
国際特許分類[G10L17/00]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 話者の同定または識別 (337)
国際特許分類[G10L17/00]に分類される特許
1 - 10 / 337
自動利得制御
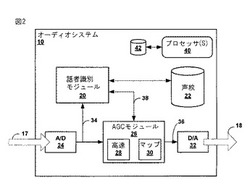
【課題】複数話者オーディオにおけるオーディオ利得レベルを調整するための技術に関する。
【解決手段】1つの例として、オーディオシステムは、新たな話者の存在に対して、オーディオストリームを監視する。新たな話者を識別すると、システムは、新たな話者が初めての話者かどうかを決定する。初めての話者に対して、システムは、初めての話者に対する利得値を迅速に決定するため、高速アタック/ディケイ自動利得制御(AGC)を実行する。更に、初めての話者が会話中、初めての話者に対する利得を改善するため、標準AGC技術を実行する。初めての話者に対し、標準AGCを用いて、デシベルしきい値内の安定状態が達成されると、システムは、初めての話者に対する安定状態利得を記憶部に格納する。以前に識別された話者を識別すると、システムは、話者に対する安定状態利得を記憶部から読み出し、オーディオストリームに適用する。
(もっと読む)
情報処理装置、および情報処理方法、並びにプログラム

【課題】不確実で非同期な入力情報に基づく情報解析により、ユーザ位置や識別情報、発話者情報などを生成する構成を実現する。
【解決手段】画像情報や音声情報に基づいてユーザの推定位置および推定識別データを含むイベント情報を入力し、入力イベント情報に基づいて、各ユーザの位置およびユーザ識別情報を含むターゲット情報と、イベント発生源の確率値を示すシグナル情報を生成する情報統合処理部を有し、情報統合処理部は、発話源確率算出部を有し、発話源確率算出部は、各ターゲットの発話源確率を示す指標値としての発話源スコアを、イベント検出部から入力する複数の異なる情報に対して発話状況に応じた重みを乗算して算出する処理を行う。
(もっと読む)
位置出力装置、位置出力システムおよびプログラム
【課題】音声を発生する話者の三次元位置を、より良好に把握することができる位置出力装置等を提供する。
【解決手段】装着者の口からの距離が互いに異なる2つと水平方向の距離が離れた2つを含み話者の音声を取得する少なくとも3個以上設けられるマイクロフォン11a,11b,11cと、装着者の口からの距離が互いに異なる2つのマイクロフォン11a、マイクロフォン11cで取得される音声の音圧差に基づいて、話者が装着者か他者かを識別する識別手段と、識別手段によって話者が他者と識別された場合に、話者の三次元位置を導出するための数値計算の初期値を選択する初期値選択手段と、初期値選択手段により選択された初期値を用いた数値計算により話者の三次元位置を導出する位置導出手段と、を備えることを特徴とする端末装置10。
(もっと読む)
音声解析装置および音声解析システム
【課題】音声取得手段にて音声を取得し、取得した音声の非言語情報に基づいて話者を識別する。
【解決手段】端末装置は、使用者の口からの距離が相異なる位置となるように使用者に装着される第1マイクロフォン11および第2マイクロフォン12と、第1マイクロフォン11により取得された音声の音声信号と第2マイクロフォン12により取得された音声の音声信号との比較結果に基づき、第1マイクロフォン11および第2マイクロフォン12により取得された音声が第1マイクロフォン11および第2マイクロフォン12を装着した使用者の発話音声か、使用者以外の他者の発話音声かを識別する音声解析部と、を備える。ホスト装置は、複数の端末装置から発話者の識別結果を含む発話情報を取得して解析し、発話者間のコミュニケーションの傾向を表す情報を出力する。
(もっと読む)
会議データの統合管理方法および装置
【課題】会議参加者のそれぞれの発言やその文書化データの管理を容易にし、会議データの利便性を向上させることが可能な統合管理方法および装置を提供する。
【解決手段】会議の参加者ごとに対応づけられた個別の音声チャネルに複数の参加者の発言を時間情報と共にそれぞれ格納したチャネル別音声データ格納部(207、208)と、音声チャネルごとに音声データの再生機能および音声データの時系列表示機能を含む複数機能から任意の機能を選択実行できる会議データ画面を操作可能に表示する制御部(201、212、213)と、を有する。
(もっと読む)
音声解析装置
【課題】使用者に装着された音声取得手段にて音声を取得し、取得した音声の非言語情報に基づいて、使用者の顔の向きを検知する。
【解決手段】端末装置10は、使用者の口を挟んで対称な位置となるように装着される第2マイクロフォン11bおよび第3マイクロフォン11cと、これらとは使用者の口からの距離が異なる位置となるように装着される第1マイクロフォン11aと、第1マイクロフォン11aにより取得された音声の音声信号と第2マイクロフォン11bにより取得された音声の音声信号との比較結果に基づき、取得された音声が使用者の発話音声か、使用者以外の他者の発話音声かを識別し、使用者の顔の向きを検知する音声解析部と、を備える。
(もっと読む)
音声認識装置、音声認識方法およびプログラム
【課題】音声認識の精度を向上させる。
【解決手段】音声認識装置は、番組情報記憶部と、辞書記憶部と、算出部と、更新部と、認識部と、操作制御部とを備える。番組情報記憶部は、放送番組のメタデータとユーザの視聴状態とを記憶する。辞書記憶部は、音声認識の対象となる認識語と優先度とを含む認識辞書を記憶する。算出部は、メタデータと視聴状態とに基づいて、放送番組の特徴語と特徴語に対するユーザの嗜好の度合いを表す第1スコアとを算出する。更新部は、特徴語を含む認識語の優先度を第1スコアに応じて更新する。認識部は、認識辞書を用いて音声を認識する。操作制御部は、認識結果に基づいて放送番組に対する操作を制御する。
(もっと読む)
話者識別検証のための方法およびシステム
【課題】対象が話された音声の発生源であることおよびその話された音声を提供する対象の識別を確認するためのシステムを提供する。
【解決手段】システムは、音声の生成に寄与する少なくとも1つの調音器官の物理的動きをキャプチャするように動作可能な少なくとも1つの動きセンサと、音響信号を受信するための少なくとも1つの音響信号センサと、メモリを備え少なくとも1つの動きセンサおよび少なくとも1つの音響信号センサに通信可能に結合された処理デバイスとを含む。処理デバイスは、物理的動きデータを音響信号データと相関させるようにプログラムされ、対象が音響信号データの発生源であることおよび対象の識別を検証する目的で対象を一意に特徴づける。
(もっと読む)
話者クラスタリング方法、話者クラスタリング装置、プログラム
【課題】同一クラスタ内の話者間の知覚的類似度を高くできる話者クラスタリング方法を提供する。
【解決手段】N名の話者による同一内容の発話の音声データのうちk番目とj番目(1≦k,j≦N)の話者の発話の音声データの知覚的類似度の主観評価値をj番目の要素として有する話者ベクトルを生成する話者ベクトル生成サブステップと、話者ベクトルのベクトル間距離に基づいて、N名の話者をクラスタ数Mにクラスタリングするクラスタリングサブステップと、話者の属するクラスタ毎に当該話者の発話の音声データから選択用モデルを学習する選択用モデル学習サブステップと、任意の話者の音声データを入力とし当該入力された任意の話者の音声データと各クラスタの選択用モデルとの尤度を計算する尤度計算サブステップと、計算された尤度が最も高いクラスタを入力された音声データの話者が属するクラスタとして選択するクラスタ選択サブステップとを有する。
(もっと読む)
情報処理装置、ダイジェスト生成方法、及びダイジェスト生成プログラム
【課題】より適切なダイジェストを生成する。
【解決手段】情報処理装置において、所定時間撮影された1又は複数の被写体を含む映像情報及び音声情報を蓄積する蓄積部と、前記蓄積部に蓄積された映像情報及び音声情報を用いて、予め設定された1又は複数の要素に基づき、前記所定時間の時系列における所定の単位時間毎の変化量を評価し、評価された結果に基づいて1又は複数のダイジェスト候補を抽出するダイジェスト生成部と、を有し、前記ダイジェスト生成部は、前記ダイジェスト候補に対応する映像情報及び音声情報に含まれる被写体の状況又は特徴をパターン認識し、認識された結果に基づいて前記ダイジェスト候補からダイジェストを生成するパターン認識部を有する。
(もっと読む)
1 - 10 / 337
[ Back to top ]