
Fターム[5B075ND03]の内容
Fターム[5B075ND03]に分類される特許
1 - 20 / 3,390
情報端末装置、情報検索方法、情報検索プログラム
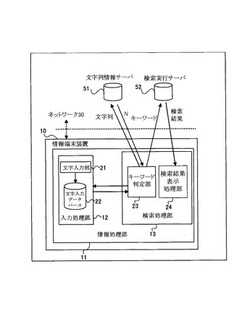
【課題】ユーザにとって無駄な情報の提示を防ぐこと。
【解決手段】本発明の情報端末装置は、文字入力部と、前記文字入力部からの入力に基づいて文字列を登録する文字列記憶部と、所定のタイミングで、前記文字列記憶部に登録された文字列を候補文字列として、第1のサーバに送信し、送信した候補文字列の検索回数又は関連語の数を前記第1のサーバから受信する送受信部と、前記第1のサーバから受信した候補文字列の検索回数又は関連語の数に基づいて、候補文字列を第2のサーバに送信して関連する情報の検索を行うか否かを判定する検索実行判定部と、を備える。
(もっと読む)
検索方法、検索装置、ならびに、コンピュータプログラム

【課題】ユーザの意図にあった検索結果を提示するのに好適な検索方法、検索装置、ならびに、コンピュータプログラムを提供する。
【解決手段】検索装置1において、抽出部101は、複数の文書データ(文書データ群300)のうちから、複数の検索文字列を含む文書データを抽出する。取得部102は、抽出された文書データのそれぞれにおいて、複数の検索文字列を全て包含する文字列を取得する。設定部103は、抽出された文書データのそれぞれに、当該文書データにおいて取得された文字列の文字数に基づいて、出力優先度を設定する。出力部104は、設定された出力優先度を対応付けて、抽出された文書データを出力する。跨り判定部105は、取得された文字列が複数のセンテンスに跨っているか否かを判定する。重複判定部106は、取得された文字列に包含される複数の検索文字列が同一位置にある文字を共有しているか否かを判定する。
(もっと読む)
発言管理システム、発言管理方法及び発言管理プログラム
【課題】会議等における発言についての記録を作成するとともに、円滑な議事進行を支援するための発言管理システム、発言管理方法及び発言管理プログラムを提供する。
【解決手段】会議支援サーバ20の制御部21は、音声を取得し、音声認識処理を実行する。そして、発言管理情報記憶部25に、認識結果を記録する。次に、制御部21は、発言管理情報記憶部25を用いて、キーワード抽出処理を実行する。キーワードに基づいて実行される会議進行管理処理において、議事進行があったと判定した場合、制御部21は、議事項目の消込処理を実行する。また、キーワードに基づいて実行される説明表示管理処理においては、制御部21は、参考情報を検索し、クライアント端末10において表示候補を出力する。
(もっと読む)
検索方法、検索装置、ならびに、コンピュータプログラム
【課題】複数の文書グループからの検索結果を効果的に提示するのに好適な検索方法、検索装置、ならびに、コンピュータプログラムを提供する。
【解決手段】検索装置1において、抽出部101は、複数の文書グループ300a〜300nのそれぞれが備える複数の文書データのうちから、所望の検索文字列を含む文書データを抽出する。設定部102は、抽出された文書データのそれぞれに、所定の設定規則に基づいて、出力優先度を設定する。判定部103は、複数の文書グループ300a〜300nのそれぞれが、出力優先度が設定された文書データのうち所定の出力条件を満たす文書データを備えるか否かを、順に判定する。出力部104は、判定した文書グループ300a〜300nが所定の出力条件を満たす文書データを備える場合、当該文書データのうち所定の個数を出力する。
(もっと読む)
文書処理装置およびプログラム
【課題】類義語として適切な用語を文書から抽出することが可能な文書処理装置およびプログラムを提供することにある。
【解決手段】用語抽出手段は、文書格納手段に格納されている複数の文書から第1および第2の用語を抽出する。クラスタ生成手段は、複数の文書の各々が属するクラスタを生成する。特徴度算出手段は、複数の文書および生成されたクラスタに属する文書における第1の用語の出現頻度に基づいて当該クラスタに対する第1の用語の特徴度を算出し、複数の文書およびクラスタ生成手段によって生成されたクラスタに属する文書における第2の用語の出現頻度に基づいて当該クラスタに対する第2の用語の特徴度を算出する。類義語抽出手段は、算出された類似度、算出された第1の用語の特徴度および第2の用語の特徴度に基づいて当該第1および第2の用語を類義語として抽出する。
(もっと読む)
拾い読み支援システム、拾い読み支援方法及びプログラム
【課題】多数の文書の拾い読みを支援すること。
【解決手段】実施形態によれば、文書記憶部、表示部、入力部、分類情報記憶部、抽出部、特定部を含む。文書記憶部は、複数の文書を識別情報とともに記憶する。ユーザは、表示部の文書を閲覧し、文書と付与する分類タイプを入力部から指示する。分類情報記憶部は、ユーザ指示された文書の分類タイプを記憶する。抽出部は、同一の分類タイプが対応付けられている1又は複数の前記文書から、当該分類タイプについてハイライト表示すべき1又は複数の単語又はフレーズを抽出する。特定部は、ユーザから分類タイプが付与されていない文書の各々について、当該文書中で上記単語又はフレーズをハイライト表示すべき箇所を特定する。表示部は、文書を表示するにあたって、上記箇所で上記単語又はフレーズをハイライト表示する。
(もっと読む)
職員情報提供サーバ、及び職員情報提供処理プログラム
【課題】分散して管理している職員情報を一括管理することなく円滑に提供する。
【解決手段】職員情報提供サーバ10が、組織内情報インデックスDB11に記憶された所定の検索項目をユーザ端末50に対して提示し、提示した所定の検索項目の中から選択された複数の検索項目と、各検索項目におけるそれぞれの抽出条件を示す項目条件とを指定した検索要求に応じて、職員情報の一部をそれぞれ管理する複数の管理サーバ20,30,40のうち、指定された各検索項目に係る職員情報をそれぞれ管理する複数の管理サーバから、指定された検索項目における指定された項目条件を満たす職員に関する情報を取得し、取得した情報に基づいて、検索要求にて指定された複数の検索項目それぞれの項目条件を全て満たす職員に関する情報を示す情報を特定し、特定した情報を検索結果の職員情報として送信する。
(もっと読む)
プログラムおよび情報処理装置
【課題】特定の患者本人の傷病に言及する傷病名であるか否かに応じたコードの付与を支援する。
【解決手段】傷病名文字列検出部120は、傷病名を表す用語の情報を含む傷病名辞書101を参照して、ある患者に関して記述された文章に含まれる文字列である対象文字列のうち、傷病名の文字列を特定する。一般論条件情報104は、特定の患者の傷病に言及していない表現の条件として予め設定された条件を表す。一般論判定部150は、特定された傷病名の文字列が、対象文字列中の文字列であって一般論条件情報104が表す条件を満たす文字列に含まれる場合に、当該特定された傷病名の文字列を、対象文字列を含む文章の記述の対象である患者本人の傷病に言及していない傷病名であると判定する。
(もっと読む)
情報管理装置及び情報管理方法
【課題】本発明は、情報収集効率を向上させ得る情報管理装置を提案する。
【解決手段】ユーザにより入力済みの記入情報を取得して保存する記入情報保存部と、記入情報保存部により保存された記入情報から特徴語を抽出する特徴語抽出部と、記入情報保存部により保存された記入情報の総数に対して、特徴語が含まれている記入回答の数の割合を算出する割合算出部と、特徴語と、割合算出部により算出された割合とを関連付けて記憶する特徴語−割合記憶部と、特徴語−割合記憶部に記憶された割合に基づいて、当該割合に関連付けられた特徴語を選択して所定の画面に表示させる特徴語選択部と、特徴語−割合記憶部に記憶されている特徴語の有効/無効を操作する操作部と、を備え、割合算出部は、操作部により無効とされていない特徴語を含む記入情報の総数に対して、特徴語が含まれている記入情報の数の割合を算出することを特徴とする。
(もっと読む)
類義語リストの生成方法および生成装置、当該類義語リストを用いた検索方法および検索装置、ならびに、コンピュータプログラム
【課題】検索語を類義語にまで拡張しつつ効果的に検索するのに好適な類義語リストの生成方法等を提供する。
【解決手段】生成装置1において、判定部101は、類義語データベース300が備える複数の基準語とそれに対応する類義語のそれぞれについて、検索対象の複数の文書データ(文書データ群400)のうちのいずれかに含まれているか否かを判定する。抽出部102は、文書データ群400に含まれると判定された基準語と類義語を抽出する。設定部103は、抽出された類義語のそれぞれに、文書データ群400における当該類義語と対応する基準語の少なくとも一方の出現態様に基づいて、出力優先度を設定する。生成部104は、抽出された基準語のそれぞれに、当該基準語に対応する類義語のうち出力優先度が設定された類義語を対応付けて、類義語リスト900を生成する。
(もっと読む)
要約文生成装置及びプログラム
【課題】機器の使用に関する事項を含むテキストから、本質となる部分を抽出した要約文を生成する。
【解決手段】機器の使用に関する事項を含むテキストを、事項分割部24で、予め定めた事項分割ルールに従って、「状況」、「操作」、「現象」、「要望・意見・質問」に関する事項の各々に該当する部分毎に分割し、重要部分抽出部28で、重要単語辞書26を参照して、各部分に含まれる重要単語数をカウントし、最も多く重要単語を含む部分を重要部分として抽出し、要約文生成部30で、抽出された重要部分の終端に述部を連接するか、重要部分の終端を終止形に変形するか、または重要部分からガ格及び述語を抽出して要約文を生成する。
(もっと読む)
文書管理方法、文書管理装置及び文書管理プログラム
【課題】オンラインマニュアルの各セクションに対する適切な優先表示番号の付与を実現する。
【解決手段】複数の患者IDと、各患者に関してコンポーネントに入力された患者情報(保険番号、公費番号)とを対応付けて記憶する患者DB30から、複数の患者の患者情報を抽出し、抽出された患者情報の分布を算出し、算出された分布に基づいて、オンラインマニュアルの各セクションを管理する関連付けDB36のうち、コンポーネントに対応するセクションに対して、出力に関する優先順位(優先表示番号)を付与する。
(もっと読む)
診療情報入力装置、プログラム及び診療情報入力方法
【課題】電子カルテへ入力する傷病名に付加された傷病部位を他の傷病部位に容易に変更することができる診療情報入力装置、プログラム及び診療情報入力方法を提供する。
【解決手段】身体における傷病の位置を示す文字列が含まれた修飾語及び該修飾語が付加される傷病名を電子カルテに入力する診療情報入力装置1において、前記修飾語を受け付ける受付部と、該受付部が受け付けた修飾語から傷病の位置を示す文字列を抽出する抽出部と、傷病の位置を示す文字列及び該位置と異なる他の位置を示す文字列を関連付けて記憶してある記憶部から、前記抽出部が抽出した前記文字列に係る位置と異なる他の位置を示す文字列を検索する検索部と、前記受付部が受け付けた修飾語に含まれる前記文字列を、前記検索部が検索した他の位置を示す文字列と置換する置換部と、該置換部が置換した他の位置を示す文字列が含まれた修飾語を出力する出力部とを備える。
(もっと読む)
情報検索装置およびプログラム
【課題】情報検索装置において、入力された検索文字列を見出し語あるいはその解説情報に含む当該見出し語の一覧を、検索文字列の解説として重要度の高い順番で出力する。
【解決手段】例えば[古語辞典]が指定されてキーワード「いと」「けれ」が入力されると、各見出し語とその説明情報からなる辞書データの全文から、入力された2つのキーワードを共に含むところの見出し語が検索され、検索された各見出し語とその解説情報のそれぞれにおいて前記2つのキーワードが出現する先頭からの位置(文字数)およびその相対距離(文字数)が取得される。そして、前記2つのキーワードの先頭からの出現位置が近い方またはその相対距離が近い方の何れが重要であるかに応じて重み付け評価点が算出され、算出された評価点に基づき重要度の高い順に前記検索された各見出し語が見出し語一覧エリアに表示される。
(もっと読む)
Nグラム検索のための転置インデックスの生成方法および生成装置、当該転置インデックスを用いた検索方法および検索装置、ならびに、コンピュータプログラム
【課題】データサイズを抑えつつ高速な検索処理を実現するのに好適な転置インデックスの生成方法等を提供する。
【解決手段】生成装置1において、抽出部101は、文書データ300のうちから「3文字の文字列であるトライグラム」を、当該文書データ300中での出現位置と対応付けて、抽出する。分類部102は、抽出されたトライグラムのうち中央の文字が共通なトライグラムを、先頭および末尾の文字に基づいて、トライグラム群に分類する。生成部103は、分類されたトライグラム群のそれぞれに、当該トライグラム群に分類されたトライグラムに対応付けられた出現位置を対応付けて、転置インデックス900を生成する。
(もっと読む)
情報生成装置、情報表示装置、情報生成方法、及び情報生成プログラム
【課題】文書相互の類似度を表す情報を生成できること。
【解決手段】文書比較部は、複数の第1の文書の文書情報に基づいて、第1の文書同士の類似度を算出する。配置位置算出部は、文書比較部が算出した複数の類似度に基づいて、第1の文書の類似度に対応する間隔であって、最初の点と最後の点が接続されている座標における間隔を算出する。
(もっと読む)
文書分析装置およびプログラム
【課題】ユーザによって指定された属性のカテゴリに対して相関が高い属性のカテゴリを提示することが可能な文書分析装置およびプログラムを提供することにある。
【解決手段】分類手段は、第2のカテゴリに分類された文書数と各第1のカテゴリおよび第2のカテゴリの両方に分類された文書数とに基づいて第2のカテゴリを第3のカテゴリに分類する。抽出手段は、第3のカテゴリに分類された文書における各属性値を含む文書数および文書記憶手段に記憶されている複数の文書における各属性値を含む文書数に基づいて第3のカテゴリの特徴的な属性を抽出する。再分類手段は、第3のカテゴリに分類された文書数と各第1のカテゴリおよび第3のカテゴリの両方に分類された文書数と第3のカテゴリの特徴的な属性の属性値とに基づいて第3のカテゴリを第4のカテゴリに再分類する。提示処理手段は、第4のカテゴリを提示する。
(もっと読む)
Nグラム検索のための転置インデックスの生成方法および生成装置、当該転置インデックスを用いた検索方法および検索装置、ならびに、コンピュータプログラム
【課題】検索漏れを抑えるのに好適な転置インデックスの生成方法等を提供する。
【解決手段】生成装置1は、複数の文書データ(文書データ群500)のそれぞれを、所定の変換規則に基づいて、変換文書データに変換する文書文字列変換部101と、変換された複数の文書データに含まれる文字列から、「N文字の文字列であるNグラム(Nは自然数)」を抽出する文書Nグラム抽出部102と、抽出されたNグラムと、変換文書データ中における当該Nグラムの出現位置と、を構成要素とする転置インデックス600を生成するインデックス生成部103と、を備えることを特徴とする。
(もっと読む)
Web検索補助装置、Web検索補助システム、Web検索補助方法およびプログラム
【課題】キーワードを自動的に抽出して、Webページの絞り込みおよび分類を行って、必要なWebページを抽出する。
【解決手段】ユーザからの検索キーワードを入力し、検索キーワードを適切なクエリに変換する。クエリをWeb検索サイトに送信し、Web検索サイトの検索結果を分類する。次に、検索結果のWebページ数が予め定められた閾値以下であるか否かを判定し、分類されたWebページから共通のキーワードを抽出し、抽出したキーワードを変換処理に出力する。そして、検索結果のWebページ数が予め定められた閾値以下となった場合に、検索結果およびキーワードを出力する。
(もっと読む)
情報表示装置およびプログラム
【課題】辞書情報等の電子化された文書情報を表示するための情報表示装置において、文書上に存在するリンク有り文字列を容易に発見し且つ容易に選択することを可能にする。
【解決手段】[日本史辞書]の見出し語[安土桃山時代]に対応する内容情報表示画面Gが表示されたメイン表示部17において、タッチアイコンエリア17Bの[単語マップ]アイコンBMがタッチされると、前記内容情報に含まれるリンク有り文字列[織田信長]L1〜[伏見城]L4がリスト化され、リンクリストLLとしてサブ表示部16に表示される。サブ表示部16に表示されたリンクリストLLの任意のリンク有り文字列(単語)Lnがタッチされて識別表示されると、同識別表示されたリンク有り文字列(単語)Lnを見出し語とする[日本史辞書]内の内容情報が読み出され、その内容情報表示画面Gnが前記メイン表示部17またはサブ表示部16に表示される。
(もっと読む)
1 - 20 / 3,390
[ Back to top ]