
文書検索装置、文書検索方法および文書検索プログラム

【課題】不完全な経路式に基づいて構造化文書ファイル中から所望のデータを効率的に検索する。
【解決手段】構造化文書ファイルから所望のデータを検索するための文書検索装置に関する。この装置は、構造化文書ファイルにおいて階層的に上下関係にあるタグセットと、経路式の一部にそのタグセットを含む1以上の位置とを対応づけたインデックス情報を保持する。この装置は、部分経路式の入力を受け付けると、インデックス情報を参照して、部分経路式に含まれるタグセットが経路式の一部としてあらわれる位置を検索対象位置の候補位置として特定する。
【解決手段】構造化文書ファイルから所望のデータを検索するための文書検索装置に関する。この装置は、構造化文書ファイルにおいて階層的に上下関係にあるタグセットと、経路式の一部にそのタグセットを含む1以上の位置とを対応づけたインデックス情報を保持する。この装置は、部分経路式の入力を受け付けると、インデックス情報を参照して、部分経路式に含まれるタグセットが経路式の一部としてあらわれる位置を検索対象位置の候補位置として特定する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、文書処理技術に関し、特に、構造化文書ファイルを対象とした情報検索技術、に関する。
【背景技術】
【0002】
コンピュータの普及とネットワーク技術の進展にともない、ネットワークを介した電子情報の交換が盛んになっている。これにより、従来においては紙ベースで行われていた事務処理の多くが、ネットワークベースの処理に置き換えられつつある。デジタル化とネットワーク技術の進展は、情報取得コストを急激に低下させている。このような状況において、大量の文書ファイルの中から所望のデータを検索する技術の重要性が高まっている。
【特許文献1】特開2006−048536号公報
【発明の開示】
【発明が解決しようとする課題】
【0003】
ところで、近年では、多くの文書ファイルが、HTML(Hyper Text Markup Language)やXHTML(eXtensible HyperText Markup Language)、XML(eXtensible Markup Language)などによる構造化文書ファイルとして作成されるようになってきている。構造化文書ファイルはタグによって階層化されるため、文書中のデータをタグのパス表記によって指定できる。このように、構造化文書ファイルには、データの位置を特定しやすいという優れた特性がある。中でも、XMLは、ネットワークを介して他者とデータを共有するのに適した形式として注目されている。XML文書であれば、XPath(XML Path Language)に基づく構文であるXPath式によりデータを特定できる。
【0004】
XPathは、省略記号にも対応できる表記法となっている。たとえば、「/提案//集約処理」というXPath式は、「<提案>タグの下位の階層に<集約処理>タグが出現する全てのパス」という条件を意味する。以下、このようなタグの経路に関する条件のことを「経路条件」とよぶことにする。また、XPath式のように、タグの階層構造に基づいてタグのパスを示す構文のことを「経路式」とよぶことにする。上記経路条件に対しては、「/提案/集約処理」、「/提案/内容/集約処理」、「/提案/内容/基本処理/集約処理」として指定されるいずれの経路式も適合する。
一方「/提案/*/集約処理」というXPath式は、「<提案>タグから2階層下位の階層に<集約処理>タグが出現する全てのパス」という経路条件を意味する。上記した3つの経路式のうちでは「/提案/内容/集約処理」だけがこの経路条件に適合する。
【0005】
ユーザが省略記号のないXPath式を指定できれば、構造化文書ファイルから所望のデータを取り出すことができる。しかし、常に正確に経路式がわかるとは限らない。たとえば、検索対象となるデータが<提案>タグの下の<集約処理>タグにあることがわかっていても、<提案>タグと<集約処理>タグの間に、どのようなタグが何階層あるか、そもそも、どの文書に求めるデータがあるかわからないことがある。
上記したような省略記号を含む不完全な経路式が入力されたとき、その経路式によって示される経路条件に適合するデータを検索できれば便利である。以下、省略記号を含むなどの理由により、検索対象となるデータの位置を一意に特定するには不充分な経路式のことを「部分経路式」とよび、省略記号を含まない経路式のことを「完全経路式」とよぶ。
【0006】
部分経路式に基づくデータ検索方法として、構造化文書ファイルのタグ構造を解析し、タグの経路情報をメモリに展開した上で、経路条件に適合する位置のデータを検出するという方法が一般的である。しかし、このような方法は、メモリの使用量が大きく、処理時間も長くなるという問題点がある。特に、多数の構造化文書ファイルや、タグの階層構造が複雑な構造化文書ファイルの中から所望のデータを探す場合には、このような問題点が顕在化しやすい。
【0007】
本発明はこうした状況に鑑みてなされたものであり、その目的は、不完全な経路式に基づいて構造化文書ファイル中から所望のデータを効率的に検索するための技術、を提供することある。
【課題を解決するための手段】
【0008】
本発明のある態様は、構造化文書ファイルから所望のデータを検索するための文書検索装置に関する。
この装置は、構造化文書ファイルにおいて階層的に上下関係にあるタグセットと、経路式の一部にそのタグセットを含む1以上の位置とを対応づけたインデックス情報を保持する。この装置は、部分経路式の入力を受け付けると、インデックス情報を参照して、部分経路式に含まれるタグセットが経路式の一部としてあらわれる位置を検索対象位置の候補位置として特定する。
【0009】
インデックス情報としてタグセットごとの位置を登録しておくことにより、検索実行時に文書ファイルにアクセスしてタグの階層構造を精査しなくても、検索対象となるデータを特定できる。このため、不完全な部分経路式が入力されたときにも、検索対象となるデータを効率的に検出できる。
【0010】
なお、以上の構成要素の任意の組み合わせ、本発明の表現を方法、システム、プログラム、記録媒体などの間で変換したものもまた、本発明の態様として有効である。
【発明の効果】
【0011】
本発明によれば、不完全な経路式に基づいて構造化文書ファイル中から所望のデータを効率的に検索することができる。
【発明を実施するための最良の形態】
【0012】
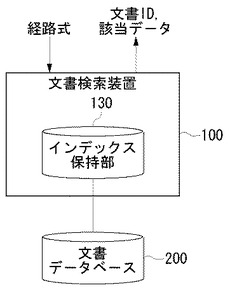
図1は、文書検索装置100による処理の概要を説明するための模式図である。
ユーザが文書検索装置100に対して経路式を入力すると、文書検索装置100は経路式に適合するデータを文書データベース200から検索する。文書データベース200の文書ファイルは、XML文書やXHTML文書のようにタグによって構造化された構造化文書ファイルである。本実施例においては、検索対象となる文書ファイルはXMLファイルであるとして説明する。
【0013】
文書検索装置100のインデックス保持部130は、各文書ファイルを検索するためのインデックス情報を保持する。インデックス情報は、完全経路インデックス214と部分経路インデックス230の2種類があるが、それぞれについては図3から図5に関連して後に詳述する。文書検索装置100は、入力された経路式とインデックス情報に基づいて、文書データベース200から検索対象となるデータがどの文書のどの位置にあるかを検索する。文書検索装置100は、検出された文書ファイルの文書IDと、その文書ファイルにおける検索対象データとを画面表示させる。こうして、文書検索装置100のユーザは、任意の経路式に対して、検索対象データ、または、検索対象データの候補を文書データベース200から探し出す。
【0014】
図2は、本実施例におけるXML文書210を示す図である。
同図に示すXML文書210を対象として本実施例を説明する。文書データベース200の各文書ファイルには文書IDが付与される。同図に示すXML文書210の文書IDは「1」であるとする。文書IDとは、文書データベース200において文書ファイルを一意に識別するためのIDである。このXML文書210は、アイディア提案書に関するXML文書であり、<提案>や<発案者>など複数のタグを含む。文書位置欄212は、XML文書210に含まれるさまざまなデータの位置を示す。たとえば、<提案>タグのこの文書における文書位置は「1」であり、</集約処理>タグの文書位置は「16」である。また、<発案者>タグの内容データである文字列”竹内真教”の文書位置は「3」である。文書位置は、タグ、属性、コメント、タグの内容となるデータごとに割り当てられ、文書ごとに一意の値となる。
以下においては説明を簡単にするため、タグに対する文書位置を中心として説明する。
【0015】
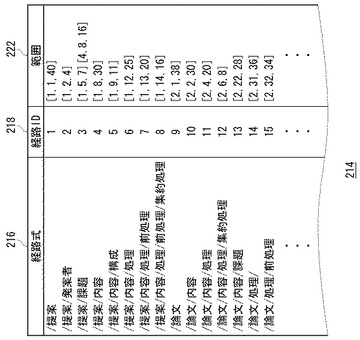
図3は、完全経路インデックス214のデータ構造図である。
完全経路インデックス214は、インデックス保持部130に格納される。経路欄216は、文書データベース200に含まれる経路式の一覧である。経路欄216には図2に示した文書ID=1の文書に含まれる経路式だけでなく、その他の文書に含まれる経路式も含まれる。経路ID欄218は、経路欄216に示す経路の経路IDを示す。経路IDは、経路式を示す文字列を所定規則により変換した数値列である。ハッシュ関数により変換してもよいし、所定のテーブルによって変換してもよいが、いずれにしても、各経路式が実用上差し支えない程度に一意に識別される値であればよい。
【0016】
同図において、経路式「/提案」のXML文書210における経路ID=1となっている。経路式「/提案/発案者」の場合、経路ID=2である。同様に、「/提案/内容/処理/前処理/集約処理」については経路ID=8となる。
【0017】
範囲欄222は、経路式によって示されるデータ範囲を[文書ID、開始位置、終了位置]の形式により範囲を示す。図2に示したXML文書210の場合、<集約処理>タグの文書位置は「14」であり、</集約処理>タグの文書位置「16」であるから、「/提案/内容/処理/前処理/集約処理」のデータは、文書ID=1の文書において文書位置=(14、16)の範囲のデータである。したがって、範囲欄222に示される範囲データは、[1、14、16]となる。
【0018】
同様に、経路式「/論文/内容/課題」の範囲データは[2、22、28]である。これは文書ID=2の文書において、文書位置=(22、28)の範囲のデータがこの経路式によって特定されるデータの範囲であることを示す。経路式「/提案/課題」の範囲データは[1、5、7]と[4、8、16]の2つである。これは文書ID=1と文書ID=4の2つのXML文書のどちらにも経路式「/提案/課題」という経路式が含まれることを意味する。
【0019】
完全経路インデックス214において経路式として表されるノードは<発案者>のようなタグに限られない。たとえば、図2の<発案者>タグの要素データである文字列”竹内真教”についても経路式として登録できる。この場合、経路式は「/提案/発案者/”竹内真教”」、経路ID=2014、範囲[1、3、3]となる。経路ID=2014は、「/提案/発案者/”竹内真教”」という文字列を所定規則に基づいて変換することにより得られる数値である。
【0020】
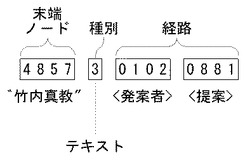
図4は、図3の経路欄216の詳細を示すデータ構造図である。
経路欄216には、実際には経路式を示す文字列がそのまま格納されるのではなく、経路式を数値表現したデータ(以下、特に区別するときには「数値経路式」とよぶ)が格納される。数値経路式は、実際の経路とは逆順に経路を示す。
【0021】
先述した経路式「/提案/発案者/”竹内真教”」を例として説明する。
数値経路式においては、まず、末端ノードである文字列”竹内真教”を示す4バイトの数値「4857」が先頭にくる。「4857」は所定の変換規則により文字列”竹内真教”を変換することにより得られる数値である。
次の1バイトは、末端ノードの種別を示す。種別は、要素:1、属性:2、テキスト:3、処理命令(PI:Processing Instruction):7、コメント:8のいずれかである。文字列”竹内真教”は、「/提案/発案者/」の内容を示すテキストなので、種別は「3」となる。
次に、<発案者>を示す4バイトの数値「0102」が続く。「0102」も所定の変換規則により文字列”発案者”を変換することにより得られる数値である。<提案>を示す数値は「0881」となる。数値経路式に含まれる各数値は、経路式の構成要素となる「提案」や「竹内真教」などの文字列を一意に識別できる数値であればよい。
以上により、「/提案/発案者/”竹内真教”」という経路式は、経路欄216においては「4857301020881」という13バイトの数値経路式として表される。
【0022】
A:完全経路式が入力された場合
完全経路式として「/提案/内容/処理/前処理/集約処理」が入力されたとする。文書検索装置100は、まず、この完全経路式を上述した方法により、数値経路式に変換する。この数値経路式と完全経路インデックス214の経路欄216における数値経路式を比較することにより、経路ID=8、範囲データ[1、14、16]を検出する。数値経路式同士のマッチングにより検出するため、文字列表現の経路式を比較するよりも高速な検索処理が可能である。
【0023】
B:部分経路式が入力される場合
部分経路式として「//構成」が入力されたとする。完全な経路がわからないので、文書検索装置100は、末端ノードの「構成」を数値表現に変換する。このとき、文書検索装置100は、「構成」を示す4バイトの数値と経路欄216の数値経路式の先頭4バイトを比較することにより、経路ID=5、範囲データ[1、9、11]を検出する。部分経路式においては、末端ノードがわかるがその上位ノードがわからないことが多い。本来の経路式の逆順となるように数値経路式を構成することにより、部分経路式の末端ノードだけである程度、検索対象データの候補を絞り込むことができる。
【0024】
ただし、「//内容/処理/*/集約処理」や「//内容/処理//集約処理」、「//内容/処理/*」のような部分経路式が与えられた場合、完全経路インデックス214から検索対象データを特定するためのアルゴリズムは複雑になる。タグの階層が深くなるといっそう処理は複雑化する。そこで、本実施例においては、完全経路インデックス214に加えて部分経路インデックス230により、検索対象データが存在する可能性がある位置(以下、「候補位置」とよぶ)を効率的に絞り込むための処理を実行している。
【0025】
図5は、部分経路インデックス230のデータ構造図である。
インデックス保持部130は、完全経路インデックス214に加えて部分経路インデックス230も格納している。キー欄226は、部分経路インデックス230において検索のキー(Key)となる2つのタグ(以下、「キータグセット」とよぶ)か、1つのタグ(以下、「キータグ」とよぶ)を示す。キータグセットとキータグを併せていうときには単に「キー」とよぶ。キータグセットとは、文書中のタグの階層として直接の上下関係にあるタグの組み合わせを示す。たとえば、XML文書210では<構成>タグの直接の親タグは<内容>なので、「内容/構成」はキータグセットとなる。しかし、<提案>タグや<課題>タグは<構成>タグの直接の親タグではないので「提案/構成」や「課題/構成」はキータグセットとはならない。これに対し、文書に含まれる全てのタグがキータグとなることができる。部分経路インデックス230は、文書データベース200に含まれる全ての文書に含まれるキーを対象としたデータである。
【0026】
位置インデックス欄228は、キーの出現する位置を[経路ID、出現階層]の形式で示す。このような形式の位置データのことを「位置インデックス」とよぶ。「内容/処理」というキータグセットは「/提案/内容/処理」という文書ID=1のXML文書210の第2階層からあらわれる。ルートノードを0階層とし、第1階層をルートノード直下の階層として数えている。以下、文書ID=n(nは自然数)のXML文書のことを文書(ID:n)のように表記することにする。位置インデックスには文書IDに関する情報が存在しないため、部分経路インデックス230だけでは、「内容/処理」が文書(ID:n)に存在することはわからない。
【0027】
経路式「/提案/内容/処理」の経路ID=6より、「内容/処理」の位置インデックスは[6、2]となる。同様にして、このキータグセットは「/提案/内容/処理/前処理」という文書(ID:1)、経路ID=7の経路式の第2階層にもあらわれる。このときの「内容/処理」の位置インデックスは[7、2]となる。
【0028】
先ほど例に挙げた「//内容/処理/*/集約処理」という部分経路式の場合、この部分経路式が示す経路条件は以下の通りである。
1.経路式に「内容/処理」、「集約処理」を含む。
2.「内容/処理」と「集約処理」の間には何らかの1階層がある、いいかえれば、<内容>から3階層下位に<集約処理>が出現する。
まず、部分経路式から、タグセット「内容/処理」、タグ「集約処理」を抽出する。
【0029】
キータグセット「内容/処理」の位置インデックスは、「6、2」、「7、2」、「8、2」、「11、2」、「12、2」の5つである。すなわち、キータグセット「内容/処理」を経路式に含む位置インデックスとして5箇所の候補が特定される。以下、このような候補となる位置インデックスのことを「候補位置」とよぶ。
キータグ「集約処理」の位置インデックスは、「8、5」、「12、4」の2つである。すなわち、キータグ「集約処理」に関する候補位置は2箇所である。
【0030】
ここで、「内容/処理」の位置インデックス「6、2」について、経路式ID=6であるが、「集約処理」の位置インデックスには経路ID=6となるものがない。これは、経路ID=6の経路式には、「集約処理」が含まれ得ないことを意味する。こうして、位置インデックス「6、2」は、上記経路条件から外れる。同様の理由から、「7、2」、「11、2」も候補から外れる。残るのは、「8、2」、「12、2」と「8、5」、「12、4」となる。
【0031】
「8、2」と「8、5」は、共に経路ID=8という経路式の一部を示し、「内容/処理」が第2階層、「集約処理」が第5階層にあらわれることを示している。すなわち、経路ID=8の経路式は「/*/内容/処理/*/集約処理」という経路式を含むことになるが、これは部分経路式に示された経路条件と整合している。完全経路インデックス214の経路ID=8のデータを参照することにより、範囲データ[1、14、16]を特定できる。すなわち、経路式「/提案/内容/処理/前処理/集約処理」が文書(ID:1)に特定される。
【0032】
一方、「12、2」と「12、4」は、共に、経路ID=12という経路式の一部を示し、「内容/処理」が第2階層、「集約処理」が第4階層にあらわれることを示している。すなわち、経路ID=12の「/*/内容/処理/集約処理」という経路式を含むことになるが、これは部分経路式に示された経路条件と整合していない。したがって、文書(ID:1)において、文書位置=(14、16)の範囲のデータだけが求めるデータである。
【0033】
同様にして、部分検索式「//内容/処理//集約処理」が与えられたときには、「内容/処理」と「集約処理」の間の階層数が不定なので、経路ID=8と12の両方の経路式が候補となる。部分検索式「//前処理//集約処理」が与えられたときには、タグ「前処理」について[7、4]、[8、4]、[15、3]が候補位置となり、キータグ「集約処理」について[8、5]、[12、4]となる。完全経路インデックス214も参照すると、文書ID=1、経路式ID=8の経路式のみが該当する。部分検索式「//提案/内容/*/前処理/集約処理」であれば、キータグセット「提案/内容」の位置インデックスとキータグセット「前処理/集約処理」についての位置インデックスと完全経路インデックス214から文書(ID:1)の経路ID=8の経路式が特定される。
このように、部分経路インデックス230によれば、不完全な部分検索式が入力されたときに文書データベース200のXML文書自体を経路解析する必要がなくなる。また、完全経路インデックス214の経路欄216から経路条件に整合する経路式を直接探すよりも、候補位置を効率的に絞り込むことができる。部分経路インデックス230を使った検索は、XML文書のタグ階層が深くなるときや検索対象となる文書数が多いときには特に有効な検索方法である。
【0034】
キー欄226のキーは、キーIDとよばれる所定長の数値列として格納される。キーIDは、キータグセットやキータグを一意に識別できる数値であればよい。キー欄226におけるキーを数値表現形式で格納することにより、キー名を示す文字列をそのまま格納するよりも検索処理をいっそう高速化することができる。キーIDも、キーを示す文字列を所定のハッシュ関数によって変換することにより生成してもよい。あるいは、キーとキーIDを一意に対応づける変換テーブルにより、互いを対応づけてもよい。
【0035】
図6は、文書検索装置100の機能ブロック図である。
ここに示す各ブロックは、ハードウェア的には、コンピュータのCPUをはじめとする素子や機械装置で実現でき、ソフトウェア的にはコンピュータプログラム等によって実現されるが、ここでは、それらの連携によって実現される機能ブロックを描いている。したがって、これらの機能ブロックはハードウェア、ソフトウェアの組み合わせによっていろいろなかたちで実現できることは、当業者には理解されるところである。
【0036】
文書検索装置100は、ユーザインタフェース処理部110、データ処理部120およびインデックス保持部130を含む。
ユーザインタフェース処理部110は、ユーザからの入力処理やユーザに対する情報表示のようなユーザインタフェース全般に関する処理を担当する。本実施例においては、ユーザインタフェース処理部110により文書検索装置100のユーザインタフェースサービスが提供されるものとして説明する。別例として、ユーザはインターネットを介して文書検索装置100を操作してもよい。この場合、図示しない通信部が、ユーザ端末からの操作指示情報を受信し、またその操作指示に基づいて実行された処理結果情報をユーザ端末に送信することになる。
【0037】
データ処理部120は、ユーザインタフェース処理部110や文書データベース200から取得されたデータを元にして各種のデータ処理を実行する。データ処理部120は、ユーザインタフェース処理部110とインデックス保持部130の間のインタフェースの役割も果たす。
【0038】
ユーザインタフェース処理部110は、入力部112と表示部114を含む。入力部112は、ユーザからの入力操作を受け付ける。検索用の経路式は、入力部112を介して取得される。表示部114は、ユーザに対して各種情報を表示する。
【0039】
データ処理部120は、経路分解部122と検索部124、登録部126を含む。
経路分解部122は、部分経路式やXML文書の経路情報を解析する。部分抽出部128は、部分経路式やXML文書からタグやタグセットを抽出する。ID変換部132は、経路式やキーを数値表現に変換する。また、ID変換部132は、経路式から経路IDを生成する。登録部126は、新たなXML文書が文書データベース200に追加されるとき、その文書についてのデータを完全経路インデックス214と部分経路インデックス230に登録する。
【0040】
XML文書が文書データベース200に追加されるとき、ID変換部132は文書中の経路式を数値経路式に変換する。そして、登録部126が完全経路インデックス214に数値経路式とその範囲データを登録する。また、部分抽出部128は文書からキーを抽出し、ID変換部132がキーを数値表現形式のキーIDに変換する。登録部126は部分経路インデックス230に数値表現形式のキーIDと位置インデックスを登録する。文書データベース200のXML文書が編集、削除されたときにも、同様の処理方法により、完全経路インデックス214と部分経路インデックス230が更新される。
【0041】
検索部124は、入力された経路式に基づいて、文書および該当箇所を検出する。検索部124は、位置特定部134と範囲特定部136を含む。位置特定部134は、部分経路インデックス230を参照して、キーから位置インデックスを特定する。範囲特定部136は、経路式から範囲データを特定する。
部分経路式による検索に際しては、部分抽出部128が部分経路式からキーを抽出し、ID変換部132がキーを数値表現形式のキーIDに変換する。位置特定部134は、このキーIDに基づいて部分経路インデックス230から候補位置を特定する。範囲特定部136は、位置特定部134が特定した候補位置から、範囲データを特定する。結果は、表示部114により画面表示される。
【0042】
図7は、部分経路式に基づく検索処理の過程を示すフローチャートである。
まず、入力部112が部分経路式の入力を受け付ける(S10)。部分抽出部128は、部分検索式から1以上のキーとなるタグセットやタグを抽出する(S12)。ここでは、先ほどの「//内容/処理/*/集約処理」という部分検索式が入力され、キータグセット「内容/処理」とキータグ「集約処理」が抽出されたとする。抽出されたキーは、ID変換部132によってキーIDに変換される。位置特定部134は、部分経路インデックス230を参照して、キーIDから候補位置を特定する(S14)。キータグセット「内容/処理」の位置インデックスであれば、「6、2」、「7、2」、「8、2」、「11、2」、「12、2」の5つの位置インデックスが特定される。
【0043】
更に、別のキーが抽出されていれば(S16のN)、S14に戻って次のキーについての候補位置が特定される。先ほどの例の場合、キータグ「集約処理」について「8、5」、「12、4」の2つの位置インデックスが特定される。
【0044】
全てのキーについて候補位置が特定されると(S16のY)、位置特定部134は各キーについて特定された候補位置の間で整合する位置を特定する(S18)。こうして、候補位置の数が絞り込まれる。部分検索式「//内容/処理/*/集約処理」については、「8、2」と「8、5」のペアが特定される。範囲特定部136は、この位置インデックスに示される経路ID=8に基づいて、完全経路インデックス214から範囲データ[1、14、16]を特定する(S20)。表示部114は、文書(ID:1)の経路ID=8の経路式について該当データ、すなわち、文書位置14から文書位置16までのデータを画面表示させる(S22)。
【0045】
以上のアルゴリズムに基づいて、更に、複合的なデータ検索も可能である。たとえば、部分検索式「//発案者」と文字列「”竹内真教”」が入力されたとする。位置特定部134は、キータグ「発案者」について、部分経路インデックス230から位置インデックス「2、2」を特定する。完全経路インデックス214によると、「//発案者」に該当する範囲データは、文書(ID:1)、文書位置=(2、4)にある。経路式は「/提案/発案者」である。
【0046】
検索部124の図示しない文字列検索部は、文字列「”竹内真教”」について、完全経路インデックス214から該当する範囲データを検索する。範囲データとして[1、3、3]と特定されたとする。この場合、文字列「”竹内真教”」のデータの範囲は、「/提案/発案者」のデータの範囲におさまっている。検索部124は、部分検索式「//発案者」と文字列「”竹内真教”」のそれぞれについて特定された範囲データが整合したので、「/提案/発案者/”竹内真教”」を該当データとして特定する。
【0047】
なお、本実施例におけるキータグセットとは、階層的に直接の上下関係にある2つのタグの組み合わせであるとして説明したが、キータグセットはこのような条件に制約される必要はない。たとえば、階層的に直接の上下関係にある3つのタグの組み合わせであってもよい。もちろん、3個以上のタグの組み合わせをキータグセットとしてもよい。
【0048】
また、キータグセットに含まれるタグは、必ずしも直接の上下関係になくてもよい。たとえば、「/提案/内容/処理/前処理/集約処理」という経路式において、「内容-前処理」というタグの組み合わせではタグ間に2階層の差がある。また、「内容-集約処理」というタグの組み合わせであれば、階層差は3となる。部分経路インデックス230においては、キータグセットと、そのキータグセットを構成するタグ間の階層差が記録されてもよい。そして、位置特定部134は、部分経路式から抽出したタグセットの階層差と、キータグセットにおける階層差を参照して、候補位置を特定してもよい。
【0049】
本実施例ではXML文書を対象として説明したが、文書検索装置100は、XHTMLやHTML、SGMLなど、タグの階層構造に基づく経路式によってデータの位置が特定されるタイプの文書ファイルであれば、いずれを対象としても応用可能である。
【0050】
以上、本実施例に示す文書検索装置100によると、部分経路式に基づくデータ検索を効率的に実行できる。部分経路インデックス230に「キータグ」や「キータグセット」についての位置インデックスを登録しておくことにより、部分経路式に含まれるタグセットやタグに基づいて、候補位置を絞り込むことができる。そして、完全経路インデックス214により、より具体的にデータの位置を特定できる。検索時に文書ファイルを調べて、経路情報をメモリに展開する必要がないため、効率的な検索が可能となる。
【0051】
部分経路式によるデータ検索の処理負荷が大きくなると、部分経路式に基づくデータ検索がユーザにとって使いにくいものとなってしまう。本実施例に示した文書検索装置100は、完全経路インデックス214と部分経路インデックス230という2種類のインデックスデータを参照することにより、求めるデータの位置を高速かつ軽い計算機負荷にて特定できることになる。
【0052】
以上、本発明を実施の形態をもとに説明した。この実施の形態は例示であり、それらの各構成要素や各処理プロセスの組み合わせにいろいろな変形例が可能なこと、またそうした変形例も本発明の範囲にあることは当業者に理解されるところである。
【0053】
請求項に記載の「インデックス情報」は、本実施例における部分経路インデックス230により表現されている。請求項に記載の「タグセットID」は、本実施例においては、キータグセットについてのキーIDとして表現されている。
これら請求項に記載の各構成要件が果たすべき機能は、本実施例において示された各機能ブロックの単体もしくはそれらの連係によって実現されることも当業者には理解されるところである。
【図面の簡単な説明】
【0054】
【図1】文書検索装置による処理の概要を説明するための模式図である。
【図2】本実施例におけるXML文書を示す図である。
【図3】完全経路インデックスのデータ構造図である。
【図4】図3の経路欄の詳細を示すデータ構造図である。
【図5】部分経路インデックスのデータ構造図である。
【図6】文書検索装置の機能ブロック図である。
【図7】部分経路式に基づく検索処理の過程を示すフローチャートである。
【符号の説明】
【0055】
100 文書検索装置、 110 ユーザインタフェース処理部、 112 入力部、 114 表示部、 120 データ処理部、 122 経路分解部、 124 検索部、 126 登録部、 128 部分抽出部、 130 インデックス保持部、 132 ID変換部、 134 位置特定部、 136 範囲特定部、 200 文書データベース、 212 文書位置欄、 214 完全経路インデックス、 216 経路欄、 218 経路ID欄、 222 範囲欄、 226 キー欄、 228 位置インデックス欄、 230 部分経路インデックス。
【技術分野】
【0001】
本発明は、文書処理技術に関し、特に、構造化文書ファイルを対象とした情報検索技術、に関する。
【背景技術】
【0002】
コンピュータの普及とネットワーク技術の進展にともない、ネットワークを介した電子情報の交換が盛んになっている。これにより、従来においては紙ベースで行われていた事務処理の多くが、ネットワークベースの処理に置き換えられつつある。デジタル化とネットワーク技術の進展は、情報取得コストを急激に低下させている。このような状況において、大量の文書ファイルの中から所望のデータを検索する技術の重要性が高まっている。
【特許文献1】特開2006−048536号公報
【発明の開示】
【発明が解決しようとする課題】
【0003】
ところで、近年では、多くの文書ファイルが、HTML(Hyper Text Markup Language)やXHTML(eXtensible HyperText Markup Language)、XML(eXtensible Markup Language)などによる構造化文書ファイルとして作成されるようになってきている。構造化文書ファイルはタグによって階層化されるため、文書中のデータをタグのパス表記によって指定できる。このように、構造化文書ファイルには、データの位置を特定しやすいという優れた特性がある。中でも、XMLは、ネットワークを介して他者とデータを共有するのに適した形式として注目されている。XML文書であれば、XPath(XML Path Language)に基づく構文であるXPath式によりデータを特定できる。
【0004】
XPathは、省略記号にも対応できる表記法となっている。たとえば、「/提案//集約処理」というXPath式は、「<提案>タグの下位の階層に<集約処理>タグが出現する全てのパス」という条件を意味する。以下、このようなタグの経路に関する条件のことを「経路条件」とよぶことにする。また、XPath式のように、タグの階層構造に基づいてタグのパスを示す構文のことを「経路式」とよぶことにする。上記経路条件に対しては、「/提案/集約処理」、「/提案/内容/集約処理」、「/提案/内容/基本処理/集約処理」として指定されるいずれの経路式も適合する。
一方「/提案/*/集約処理」というXPath式は、「<提案>タグから2階層下位の階層に<集約処理>タグが出現する全てのパス」という経路条件を意味する。上記した3つの経路式のうちでは「/提案/内容/集約処理」だけがこの経路条件に適合する。
【0005】
ユーザが省略記号のないXPath式を指定できれば、構造化文書ファイルから所望のデータを取り出すことができる。しかし、常に正確に経路式がわかるとは限らない。たとえば、検索対象となるデータが<提案>タグの下の<集約処理>タグにあることがわかっていても、<提案>タグと<集約処理>タグの間に、どのようなタグが何階層あるか、そもそも、どの文書に求めるデータがあるかわからないことがある。
上記したような省略記号を含む不完全な経路式が入力されたとき、その経路式によって示される経路条件に適合するデータを検索できれば便利である。以下、省略記号を含むなどの理由により、検索対象となるデータの位置を一意に特定するには不充分な経路式のことを「部分経路式」とよび、省略記号を含まない経路式のことを「完全経路式」とよぶ。
【0006】
部分経路式に基づくデータ検索方法として、構造化文書ファイルのタグ構造を解析し、タグの経路情報をメモリに展開した上で、経路条件に適合する位置のデータを検出するという方法が一般的である。しかし、このような方法は、メモリの使用量が大きく、処理時間も長くなるという問題点がある。特に、多数の構造化文書ファイルや、タグの階層構造が複雑な構造化文書ファイルの中から所望のデータを探す場合には、このような問題点が顕在化しやすい。
【0007】
本発明はこうした状況に鑑みてなされたものであり、その目的は、不完全な経路式に基づいて構造化文書ファイル中から所望のデータを効率的に検索するための技術、を提供することある。
【課題を解決するための手段】
【0008】
本発明のある態様は、構造化文書ファイルから所望のデータを検索するための文書検索装置に関する。
この装置は、構造化文書ファイルにおいて階層的に上下関係にあるタグセットと、経路式の一部にそのタグセットを含む1以上の位置とを対応づけたインデックス情報を保持する。この装置は、部分経路式の入力を受け付けると、インデックス情報を参照して、部分経路式に含まれるタグセットが経路式の一部としてあらわれる位置を検索対象位置の候補位置として特定する。
【0009】
インデックス情報としてタグセットごとの位置を登録しておくことにより、検索実行時に文書ファイルにアクセスしてタグの階層構造を精査しなくても、検索対象となるデータを特定できる。このため、不完全な部分経路式が入力されたときにも、検索対象となるデータを効率的に検出できる。
【0010】
なお、以上の構成要素の任意の組み合わせ、本発明の表現を方法、システム、プログラム、記録媒体などの間で変換したものもまた、本発明の態様として有効である。
【発明の効果】
【0011】
本発明によれば、不完全な経路式に基づいて構造化文書ファイル中から所望のデータを効率的に検索することができる。
【発明を実施するための最良の形態】
【0012】
図1は、文書検索装置100による処理の概要を説明するための模式図である。
ユーザが文書検索装置100に対して経路式を入力すると、文書検索装置100は経路式に適合するデータを文書データベース200から検索する。文書データベース200の文書ファイルは、XML文書やXHTML文書のようにタグによって構造化された構造化文書ファイルである。本実施例においては、検索対象となる文書ファイルはXMLファイルであるとして説明する。
【0013】
文書検索装置100のインデックス保持部130は、各文書ファイルを検索するためのインデックス情報を保持する。インデックス情報は、完全経路インデックス214と部分経路インデックス230の2種類があるが、それぞれについては図3から図5に関連して後に詳述する。文書検索装置100は、入力された経路式とインデックス情報に基づいて、文書データベース200から検索対象となるデータがどの文書のどの位置にあるかを検索する。文書検索装置100は、検出された文書ファイルの文書IDと、その文書ファイルにおける検索対象データとを画面表示させる。こうして、文書検索装置100のユーザは、任意の経路式に対して、検索対象データ、または、検索対象データの候補を文書データベース200から探し出す。
【0014】
図2は、本実施例におけるXML文書210を示す図である。
同図に示すXML文書210を対象として本実施例を説明する。文書データベース200の各文書ファイルには文書IDが付与される。同図に示すXML文書210の文書IDは「1」であるとする。文書IDとは、文書データベース200において文書ファイルを一意に識別するためのIDである。このXML文書210は、アイディア提案書に関するXML文書であり、<提案>や<発案者>など複数のタグを含む。文書位置欄212は、XML文書210に含まれるさまざまなデータの位置を示す。たとえば、<提案>タグのこの文書における文書位置は「1」であり、</集約処理>タグの文書位置は「16」である。また、<発案者>タグの内容データである文字列”竹内真教”の文書位置は「3」である。文書位置は、タグ、属性、コメント、タグの内容となるデータごとに割り当てられ、文書ごとに一意の値となる。
以下においては説明を簡単にするため、タグに対する文書位置を中心として説明する。
【0015】
図3は、完全経路インデックス214のデータ構造図である。
完全経路インデックス214は、インデックス保持部130に格納される。経路欄216は、文書データベース200に含まれる経路式の一覧である。経路欄216には図2に示した文書ID=1の文書に含まれる経路式だけでなく、その他の文書に含まれる経路式も含まれる。経路ID欄218は、経路欄216に示す経路の経路IDを示す。経路IDは、経路式を示す文字列を所定規則により変換した数値列である。ハッシュ関数により変換してもよいし、所定のテーブルによって変換してもよいが、いずれにしても、各経路式が実用上差し支えない程度に一意に識別される値であればよい。
【0016】
同図において、経路式「/提案」のXML文書210における経路ID=1となっている。経路式「/提案/発案者」の場合、経路ID=2である。同様に、「/提案/内容/処理/前処理/集約処理」については経路ID=8となる。
【0017】
範囲欄222は、経路式によって示されるデータ範囲を[文書ID、開始位置、終了位置]の形式により範囲を示す。図2に示したXML文書210の場合、<集約処理>タグの文書位置は「14」であり、</集約処理>タグの文書位置「16」であるから、「/提案/内容/処理/前処理/集約処理」のデータは、文書ID=1の文書において文書位置=(14、16)の範囲のデータである。したがって、範囲欄222に示される範囲データは、[1、14、16]となる。
【0018】
同様に、経路式「/論文/内容/課題」の範囲データは[2、22、28]である。これは文書ID=2の文書において、文書位置=(22、28)の範囲のデータがこの経路式によって特定されるデータの範囲であることを示す。経路式「/提案/課題」の範囲データは[1、5、7]と[4、8、16]の2つである。これは文書ID=1と文書ID=4の2つのXML文書のどちらにも経路式「/提案/課題」という経路式が含まれることを意味する。
【0019】
完全経路インデックス214において経路式として表されるノードは<発案者>のようなタグに限られない。たとえば、図2の<発案者>タグの要素データである文字列”竹内真教”についても経路式として登録できる。この場合、経路式は「/提案/発案者/”竹内真教”」、経路ID=2014、範囲[1、3、3]となる。経路ID=2014は、「/提案/発案者/”竹内真教”」という文字列を所定規則に基づいて変換することにより得られる数値である。
【0020】
図4は、図3の経路欄216の詳細を示すデータ構造図である。
経路欄216には、実際には経路式を示す文字列がそのまま格納されるのではなく、経路式を数値表現したデータ(以下、特に区別するときには「数値経路式」とよぶ)が格納される。数値経路式は、実際の経路とは逆順に経路を示す。
【0021】
先述した経路式「/提案/発案者/”竹内真教”」を例として説明する。
数値経路式においては、まず、末端ノードである文字列”竹内真教”を示す4バイトの数値「4857」が先頭にくる。「4857」は所定の変換規則により文字列”竹内真教”を変換することにより得られる数値である。
次の1バイトは、末端ノードの種別を示す。種別は、要素:1、属性:2、テキスト:3、処理命令(PI:Processing Instruction):7、コメント:8のいずれかである。文字列”竹内真教”は、「/提案/発案者/」の内容を示すテキストなので、種別は「3」となる。
次に、<発案者>を示す4バイトの数値「0102」が続く。「0102」も所定の変換規則により文字列”発案者”を変換することにより得られる数値である。<提案>を示す数値は「0881」となる。数値経路式に含まれる各数値は、経路式の構成要素となる「提案」や「竹内真教」などの文字列を一意に識別できる数値であればよい。
以上により、「/提案/発案者/”竹内真教”」という経路式は、経路欄216においては「4857301020881」という13バイトの数値経路式として表される。
【0022】
A:完全経路式が入力された場合
完全経路式として「/提案/内容/処理/前処理/集約処理」が入力されたとする。文書検索装置100は、まず、この完全経路式を上述した方法により、数値経路式に変換する。この数値経路式と完全経路インデックス214の経路欄216における数値経路式を比較することにより、経路ID=8、範囲データ[1、14、16]を検出する。数値経路式同士のマッチングにより検出するため、文字列表現の経路式を比較するよりも高速な検索処理が可能である。
【0023】
B:部分経路式が入力される場合
部分経路式として「//構成」が入力されたとする。完全な経路がわからないので、文書検索装置100は、末端ノードの「構成」を数値表現に変換する。このとき、文書検索装置100は、「構成」を示す4バイトの数値と経路欄216の数値経路式の先頭4バイトを比較することにより、経路ID=5、範囲データ[1、9、11]を検出する。部分経路式においては、末端ノードがわかるがその上位ノードがわからないことが多い。本来の経路式の逆順となるように数値経路式を構成することにより、部分経路式の末端ノードだけである程度、検索対象データの候補を絞り込むことができる。
【0024】
ただし、「//内容/処理/*/集約処理」や「//内容/処理//集約処理」、「//内容/処理/*」のような部分経路式が与えられた場合、完全経路インデックス214から検索対象データを特定するためのアルゴリズムは複雑になる。タグの階層が深くなるといっそう処理は複雑化する。そこで、本実施例においては、完全経路インデックス214に加えて部分経路インデックス230により、検索対象データが存在する可能性がある位置(以下、「候補位置」とよぶ)を効率的に絞り込むための処理を実行している。
【0025】
図5は、部分経路インデックス230のデータ構造図である。
インデックス保持部130は、完全経路インデックス214に加えて部分経路インデックス230も格納している。キー欄226は、部分経路インデックス230において検索のキー(Key)となる2つのタグ(以下、「キータグセット」とよぶ)か、1つのタグ(以下、「キータグ」とよぶ)を示す。キータグセットとキータグを併せていうときには単に「キー」とよぶ。キータグセットとは、文書中のタグの階層として直接の上下関係にあるタグの組み合わせを示す。たとえば、XML文書210では<構成>タグの直接の親タグは<内容>なので、「内容/構成」はキータグセットとなる。しかし、<提案>タグや<課題>タグは<構成>タグの直接の親タグではないので「提案/構成」や「課題/構成」はキータグセットとはならない。これに対し、文書に含まれる全てのタグがキータグとなることができる。部分経路インデックス230は、文書データベース200に含まれる全ての文書に含まれるキーを対象としたデータである。
【0026】
位置インデックス欄228は、キーの出現する位置を[経路ID、出現階層]の形式で示す。このような形式の位置データのことを「位置インデックス」とよぶ。「内容/処理」というキータグセットは「/提案/内容/処理」という文書ID=1のXML文書210の第2階層からあらわれる。ルートノードを0階層とし、第1階層をルートノード直下の階層として数えている。以下、文書ID=n(nは自然数)のXML文書のことを文書(ID:n)のように表記することにする。位置インデックスには文書IDに関する情報が存在しないため、部分経路インデックス230だけでは、「内容/処理」が文書(ID:n)に存在することはわからない。
【0027】
経路式「/提案/内容/処理」の経路ID=6より、「内容/処理」の位置インデックスは[6、2]となる。同様にして、このキータグセットは「/提案/内容/処理/前処理」という文書(ID:1)、経路ID=7の経路式の第2階層にもあらわれる。このときの「内容/処理」の位置インデックスは[7、2]となる。
【0028】
先ほど例に挙げた「//内容/処理/*/集約処理」という部分経路式の場合、この部分経路式が示す経路条件は以下の通りである。
1.経路式に「内容/処理」、「集約処理」を含む。
2.「内容/処理」と「集約処理」の間には何らかの1階層がある、いいかえれば、<内容>から3階層下位に<集約処理>が出現する。
まず、部分経路式から、タグセット「内容/処理」、タグ「集約処理」を抽出する。
【0029】
キータグセット「内容/処理」の位置インデックスは、「6、2」、「7、2」、「8、2」、「11、2」、「12、2」の5つである。すなわち、キータグセット「内容/処理」を経路式に含む位置インデックスとして5箇所の候補が特定される。以下、このような候補となる位置インデックスのことを「候補位置」とよぶ。
キータグ「集約処理」の位置インデックスは、「8、5」、「12、4」の2つである。すなわち、キータグ「集約処理」に関する候補位置は2箇所である。
【0030】
ここで、「内容/処理」の位置インデックス「6、2」について、経路式ID=6であるが、「集約処理」の位置インデックスには経路ID=6となるものがない。これは、経路ID=6の経路式には、「集約処理」が含まれ得ないことを意味する。こうして、位置インデックス「6、2」は、上記経路条件から外れる。同様の理由から、「7、2」、「11、2」も候補から外れる。残るのは、「8、2」、「12、2」と「8、5」、「12、4」となる。
【0031】
「8、2」と「8、5」は、共に経路ID=8という経路式の一部を示し、「内容/処理」が第2階層、「集約処理」が第5階層にあらわれることを示している。すなわち、経路ID=8の経路式は「/*/内容/処理/*/集約処理」という経路式を含むことになるが、これは部分経路式に示された経路条件と整合している。完全経路インデックス214の経路ID=8のデータを参照することにより、範囲データ[1、14、16]を特定できる。すなわち、経路式「/提案/内容/処理/前処理/集約処理」が文書(ID:1)に特定される。
【0032】
一方、「12、2」と「12、4」は、共に、経路ID=12という経路式の一部を示し、「内容/処理」が第2階層、「集約処理」が第4階層にあらわれることを示している。すなわち、経路ID=12の「/*/内容/処理/集約処理」という経路式を含むことになるが、これは部分経路式に示された経路条件と整合していない。したがって、文書(ID:1)において、文書位置=(14、16)の範囲のデータだけが求めるデータである。
【0033】
同様にして、部分検索式「//内容/処理//集約処理」が与えられたときには、「内容/処理」と「集約処理」の間の階層数が不定なので、経路ID=8と12の両方の経路式が候補となる。部分検索式「//前処理//集約処理」が与えられたときには、タグ「前処理」について[7、4]、[8、4]、[15、3]が候補位置となり、キータグ「集約処理」について[8、5]、[12、4]となる。完全経路インデックス214も参照すると、文書ID=1、経路式ID=8の経路式のみが該当する。部分検索式「//提案/内容/*/前処理/集約処理」であれば、キータグセット「提案/内容」の位置インデックスとキータグセット「前処理/集約処理」についての位置インデックスと完全経路インデックス214から文書(ID:1)の経路ID=8の経路式が特定される。
このように、部分経路インデックス230によれば、不完全な部分検索式が入力されたときに文書データベース200のXML文書自体を経路解析する必要がなくなる。また、完全経路インデックス214の経路欄216から経路条件に整合する経路式を直接探すよりも、候補位置を効率的に絞り込むことができる。部分経路インデックス230を使った検索は、XML文書のタグ階層が深くなるときや検索対象となる文書数が多いときには特に有効な検索方法である。
【0034】
キー欄226のキーは、キーIDとよばれる所定長の数値列として格納される。キーIDは、キータグセットやキータグを一意に識別できる数値であればよい。キー欄226におけるキーを数値表現形式で格納することにより、キー名を示す文字列をそのまま格納するよりも検索処理をいっそう高速化することができる。キーIDも、キーを示す文字列を所定のハッシュ関数によって変換することにより生成してもよい。あるいは、キーとキーIDを一意に対応づける変換テーブルにより、互いを対応づけてもよい。
【0035】
図6は、文書検索装置100の機能ブロック図である。
ここに示す各ブロックは、ハードウェア的には、コンピュータのCPUをはじめとする素子や機械装置で実現でき、ソフトウェア的にはコンピュータプログラム等によって実現されるが、ここでは、それらの連携によって実現される機能ブロックを描いている。したがって、これらの機能ブロックはハードウェア、ソフトウェアの組み合わせによっていろいろなかたちで実現できることは、当業者には理解されるところである。
【0036】
文書検索装置100は、ユーザインタフェース処理部110、データ処理部120およびインデックス保持部130を含む。
ユーザインタフェース処理部110は、ユーザからの入力処理やユーザに対する情報表示のようなユーザインタフェース全般に関する処理を担当する。本実施例においては、ユーザインタフェース処理部110により文書検索装置100のユーザインタフェースサービスが提供されるものとして説明する。別例として、ユーザはインターネットを介して文書検索装置100を操作してもよい。この場合、図示しない通信部が、ユーザ端末からの操作指示情報を受信し、またその操作指示に基づいて実行された処理結果情報をユーザ端末に送信することになる。
【0037】
データ処理部120は、ユーザインタフェース処理部110や文書データベース200から取得されたデータを元にして各種のデータ処理を実行する。データ処理部120は、ユーザインタフェース処理部110とインデックス保持部130の間のインタフェースの役割も果たす。
【0038】
ユーザインタフェース処理部110は、入力部112と表示部114を含む。入力部112は、ユーザからの入力操作を受け付ける。検索用の経路式は、入力部112を介して取得される。表示部114は、ユーザに対して各種情報を表示する。
【0039】
データ処理部120は、経路分解部122と検索部124、登録部126を含む。
経路分解部122は、部分経路式やXML文書の経路情報を解析する。部分抽出部128は、部分経路式やXML文書からタグやタグセットを抽出する。ID変換部132は、経路式やキーを数値表現に変換する。また、ID変換部132は、経路式から経路IDを生成する。登録部126は、新たなXML文書が文書データベース200に追加されるとき、その文書についてのデータを完全経路インデックス214と部分経路インデックス230に登録する。
【0040】
XML文書が文書データベース200に追加されるとき、ID変換部132は文書中の経路式を数値経路式に変換する。そして、登録部126が完全経路インデックス214に数値経路式とその範囲データを登録する。また、部分抽出部128は文書からキーを抽出し、ID変換部132がキーを数値表現形式のキーIDに変換する。登録部126は部分経路インデックス230に数値表現形式のキーIDと位置インデックスを登録する。文書データベース200のXML文書が編集、削除されたときにも、同様の処理方法により、完全経路インデックス214と部分経路インデックス230が更新される。
【0041】
検索部124は、入力された経路式に基づいて、文書および該当箇所を検出する。検索部124は、位置特定部134と範囲特定部136を含む。位置特定部134は、部分経路インデックス230を参照して、キーから位置インデックスを特定する。範囲特定部136は、経路式から範囲データを特定する。
部分経路式による検索に際しては、部分抽出部128が部分経路式からキーを抽出し、ID変換部132がキーを数値表現形式のキーIDに変換する。位置特定部134は、このキーIDに基づいて部分経路インデックス230から候補位置を特定する。範囲特定部136は、位置特定部134が特定した候補位置から、範囲データを特定する。結果は、表示部114により画面表示される。
【0042】
図7は、部分経路式に基づく検索処理の過程を示すフローチャートである。
まず、入力部112が部分経路式の入力を受け付ける(S10)。部分抽出部128は、部分検索式から1以上のキーとなるタグセットやタグを抽出する(S12)。ここでは、先ほどの「//内容/処理/*/集約処理」という部分検索式が入力され、キータグセット「内容/処理」とキータグ「集約処理」が抽出されたとする。抽出されたキーは、ID変換部132によってキーIDに変換される。位置特定部134は、部分経路インデックス230を参照して、キーIDから候補位置を特定する(S14)。キータグセット「内容/処理」の位置インデックスであれば、「6、2」、「7、2」、「8、2」、「11、2」、「12、2」の5つの位置インデックスが特定される。
【0043】
更に、別のキーが抽出されていれば(S16のN)、S14に戻って次のキーについての候補位置が特定される。先ほどの例の場合、キータグ「集約処理」について「8、5」、「12、4」の2つの位置インデックスが特定される。
【0044】
全てのキーについて候補位置が特定されると(S16のY)、位置特定部134は各キーについて特定された候補位置の間で整合する位置を特定する(S18)。こうして、候補位置の数が絞り込まれる。部分検索式「//内容/処理/*/集約処理」については、「8、2」と「8、5」のペアが特定される。範囲特定部136は、この位置インデックスに示される経路ID=8に基づいて、完全経路インデックス214から範囲データ[1、14、16]を特定する(S20)。表示部114は、文書(ID:1)の経路ID=8の経路式について該当データ、すなわち、文書位置14から文書位置16までのデータを画面表示させる(S22)。
【0045】
以上のアルゴリズムに基づいて、更に、複合的なデータ検索も可能である。たとえば、部分検索式「//発案者」と文字列「”竹内真教”」が入力されたとする。位置特定部134は、キータグ「発案者」について、部分経路インデックス230から位置インデックス「2、2」を特定する。完全経路インデックス214によると、「//発案者」に該当する範囲データは、文書(ID:1)、文書位置=(2、4)にある。経路式は「/提案/発案者」である。
【0046】
検索部124の図示しない文字列検索部は、文字列「”竹内真教”」について、完全経路インデックス214から該当する範囲データを検索する。範囲データとして[1、3、3]と特定されたとする。この場合、文字列「”竹内真教”」のデータの範囲は、「/提案/発案者」のデータの範囲におさまっている。検索部124は、部分検索式「//発案者」と文字列「”竹内真教”」のそれぞれについて特定された範囲データが整合したので、「/提案/発案者/”竹内真教”」を該当データとして特定する。
【0047】
なお、本実施例におけるキータグセットとは、階層的に直接の上下関係にある2つのタグの組み合わせであるとして説明したが、キータグセットはこのような条件に制約される必要はない。たとえば、階層的に直接の上下関係にある3つのタグの組み合わせであってもよい。もちろん、3個以上のタグの組み合わせをキータグセットとしてもよい。
【0048】
また、キータグセットに含まれるタグは、必ずしも直接の上下関係になくてもよい。たとえば、「/提案/内容/処理/前処理/集約処理」という経路式において、「内容-前処理」というタグの組み合わせではタグ間に2階層の差がある。また、「内容-集約処理」というタグの組み合わせであれば、階層差は3となる。部分経路インデックス230においては、キータグセットと、そのキータグセットを構成するタグ間の階層差が記録されてもよい。そして、位置特定部134は、部分経路式から抽出したタグセットの階層差と、キータグセットにおける階層差を参照して、候補位置を特定してもよい。
【0049】
本実施例ではXML文書を対象として説明したが、文書検索装置100は、XHTMLやHTML、SGMLなど、タグの階層構造に基づく経路式によってデータの位置が特定されるタイプの文書ファイルであれば、いずれを対象としても応用可能である。
【0050】
以上、本実施例に示す文書検索装置100によると、部分経路式に基づくデータ検索を効率的に実行できる。部分経路インデックス230に「キータグ」や「キータグセット」についての位置インデックスを登録しておくことにより、部分経路式に含まれるタグセットやタグに基づいて、候補位置を絞り込むことができる。そして、完全経路インデックス214により、より具体的にデータの位置を特定できる。検索時に文書ファイルを調べて、経路情報をメモリに展開する必要がないため、効率的な検索が可能となる。
【0051】
部分経路式によるデータ検索の処理負荷が大きくなると、部分経路式に基づくデータ検索がユーザにとって使いにくいものとなってしまう。本実施例に示した文書検索装置100は、完全経路インデックス214と部分経路インデックス230という2種類のインデックスデータを参照することにより、求めるデータの位置を高速かつ軽い計算機負荷にて特定できることになる。
【0052】
以上、本発明を実施の形態をもとに説明した。この実施の形態は例示であり、それらの各構成要素や各処理プロセスの組み合わせにいろいろな変形例が可能なこと、またそうした変形例も本発明の範囲にあることは当業者に理解されるところである。
【0053】
請求項に記載の「インデックス情報」は、本実施例における部分経路インデックス230により表現されている。請求項に記載の「タグセットID」は、本実施例においては、キータグセットについてのキーIDとして表現されている。
これら請求項に記載の各構成要件が果たすべき機能は、本実施例において示された各機能ブロックの単体もしくはそれらの連係によって実現されることも当業者には理解されるところである。
【図面の簡単な説明】
【0054】
【図1】文書検索装置による処理の概要を説明するための模式図である。
【図2】本実施例におけるXML文書を示す図である。
【図3】完全経路インデックスのデータ構造図である。
【図4】図3の経路欄の詳細を示すデータ構造図である。
【図5】部分経路インデックスのデータ構造図である。
【図6】文書検索装置の機能ブロック図である。
【図7】部分経路式に基づく検索処理の過程を示すフローチャートである。
【符号の説明】
【0055】
100 文書検索装置、 110 ユーザインタフェース処理部、 112 入力部、 114 表示部、 120 データ処理部、 122 経路分解部、 124 検索部、 126 登録部、 128 部分抽出部、 130 インデックス保持部、 132 ID変換部、 134 位置特定部、 136 範囲特定部、 200 文書データベース、 212 文書位置欄、 214 完全経路インデックス、 216 経路欄、 218 経路ID欄、 222 範囲欄、 226 キー欄、 228 位置インデックス欄、 230 部分経路インデックス。
【特許請求の範囲】
【請求項1】
タグの階層構造に基づく経路式によってデータの位置が特定される構造化文書ファイルにおいて、階層的に上下関係にあるタグの組み合わせであるタグセットと、経路式の一部にそのタグセットを含む1以上の位置とを対応づけたインデックス情報を保持するインデックス保持部と、
前記構造化文書ファイルにおける検索対象位置への経路式の一部を示す部分経路式の入力を受け付ける経路式入力部と、
前記部分経路式から階層的に上下関係にあるタグセットを抽出するタグセット抽出部と、
前記インデックス情報を参照して、前記部分経路式から抽出されたタグセットが経路式の一部としてあらわれる位置を前記検索対象位置の候補位置として特定する候補位置特定部と、
を備えることを特徴とする文書検索装置。
【請求項2】
タグセットとは、階層的に直接の上下関係にある2つのタグの組み合わせであることを特徴とする請求項1に記載の文書検索装置。
【請求項3】
前記タグセット抽出部が、前記部分経路式から第1のタグセットと第2のタグセットを抽出したとき、
前記候補位置特定部は、前記第1のタグセットについての候補位置と前記第2のタグセットについての候補位置を比較して互いに整合する位置を、前記検索対象位置の候補位置として特定することを特徴とする請求項1または2に記載の文書検索装置。
【請求項4】
前記タグセット抽出部が、前記第1のタグセットを前記第2のタグセットよりも階層的に上位のタグセットとして検出したとき、
前記候補位置特定部は、前記第1のタグセットと前記第2のタグセットの前記部分経路式における階層上の距離と、前記第1のタグセットについての候補位置と前記第2のタグセットについての候補位置との距離が整合する位置を、前記検索対象位置の候補位置として特定することを特徴とする請求項3に記載の文書検索装置。
【請求項5】
前記インデックス保持部は、更に、前記構造化文書ファイルに含まれるタグと、経路式の一部にそのタグを含む1以上の位置とをインデックス情報の一部として対応づけて保持し、
前記タグセット抽出部は、前記部分経路式から特定タグを抽出し、
前記候補位置特定部は、前記インデックス情報を参照して、前記部分経路式から抽出された特定タグが経路式の一部としてあらわれる位置を前記特定タグについての候補位置として検出すると共に、前記部分経路式から抽出されたタグセットの候補位置と前記特定タグについての候補位置を比較して互いに整合する位置を、前記検索対象位置の候補位置として特定することを特徴とする請求項1から4のいずれかに記載の文書検索装置。
【請求項6】
前記インデックス保持部は、タグセットを所定規則にしたがって所定長の文字列に変換したタグセットIDと、経路式の一部にそのタグセットを含む1以上の位置を対応づけてインデックス情報として保持し、
前記候補位置特定部は、前記部分経路式から抽出されたタグセットを前記所定規則にしたがってタグセットIDに変換した上で、候補位置を特定することを特徴とする請求項1から5のいずれかに記載の文書検索装置。
【請求項7】
タグの階層構造に基づく経路式によってデータの位置が特定される構造化文書ファイルにおいて、階層的に上下関係にあるタグの組み合わせであるタグセットと、経路式の一部にそのタグセットを含む1以上の位置とを対応づけたインデックス情報を取得するステップと、
前記構造化文書ファイルにおける検索対象位置への経路式の一部を示す部分経路式の入力を受け付けるステップと、
前記部分経路式から階層的に上下関係にあるタグセットを抽出するステップと、
前記インデックス情報を参照して、前記部分経路式から抽出されたタグセットが経路式の一部としてあらわれる位置を前記検索対象位置の候補位置として特定するステップと、
を備えることを特徴とする文書検索方法。
【請求項8】
タグの階層構造に基づく経路式によってデータの位置が特定される構造化文書ファイルにおいて、階層的に上下関係にあるタグの組み合わせであるタグセットと、経路式の一部にそのタグセットを含む1以上の位置とを対応づけたインデックス情報を保持する機能と、
前記構造化文書ファイルにおける検索対象位置への経路式の一部を示す部分経路式の入力を受け付ける機能と、
前記部分経路式から階層的に上下関係にあるタグセットを抽出する機能と、
前記インデックス情報を参照して、前記部分経路式から抽出されたタグセットが経路式の一部としてあらわれる位置を前記検索対象位置の候補位置として特定する機能と、
をコンピュータに発揮させることを特徴とする文書検索プログラム。
【請求項1】
タグの階層構造に基づく経路式によってデータの位置が特定される構造化文書ファイルにおいて、階層的に上下関係にあるタグの組み合わせであるタグセットと、経路式の一部にそのタグセットを含む1以上の位置とを対応づけたインデックス情報を保持するインデックス保持部と、
前記構造化文書ファイルにおける検索対象位置への経路式の一部を示す部分経路式の入力を受け付ける経路式入力部と、
前記部分経路式から階層的に上下関係にあるタグセットを抽出するタグセット抽出部と、
前記インデックス情報を参照して、前記部分経路式から抽出されたタグセットが経路式の一部としてあらわれる位置を前記検索対象位置の候補位置として特定する候補位置特定部と、
を備えることを特徴とする文書検索装置。
【請求項2】
タグセットとは、階層的に直接の上下関係にある2つのタグの組み合わせであることを特徴とする請求項1に記載の文書検索装置。
【請求項3】
前記タグセット抽出部が、前記部分経路式から第1のタグセットと第2のタグセットを抽出したとき、
前記候補位置特定部は、前記第1のタグセットについての候補位置と前記第2のタグセットについての候補位置を比較して互いに整合する位置を、前記検索対象位置の候補位置として特定することを特徴とする請求項1または2に記載の文書検索装置。
【請求項4】
前記タグセット抽出部が、前記第1のタグセットを前記第2のタグセットよりも階層的に上位のタグセットとして検出したとき、
前記候補位置特定部は、前記第1のタグセットと前記第2のタグセットの前記部分経路式における階層上の距離と、前記第1のタグセットについての候補位置と前記第2のタグセットについての候補位置との距離が整合する位置を、前記検索対象位置の候補位置として特定することを特徴とする請求項3に記載の文書検索装置。
【請求項5】
前記インデックス保持部は、更に、前記構造化文書ファイルに含まれるタグと、経路式の一部にそのタグを含む1以上の位置とをインデックス情報の一部として対応づけて保持し、
前記タグセット抽出部は、前記部分経路式から特定タグを抽出し、
前記候補位置特定部は、前記インデックス情報を参照して、前記部分経路式から抽出された特定タグが経路式の一部としてあらわれる位置を前記特定タグについての候補位置として検出すると共に、前記部分経路式から抽出されたタグセットの候補位置と前記特定タグについての候補位置を比較して互いに整合する位置を、前記検索対象位置の候補位置として特定することを特徴とする請求項1から4のいずれかに記載の文書検索装置。
【請求項6】
前記インデックス保持部は、タグセットを所定規則にしたがって所定長の文字列に変換したタグセットIDと、経路式の一部にそのタグセットを含む1以上の位置を対応づけてインデックス情報として保持し、
前記候補位置特定部は、前記部分経路式から抽出されたタグセットを前記所定規則にしたがってタグセットIDに変換した上で、候補位置を特定することを特徴とする請求項1から5のいずれかに記載の文書検索装置。
【請求項7】
タグの階層構造に基づく経路式によってデータの位置が特定される構造化文書ファイルにおいて、階層的に上下関係にあるタグの組み合わせであるタグセットと、経路式の一部にそのタグセットを含む1以上の位置とを対応づけたインデックス情報を取得するステップと、
前記構造化文書ファイルにおける検索対象位置への経路式の一部を示す部分経路式の入力を受け付けるステップと、
前記部分経路式から階層的に上下関係にあるタグセットを抽出するステップと、
前記インデックス情報を参照して、前記部分経路式から抽出されたタグセットが経路式の一部としてあらわれる位置を前記検索対象位置の候補位置として特定するステップと、
を備えることを特徴とする文書検索方法。
【請求項8】
タグの階層構造に基づく経路式によってデータの位置が特定される構造化文書ファイルにおいて、階層的に上下関係にあるタグの組み合わせであるタグセットと、経路式の一部にそのタグセットを含む1以上の位置とを対応づけたインデックス情報を保持する機能と、
前記構造化文書ファイルにおける検索対象位置への経路式の一部を示す部分経路式の入力を受け付ける機能と、
前記部分経路式から階層的に上下関係にあるタグセットを抽出する機能と、
前記インデックス情報を参照して、前記部分経路式から抽出されたタグセットが経路式の一部としてあらわれる位置を前記検索対象位置の候補位置として特定する機能と、
をコンピュータに発揮させることを特徴とする文書検索プログラム。
【図1】


【図2】

【図3】
【図4】
【図5】

【図6】

【図7】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【公開番号】特開2008−90403(P2008−90403A)
【公開日】平成20年4月17日(2008.4.17)
【国際特許分類】
【出願番号】特願2006−267888(P2006−267888)
【出願日】平成18年9月29日(2006.9.29)
【出願人】(390024350)株式会社ジャストシステム (123)
【Fターム(参考)】
【公開日】平成20年4月17日(2008.4.17)
【国際特許分類】
【出願日】平成18年9月29日(2006.9.29)
【出願人】(390024350)株式会社ジャストシステム (123)
【Fターム(参考)】
[ Back to top ]