
Fターム[5B075ND03]の内容
Fターム[5B075ND03]に分類される特許
41 - 60 / 3,390
データ極性判定装置、方法、及びプログラム
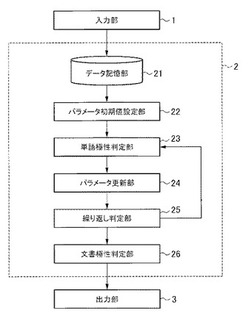
【課題】分野依存性を考慮した上で、観測データの極性を精度よく判定することができるようにする。
【解決手段】パラメータ初期値設定部22によって、極性付き文書生成モデルのパラメータの初期値を設定する。単語極性判定部23によって、ラベルあり文書データ及びラベルなし文書データの各々について、文書データに含まれる各単語について、単語の極性及び分野依存性を決定し、決定された極性及び分野依存性である確率を算出する。パラメータ更新部24によって、極性付き文書生成モデルのパラメータを更新する。そして、繰り返し判定部25によって、所定の収束条件を満たすまで、単語極性判定部23とパラメータ更新部24とを繰り返す。文書極性判定部26によって、その時点のラベルなし文書データの各単語について算出された確率に基づいて、各単語の極性を判定し、判定された各単語の極性に基づいて、ラベルなし文書データの極性を判定する。
(もっと読む)
電子書籍用目次生成システム

【課題】電子書籍において一般ユーザが興味のある分野に即した目次を新たに生成することができ、ひいてはユーザが興味のある分野に関する記事を効率的に閲覧することが可能な電子書籍用目次生成システムを提供する。
【解決手段】電子書籍用目次生成装置100は、一般ユーザの興味のある分野に即した複数のカテゴリと、各カテゴリに関連付けられた一ないし複数の所定の単語とから構成されるカテゴリ表を予め記憶しているカテゴリ記憶部110と、電子書籍のコンテンツデータから単語を抽出する単語抽出部130と、カテゴリ記憶部110のカテゴリ表を参照することにより、単語抽出部130により抽出された単語に基づいて複数のカテゴリを設定するカテゴリ設定部140と、カテゴリ設定部140により設定された複数のカテゴリを使用して電子書籍の目次を生成する目次生成部160とを備える。
(もっと読む)
高精度な類似検索システム
【課題】高精度な類似検索を実現する。
【解決手段】
pivot決定部によって登録用データからpivotを決定し、生データを取得し、前記生データから特徴量を抽出し、前記特徴量同士の距離或いは類似度としてスコアを計算し、前記pivotに対する前記スコアを用いて索引用ベクトルを生成し、前記索引用ベクトル同士の距離或いは類似度としてΔスコアを計算し、学習用データを用いて、回帰係数を含むnon−pivot毎のパラメータを学習し、検索用データと前記non−pivotとの前記Δスコアと前記回帰係数を用いて、ロジスティック回帰により事後確率の大きい順に前記non−pivotの選択順序を決定し、前記検索用データと前記登録用データとの前記スコアを基に、検索結果を出力する。
(もっと読む)
キーワード付与装置、コンテンツ提供システム、キーワード付与方法およびプログラム
【課題】受信するキーワード基づいてデータを返信するシステムにおいて、データ入力作業者の負担を軽減し、かつ、キーワードとデータとの対応付けを行えるようにする。
【解決手段】
対応関係取得部202が、広告情報マスタデータベース31のレコードと、製品情報マスタデータベース32のレコードとを、これらのレコードに格納されているデータの類否に基づいて対応付ける。そして、キーワード付与部203が、対応関係取得部202による対応付けに基づいて、広告情報マスタデータベース31に格納されている検索キーに、製品情報マスタデータベース32に格納されているキーワードを付与し、製品情報マスタデータベース32に格納されている検索キーに、広告情報マスタデータベース31に格納されているキーワードを付与する。
(もっと読む)
文書処理装置
【課題】特定フォーマットに依存せずに要求仕様書と自社技術体系とを比較し、要注意箇所または合致箇所を抽出することが課題となる。
【解決手段】評価対象である評価対象テキスト文書の記述内容が含まれる知識分野を構成する語句群における、相互の関連性が高い語句どうしをネットワーク接続した標準知識ネットワークデータを保持し、前記テキスト文書を構成する語句群について関連性の高い語句どうしをネットワーク接続した評価対象文書知識ネットワークデータを作成する文書知識作成機能を有し、評価対象文書知識ネットワークデータの構造と標準知識ネットワークデータの構造に対し、それらを構成する特定語句に着目し、当該特定語句にネットワーク接続している語句群の情報が相互に異なる場合に、当該特定語句の情報を含む差異情報とを出力する。
(もっと読む)
主題抽出装置、方法、及びプログラム
【課題】文書から主題を抽出する。
【解決手段】名詞句抽出部12で、具体主題の候補となる名詞句を抽出し、名詞句ペア作成部14で、名詞句ペアを作成する。名詞句頻度抽出部18で、名詞句各々の出現頻度、及び名詞句ペア各々の共起頻度を抽出し、出現確率勝敗算出部20で、名詞句各々の出現頻度及び名詞句ペアの共起頻度から求まる名詞句各々の出現確率を求め、名詞句ペアで出現確率に基づく勝敗を示す第1の素性を算出する。また、係り受け構造抽出部22で、名詞句ペアの係り受け構造毎の出現頻度を抽出し、係り受け関係勝敗算出部24で、名詞句ペアで係り先になり易さによる勝敗を示す第2の素性を算出する。素性ベクトル生成部26で、第1の素性及び第2の素性を並べた素性ベクトルを生成し、具体主題が既知の学習用文書に含まれる名詞句の素性ベクトルを用いて学習された分類器に入力して、具体主題を示す名詞句を抽出する。
(もっと読む)
閲覧情報生成装置および閲覧情報生成方法
【課題】予め準備された閲覧情報を、情報閲覧システムにおける閲覧情報群に適切かつ容易に配置することで、製作者の負担を軽減する。
【解決手段】閲覧情報生成装置300において、テキスト取得部322は、閲覧情報と閲覧情報を特定するための閲覧特定情報とを含むテキスト文を取得し、目的語決定部324は、閲覧特定情報から目的語を抽出し、代表目的語を決定する。述語決定部326は、閲覧特定情報から述語を抽出し、代表述語を決定する。階層特定部328は、マトリクステーブルを用い、代表目的語および代表述語に基づいて閲覧情報群のツリー構造の階層を特定する。テキスト配置部330は、特定された階層にテキスト文を配置する。
(もっと読む)
具体主題分類モデル学習装置、方法、プログラム、具体主題抽出装置、方法、及びプログラム
【課題】文書中の任意の数の具体主題を抽出する。
【解決手段】学習用名詞句抽出部14で、具体主題が既知の学習用文書から学習用名詞句を抽出し、学習用素性抽出部16で、各名詞句の学習用素性を抽出し、閾値生成部18で、正例の素性の平均と負例の素性の平均の平均を、具体主題を示す名詞句か否かを判定するための閾値として生成する。正例の素性を1位、閾値を2位、負例の素性を3位とする学習データでランキング型の分類モデルを学習する。具体主題が未知の文書が入力されると、分類用名詞句抽出部34で、分類用名詞句が抽出され、分類用素性抽出部36で、各名詞句の分類用素性が抽出され、分類モデルに、閾値及び各名詞句の分類用素性を入力し、閾値とのランキング比較で1位となる分類用素性に対応する名詞句を、具体主題を示す名詞句として抽出する。
(もっと読む)
苦情検索装置、苦情検索方法、及びそのプログラム
【課題】検索語により検索された苦情の内容(評価表現)に対応する苦情の対象(評価対象)の特定を深層的で比較的広い範囲に適用される規則により行い、より適切に文書から苦情の対象と内容との題述関係を抽出する。
【解決手段】入力文書から抽出された評価対象に該当する構文要素Wと前記入力文書から抽出された評価表現に該当する構文要素Enとの全ての組み合わせについて、各構文要素の概念ベクトルを用いて構文要素間の題述関係確率を求め、更にそれらの題述関係度を求め、この値に基づき題述関係にある評価表現と評価対象の組を特定する。
(もっと読む)
文書要約装置、文書要約方法、及びプログラム
【課題】意味の通らない要約が生成されることを抑制することができるようにする。
【解決手段】テキスト入力部1によって、複数の文で構成され、かつ、形態素解析済みのテキストを受け付ける。不完全文検出部2によって、テキストから、不完全文を検出し、不完全文連結部4によって、検出された不完全文を、不完全文より前に出現する完全文と連結するまで、一つ前の文と繰り返し連結する。テキスト要約部5によって、不完全文が完全文と連結されたテキストに対応する要約を生成する。
(もっと読む)
検索装置、検索方法及び検索プログラム
【課題】様々な文字コードで記載されたメタデータを検索する。
【解決手段】入力部11が入力したキーワードを、変換部12が対応辞書蓄積部121を用いてキーワードの文字を一字ずつ別の文字コードに変換し、検索部13が文字コードが変換されたキーワードを用いて対応するデータベースを検索する。これにより、入力されたキーワードの文字コードと異なる文字コードでデータベースにメタデータが格納されていても、キーワードやメタデータが辞書登録のない固有名詞や流行語、新語、造語などであっても検索することができる。
(もっと読む)
閲覧情報生成装置および閲覧情報生成方法
【課題】情報閲覧システムにおける閲覧情報群のうち、閲覧情報を追加、削除、編集したい階層を適切かつ容易に特定することで、製作者の負担を軽減する。
【解決手段】閲覧情報生成装置500において、対象語取得部522は、操作部を通じて目的語、述語、閲覧情報、閲覧情報を特定するための閲覧特定情報を取得する。階層特定部524は、マトリクステーブルを用い、目的語および述語に基づいて閲覧情報群のツリー構造の階層を特定する。テキスト配置部526は、特定された階層に閲覧特定情報および閲覧情報を関連付けて配置する。
(もっと読む)
具体主題の有無判定装置、方法、及びプログラム
【課題】文書が具体主題を有するか否かを判定する。
【解決手段】名詞句抽出部12で、具体主題の候補となる名詞句を抽出し、意味カテゴリ付与部18で、名詞句各々に意味カテゴリを付与し、エントロピー算出部20で、付与された意味カテゴリの偏りを示すエントロピーを第1の素性として算出する。また、視覚的特徴算出部24で、入力された文書が縦長か横長かを示す第2の素性を算出する。素性ベクトル生成部26で、第1の素性及び第2の素性を並べた素性ベクトルを生成し、具体主題が既知の学習用文書の素性ベクトルを用いて学習された分類器に入力して、入力された文書が具体主題を有するか否かを判定する。
(もっと読む)
データ入力支援装置、及びデータ入力支援方法
【課題】電話での応対業務等における、キーボード入力の負担を軽減することができる新しいデータ入力支援装置等を提供する
【解決手段】文章ごとに、属性情報、前記文章を構成する各単文、及び該各単文同士の繋がり情報を含むデータを格納するデータベースと、ユーザにより属性情報の入力を受け付ける入力部と、受け付けた属性情報を有するデータを、データベースから抽出し、該抽出されたデータそれぞれの単文を文リストとして選択可能に画面表示する制御部と、を備え、入力部は、ユーザ入力により画面表示された文リストから一単文の選択を更に受け付け可能であり、制御部は、文リストから一単文が選択された場合、該選択された一単文の次に繋がる可能性の高い単文を繋がり情報に基づいて画面表示する、データ入力支援装置。
(もっと読む)
ランキングモデル選択機能を有する文書検索装置、ランキングモデル選択機能を有する文書検索方法およびランキングモデル選択機能を有する文書検索プログラム
【課題】入力クエリに対して最適なランキングモデルを選択することができるランキングモデル選択機能を有する文書検索装置を提供する。
【解決手段】クエリ間の検索評価指標値(MAP値)から、クエリ間の類似度が高くなる変換行列を作成し、最大類似度を持つクエリのランキングモデルを、クエリに対する最適モデルとして最適モデルDB106に格納しておく。入力された検索クエリに対応する最適モデルを前記DB106から取得し、該最適モデルのクエリに対応する、ランキングモデルDB103内のスコア要因重みと、クエリ処理部150により算出された、検索結果集合とスコア要因を要素とするスコア要因値行列とを検索スコア計算部160で積算し、該算出された検索スコアの降順に入力検索クエリに対応する検索結果を提示する。
(もっと読む)
文字列検索装置
【課題】テキストファイルなどの検索対象から文字列を一度に複数種類検索して、極めて簡単な操作入力により、検索した文字列を区別して表示することができる文字列検索装置を提供する。
【解決手段】検索対象から文字列を検索する文字列検索装置1は、文字列の検索結果を表示する表示部20と、操作入力を受け付ける操作部30と、操作部30に対する押圧荷重を検出する荷重検出部60と、荷重検出部60が所定の基準を満たす押圧荷重を検出したら、検索した文字列を表示するように表示部20を制御する制御部と、を備えることを特徴とする。
(もっと読む)
データ処理装置
【課題】文書に書き込まれたアイデア等の情報がどの参照データを見て発案されたものかを後から確認可能に情報を記録するデータ処理装置を提供する。
【解決手段】作成中の文書と参照データ36とを表示部11に表示した状態(P11)で所定の操作(スタイラスペンで特定の軌跡が描かれるなど)を受けると(P12)、その参照データの表示後に書き込まれた最新の情報の文書内での書き込み位置42と参照データ36とを関連付ける紐付け情報を生成し、作成された文書と生成された紐付け情報とを関連付けて記憶装置に保存する。後に文書を表示したとき、紐付け情報に基づき、文字等の情報が書き込まれた位置とその情報を書き込んだときに参照していた参照データとを線で結んで表示するなどが可能になる。
(もっと読む)
閲覧情報編集装置および閲覧情報編集方法
【課題】情報閲覧システムにおけるツリー構造の全体的な構成と個々の選択肢の状態とを、直感的かつ一見しただけで把握させることができ、製作者の負担を軽減する。
【解決手段】閲覧情報編集装置300において、操作部310は、ユーザの操作入力を受け付ける。選択肢選択部320は、閲覧情報群200を表示部312に表示させ、操作部を通じて選択肢204を選択させる。総数導出部322は、選択された選択肢204の下位に存在する選択肢および閲覧情報202の総数を導出する。表示態様決定部324は、選択された選択肢の表示態様を、総数に応じて予め定めた表示態様に決定する。表示実行部326は、選択された選択肢を、決定された表示態様で表示部に表示させる。
(もっと読む)
文書間類似度算出装置、文書間類似度算出方法、及び、文書間類似度算出プログラム
【課題】文書間の類似度を算出する際の負荷が過大となることを防止しながら、高い精度にて類似度を算出することが可能な文書間類似度算出装置を提供すること。
【解決手段】装置100は、複数の文書のそれぞれが含む文毎に、当該文を構成する文字の総数をNにより表した場合に、0からN−1までの整数iのそれぞれに対する、当該文の先頭からi文字を除いた残余の文字列である接尾部を表す情報である接尾部情報を生成し(101)、接尾部の中から、複数の文に基づいて生成された接尾部を基準接尾部として選択し(102)、複数の文書のそれぞれに対して、当該文書が基準接尾部のそれぞれを含むか否かを表す類似度基礎情報を生成し(103)、第1の文書に対して生成された類似度基礎情報と、第2の文書に対して生成された類似度基礎情報と、に基づいて、第1の文書と第2の文書とが類似している程度を表す類似度を算出する(104)。
(もっと読む)
インタビュー支援装置、方法及びプログラム
【課題】インタビューすべき項目の漏れを少なくするインタビュー支援技術を提供する。
【解決手段】インタビュー支援装置は、インタビューの少なくとも一部の内容を示すテキストデータを品詞毎に分割する手段と、分割された複数の単語の中からキーワードを抽出する手段と、上記インタビューにおいて聴取されるべき項目毎に、当該項目に関するインタビューで聴取される内容に含まれる可能性の高い単語である代表語をそれぞれ保持する手段と、上記キーワードと上記代表語とを比較することにより当該キーワードに対応する項目を抽出する手段と、インタビューにおいて聴取されるべき各項目を示すデータと、抽出された項目と、を比較することにより、上記インタビューにおいて未だ聴取されていない項目を特定する手段と、この特定された未だ聴取されていない項目を示す情報が出力されるように制御する手段と、を備える。
(もっと読む)
41 - 60 / 3,390
[ Back to top ]