽出した音声データおよび映像データを前記テキストデータの並び順に連結して音声データが付随した映像データの候補を提示する候補提示部25と、を備える。
(もっと読む)
音声をテキストに変換する装置及び方法
【課題】音声をテキストに変換する装置及び方法を提供することを目的とする。
【解決手段】音声受信モジュール、音声識別モジュール、表示モジュール、格納モジュール、話者識別モジュール及び制御モジュールを備え、格納モジュールは異なる音声データに対応するテキストデータ及び異なる音声信号に対応する話者データを格納し、音声受信モジュールは、外部の音声信号を受け取り、音声識別モジュールは、前記音声信号を音声データに変換してから、格納モジュールから前記音声データに対応するテキストデータを探して制御モジュールに送信し、話者識別モジュールは、格納モジュールから前記音声信号に対応する話者データを探して制御モジュールに送信し、制御モジュールは、前記テキストデータ及び前記話者データを表示モジュールに表示させる。
(もっと読む)
車載装置
【課題】車両に運転者以外の者が乗車している場合であっても、そのときの乗員構成に最適なサービスを提供する。
【解決手段】車載装置10の制御装置11は、車載マイク12により、車内に発生した音声を収集し、シートセンサ19により、着座位置を特定し、発話者推定部31により、音声および着座位置に基づいて発話者を推定し、会話内容推定部32により、音声に基づいて会話内容を推定し、乗員構成推定部33により、着座位置、発話者および会話内容に基づいて乗員構成を推定し、行動目的推定部34により、会話内容および乗員構成に基づいて行動目的を推定し、レコメンドサービス決定部35により、乗員構成および行動目的に基づいて推奨するサービスを決定する。
(もっと読む)
パターン分類装置の学習装置及びそのためのコンピュータプログラム
【課題】ベイズ誤り推定と直結した損失関数を用い,高い認識率が得られるようなパターン分類装置のための学習装置を提供する.
【解決手段】学習装置42は,学習パターン集合を記憶する記憶装置64と,各クラスに対し定義される判別関数を,学習パターンにより学習する学習装置66とを含む.判別関数は,入力パターンと,複数個のプロトタイプとの間のカーネル演算の線形和により表される.カーネルは,入力パターンの空間より高次元の空間に入力パターンを変換する特徴変換を定めたときに,変換後の入力パターンと,変換後のプロトタイプとの間の内積により定義され,プロトタイプ相互間でのカーネル演算により構成されるグラム行列が正定値行列となる.学習装置は,高次元空間において学習パターンと係数ベクトル集合との関数として定義される平均分類誤り数損失が最小となるよう係数ベクトルを調整する.
(もっと読む)
情報処理装置およびその動作方法
【課題】 予め動画像の撮影者の声を登録することなく、動画像の撮影者の声を決定する。
【解決手段】 本発明に係る情報処理装置は、複数の音声区間に対応する音声を表す第1のデータストリームから、該音声に対応する動画像の撮影者の声を決定する情報処理装置であって、前記第1のデータストリームと、複数の画像からなる前記動画像を表す第2のデータストリームとを取得し、前記複数の画像のうち、人物を示すオブジェクトが含まれない画像を特定し、特定された画像に対応する前記音声区間のうち、声に相当する区間における音に基づいて、前記動画像の撮影者の声を決定する。
(もっと読む)
消費者電化製品に関連する装置をボイス制御する方法及び装置
【課題】 本発明は、ボイス制御する方法を特定することを目的とする。
【解決手段】 消費者電化製品に関連する装置のボイス制御において、ユーザの音声入力はディジタル化されたボイス信号に変換される。音声の個々の音の特性であり、従って口頭の音の認識を可能にする第1の特徴は、ディジタル化されたボイス信号から抽出される。更に、夫々のユーザの声の特性把握を可能にし、異なるユーザの音声入力間で区別するために使用される第2の特徴がディジタル化された音声信号から抽出される。これは、オペレータ制御コマンドを表わす、現在のユーザの音声入力と他の人による発声との間で区別し、現在のユーザのオペレータ制御コマンドにだけ応答するよう、装置が作動されることを可能にさせる。更に、異なるユーザの視聴傾向の分析の質はユーザ間の区別によって改善され得る。
(もっと読む)
声紋による話者特定機能を有する電話装置
【課題】
外部から入力する音声信号のうち、特定の言葉に限定された音声信号から声紋データを抽出するようにして、声紋データの比較処理が軽い、声紋による話者特定機能を有する電話装置を提供する。
【解決手段】
話者の声紋データと、話者のプロファイルに係る情報を対応付けて登録する話者データ登録部130と、話者毎の処理内容を登録する話者別処理内容登録部150と、前記プロファイルに係る質問を音声で相手へ質問する音声質問部120と、質問に対する回答音声から相手の声紋データを抽出する声紋データ抽出部140と、前記抽出した声紋データにより相手の話者を特定する話者特定手段とを有し、特定した話者に対応する処理内容を自動的に起動する。
(もっと読む)
歌唱音声評価装置
【課題】歌唱音声を解析して声質を判定するだけでなく、声質を切り替える技法で歌唱されているかどうかを判定すること。
【解決手段】本発明の実施形態におけるカラオケ装置は、歌唱音声を取得する取得手段と、歌唱音声をフレームごとに周波数スペクトルに変換する変換手段と、各フレームの周波数スペクトルにおけるピーク値とディップ値との比に応じた歌唱SN比を算出する算出手段と、歌唱SN比の分布に応じて、歌唱音声が第1の声質もしくは第2の声質で歌唱された音声、または特定の技法により歌唱された音声であると判定する判定手段と、判定結果に応じた情報を出力する出力手段とを具備する。
(もっと読む)
音声認識装置及び音声認識方法
【課題】会話のような比較的長い音声データから特定のキーワードを認識する精度を向上できる音声認識装置を提供する。
【解決手段】音声認識装置1は、音声データの一部が分類される複数の区分の何れかに対応する複数の単語辞書を記憶する記憶部3と、処理部4とを有する。処理部4は、音声データから複数の会話区間を検出する会話区間検出機能11と、音声データから複数の発声区間を検出する発声区間検出機能12と、複数の発声区間のそれぞれを、複数の会話区間のうちのその発声区間が属する会話区間の順序に応じて複数の区分の何れかに分類する区間分類機能13と、少なくとも一つの発声区間について、複数の単語辞書のうち、発声区間が分類された区分に対応する単語辞書を記憶部から取得する単語辞書選択機能14と、発声区間の少なくとも一つから、その発声区間について取得された単語辞書を用いて特定のキーワードを検出する検出機能15とを実現する。
(もっと読む)
21 - 30 / 337
[ Back to top ]