
Fターム[5B075ND03]の内容
Fターム[5B075ND03]に分類される特許
81 - 100 / 3,390
製造プロセスにおける知識情報抽出装置、方法及びプログラム
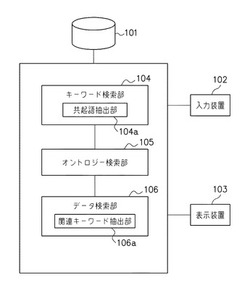
【課題】過去の大量の操業日誌の中からある概念について検索する際に、関係する概念も考慮できるようにする。
【解決手段】操業者が個別具体的な事項を記述することのできる特記欄207を有する操業日誌のデータが蓄積されたデータベース101を用いて知識情報を抽出する製造プロセスにおける知識情報抽出装置であって、予め構築されたオントロジーに定義された概念が入力されると、前記入力された概念に基づいて、データベース101に蓄積された操業日誌の特記欄を対象に検索を実行し、前記入力された概念を特記欄207に含む操業日誌の一覧、或いは、前記入力された概念及びそれに所定の関係があると定義された概念を特記欄に含む操業日誌の一覧を表示装置103に表示する。また、前記入力された概念に対して関係があると定義された概念を表示装置103に表示する。
(もっと読む)
ユーザの行動文から結果イベントを予測する予測プログラム、予測装置及び方法

【課題】文に記述されたユーザの日常的な行動イベントに起因して、その習慣に起因する将来的に生ずるであろう結果イベントを予測する予測プログラムを提供する。
【解決手段】ユーザの行動文の中から、イベント表現を抽出し、そのイベント表現とその記述時刻との組からなる「イベント」の集合を抽出するイベント集合抽出手段と、複数の同一のイベント表現を習慣イベントとして抽出する習慣イベント抽出手段と、多数のイベント表現を要素とした「特徴ベクトルの要素」が予め設定されており、習慣イベント毎に、該当する要素の有無を指定した「特徴ベクトル」を生成する特徴ベクトル生成手段と、結果イベント毎に予め学習された特徴ベクトル群を蓄積している予測モデル蓄積手段と、生成された特徴ベクトルが、予測モデル蓄積手段に蓄積された結果イベント毎の特徴ベクトル群のいずれに属するか否かを判定する予測判定手段とを有する。
(もっと読む)
特徴語抽出装置、プログラム及び方法
【課題】テキストマイニングの対象となる文書のデータに対して適切な語の区切りを自動的に設定する。
【解決手段】本特徴語抽出装置は、複数の文書のデータが格納されている文書格納部と、当該複数の文書のデータのうち第1の文書のデータにおける文節の各々を、区切り位置及び区切りの数を変化させつつ分割し、当該分割により得られた文字列をデータ格納部に格納する生成部と、データ格納部に格納されている文字列の各々について、当該文字列が第1の文書のデータに出現する回数と文書格納部に格納されている複数の文書のデータのうち当該文字列が出現する文書のデータの件数とを用いて特徴度を算出する算出部と、第1の文書のデータにおける文節の各々について、当該文節についての文字列のうち特徴度が最も高い文字列を特定し、特徴語格納部に格納する特定部とを有する。
(もっと読む)
回答検索装置、方法、及びプログラム
【課題】ユーザの入力単語の理解を支援することができる。
【解決手段】回答検索装置は、クラス抽出部、単語検索部、構文パターン格納部、テンプレート生成部、及び比喩表現検索部を含む。クラス抽出部は、入力された第1単語の分類を示すクラスを抽出する。単語検索部は、第1単語と異なり、かつ、クラスと同一のクラスに属する第2単語を検索する。構文パターン格納部は、第1単語、少なくとも1つの第2単語、および第2単語を形容する任意の文字列を当てはめて第1単語を比喩する比喩表現において、第1単語、第2単語、および任意の文字列が不定である構文パターンを格納する。テンプレート生成部は、構文パターンに第1単語と第2単語とを当てはめて任意の文字列が不定である比喩表現テンプレートを生成する。比喩表現検索部は、比喩表現テンプレートと一致する文字列をテキストデータから検索して、比喩表現として取得する。
(もっと読む)
編集支援装置、編集支援方法および編集支援プログラム
【課題】 複数のページ間で整合した文書データを生成すること。
【解決手段】 PCは、キーセンテンスを受け付けるキーセンテンス受付部11と、キーセンテンスに基づいてページデータを生成するページデータ生成部17と、ページデータから所定の条件に適合する文字列をキーワードとして抽出するキーワード抽出部25と、抽出された少なくとも1つのキーワードのうちから選択された1以上を登録キーワードに設定するキーワード設定部27と、登録キーワードが設定された後に、ページデータ生成部により生成される新たなページデータにおいて、1以上の登録キーワードそれぞれが出現したか否かに基づいて、ページデータ生成部17により生成された複数のページデータの整合性を判定する判定部31と、判定部31により不整合と判定される場合、警告する警告部37と、を備える。
(もっと読む)
文章作成支援プログラム、文章作成支援システム、情報記憶媒体及び文章作成支援方法
【課題】状況や場面等に応じて用意された同じ又は類似の内容で表現形式の異なる複数の例文をすばやく取り出し、参考にして文章を作成することができるツールを提供すること。
【解決手段】本文章作成支援プログラムは、文章データを検索するための文章検索条件に関する情報に関連づけて、同じ又は類似の内容で表現形式の異なる所定の言語の複数の例文を含む文章データを記憶する文章データ記憶部と、所定の文章作成支援画像を提供し、前記文章検索条件に関する情報を取得し、前記文章データ記憶部から、取得した前記文章検索条件に対応する文章データを読み出す文章検索処理部と、読み出した文章データの前記複数の例文の少なくともが1つが表示される文章表示領域を含む文章作成支援画像を生成し、表示部に提供する表示制御処理部と、してコンピュータを機能させる。
(もっと読む)
データ抽出装置、データ抽出方法、及びプログラム
【課題】人手による修正コストを小さくし、かつ、セマンティックドリフトを効率的に軽減する
【解決手段】正例エンティティに対応する正例トピック情報を正例エンティティの素性の少なくとも一部とし、負例エンティティに対応する負例トピック情報を負例エンティティの素性の少なくとも一部とし、正例エンティティの素性と負例エンティティの素性とを教師あり学習データとした学習処理によって識別モデルを生成し、対象エンティティに対応するトピック情報を当該対象エンティティの素性の少なくとも一部とし、対象エンティティが正例エンティティか負例エンティティかを識別する。また、トピック情報の関する情報を人手によって修正する。
(もっと読む)
文書検索装置、文書検索方法、及び文書検索プログラム
【課題】効率の良い文書の検索、および、ユーザへの適切な検索結果の出力を実現することでユーザの作業効率の向上を可能とする。
【解決手段】本実施形態の文書検索装置は、構造化文書データと、構造化文書データに含まれる語句毎の、抽出元の構造化文書データの識別子と抽出元の構造化文書データにおける属性とを含む抽出語句情報と、属性毎の検索方式と表示方式とを含む検索表示方式判定ルールとを記憶する記憶装置を備える。また、本実施形態の文書検索装置は、検索語句を入力し、検索語句と一致する語句が抽出語句情報に存在する場合に、抽出語句情報を参照して検索語句の属性を判定し、判定した属性に基づいて検索表示方式判定ルールを参照して構造化文書データを検索する検索方式と検索結果の表示形式とを判定し、判定された検索方式によって検索語句に基づく文書検索を行い、判定された表示形式によって検索結果を出力する。
(もっと読む)
核酸情報処理装置およびその処理方法
【課題】DNAマイクロアレイに相当する使用有効期限のないプローブセットを用いて容易にハイブリダイゼーション結果を得る装置を提供する。
【解決手段】インポートデータ1には、シークエンサーから出力されたターゲットのフラグメント塩基配列情報であるシークエンス・データおよびDNAチップを用いた実験で得られたDNAチップ実験データがインポートされ、処理機能2は、インポートしたシークエンス・データおよびDNAチップ実験データならびにこれらを用いて行う様々な解析結果を格納しておくデータベース3を利用し、シークエンス・データをクラスタリング処理する機能、クラスタリングされたデータに基づいてデジタルDNAチップを設計するデジタルDNAチップ設計機能、プローブの塩基配列リストとの類似度およびその頻度を解析する仮想ハイブリダイゼーション機能、複数の類似塩基配列の頻度解析結果を比較する機能と、を備える。
(もっと読む)
要求獲得支援装置、要求獲得支援方法、およびプログラム
【課題】各種システムやソフトウェアに対する顧客からの要求をより確実に獲得することができる要求獲得支援装置を提供する。
【解決手段】要求獲得支援装置として、ヒアリング案件に関する要求関連文書データを入力する情報登録手段と、要求関連文書データ文章中の多義的に捉えられ得る曖昧ポイントを抽出し、抽出した個々の曖昧ポイントについて曖昧性の特徴に基づく曖昧性の種類を示す曖昧性分類を決定する要求関連文章分析手段と、要求関連文書データの曖昧性をヒアリング実施者の立場から定量化して要件把握性として定義する要件把握性評価手段と、要求関連文書データにおける個々の曖昧ポイントについて、曖昧性分類と要件把握性に基づき分析して、質問に適したヒアリング時に提供するヒアリングアドバイスを候補から選択するヒアリングアドバイス分析手段と、選択されたヒアリングアドバイスを表示するヒアリングアドバイス表示手段とを設ける。
(もっと読む)
関連コンテンツ検索装置及びプログラム
【課題】ユーザの嗜好に合致したコンテンツを新たな視点から検索する。
【解決手段】関連コンテンツ検索装置1のコンテンツ記憶部11は、各コンテンツの内容を表した情報テキストを記憶しており、書き込み受信部19は、複数のユーザ端末2からコンテンツに対する書き込み内容を受信して書き込み記憶部12に書き込む。キーテキスト生成部15は、ユーザ端末2へ配信しているコンテンツに対する書き込み内容を書き込み記憶部12から読み出してキーテキストを生成し、検索部16は、キーテキストとコンテンツ記憶部11に記憶されている各コンテンツの情報テキストとの類似度を算出し、算出された類似度に基づいて関連コンテンツを選択する。画面生成部17は、コンテンツと、コンテンツに対する書き込み内容と、関連コンテンツの代表画像データとを表示する画面データを生成し、配信部18は、生成された画面データをユーザ端末2に配信する。
(もっと読む)
計算機、文書提示方法及び文書提示プログラム
【課題】情報の取捨選択の有効な判断材料となる見出しを付与した文書を提示する計算機を提供する。
【解決手段】文書を格納する文書データベースに接続された計算機であって、プロセッサは、文書データベースに格納された文書に含まれる単語間の因果関係を抽出し、抽出された単語間の因果関係をネットワーク構造で表した因果ネットワークデータを作成し、因果ネットワークデータから、利用者が興味を持っている単語である興味語と因果関係にある単語を抽出し、興味語を第1ワード、抽出された単語を第2ワードとした場合における第1ワードと、第2ワードとに基づいて、文書の見出しを作成し、作成された見出しが付与された文書を、出力装置を介して利用者に提示するためのデータを生成する。
(もっと読む)
情報取得装置
【課題】 質問と回答の対で構成されるテキストデータから有用な情報を抽出する。
【解決手段】 質問と回答の内容をそれぞれ解析し、それらの解析結果を組合せることで有用な情報を抽出する。具体的には、質問と回答の対から成るテキストデータを入力する入力手段と、前記テキストデータから情報を抽出する情報抽出手段と、前記情報抽出手段が抽出した結果を出力する出力手段とを備え、前記情報抽出手段は、上記入力手段による入力の質問部分テキストを解析する質問テキスト解析手段と,同入力の回答部分テキストを解析する回答テキスト解析手段と,上記質問テキスト解析手段と上記回答テキスト解析手段の解析結果からテキストの適合判定を行う適合テキスト判定手段を含む、情報取得装置とする。
(もっと読む)
情報処理装置、情報処理方法及びプログラム
【課題】単純な感想ではない作為的な意図が組み込まれたテキストを判別し、かかる作為的な文章が表示されてしまうことを防止することが可能な、情報処理装置、情報処理方法及びプログラムを提供すること。
【解決手段】本発明に係る情報処理装置は、評価対象事象に対する評価者の意見が記載されたテキストデータと、当該テキストデータに関するメタデータとを少なくとも含むテキスト関連データ群に基づいて、評価者の意見に含まれる当該評価者の意図、及び、評価対象事象の内容に依存しない評価者の意見の特徴に関する特徴量を算出する特徴量算出部と、算出された特徴量に基づいて、テキストデータを、評価者が作為的に生成した意見が記載された作為テキストと、評価者が作為的に生成した意見を含まない非作為テキストとに分類し、評価者の意見を閲覧する閲覧者に表示するテキストデータを選択する表示テキスト選択部と、を備える。
(もっと読む)
コード列検索装置、検索方法及びプログラム
【課題】コード列の最長一致検索をカップルドノードツリーを用いて実現する。
【解決手段】カップルドノードツリーの構造を、検索対象コード列を後続するコードの有無を示す識別ビットとコードに対応するビット列の組み合わせで符号化したインデックスキーの差分情報を登録したものとし、検索キーを検索対象コード列と同様に符号化した符号化検索キーにより検索するとともに、検索の過程でたどった経路をスタックに記憶する。符号化検索キーによる検索結果のコード列とスタックに記憶した検索経路の情報によりアクセスする検索対象コード列から最長一致キーを探索する。
(もっと読む)
文字列検索装置,文字列検索方法および文字列検索プログラム
【課題】認識結果である検索対象データに対するあいまい検索において,検索ノイズを減らすことにより,検索精度を向上させる技術を提供する。
【解決手段】検索実行部13は,文字認識,音声認識,点字認識などの認識結果である検索対象データに対して,検索キーワードを用いたあいまい検索を行う。検索結果は,検索結果記憶部14に記憶される。一致判定部15は,検索結果文字列が検索キーワードに完全一致するか否かを判定する。認識誤り評価部16は,検索結果文字列が検索キーワードと完全一致しない場合に,検索結果文字列に認識誤りが発生している可能性を判断する。除外部17は,検索結果文字列に認識誤りが発生していないと判断された場合に,検索結果文字列を検索結果から除外する。除外部17は,検索結果記憶部14から,除外となった検索結果文字列を削除する。
(もっと読む)
データ抽出装置、データ抽出方法、及びプログラム
【課題】効率的にセマンティックドリフトを軽減する。
【解決手段】正例エンティティとその属性とのペアの素性と、負例エンティティとその属性とのペアの素性とを教師あり学習データとした学習処理によって識別モデルを生成し、対象エンティティと対象属性とのペアの素性を識別モデルに入力して、対象エンティティが正例エンティティを識別する。この際、対象属性が正例か否かの判定結果を出力し、人手による修正内容の入力を受け付ける。人手による修正内容を利用して正例属性を定める。
(もっと読む)
文書検索装置
【課題】ユーザが、文書に含まれるページのうちの、ユーザにとって重要な情報を含むページを容易に閲覧することが可能な文書検索装置を提供すること。
【解決手段】文書検索装置100は、各々が複数のページを含む、複数の文書の中から、所定の検索条件を満足する文書を抽出する文書抽出部101と、上記抽出された文書のそれぞれに対して、当該文書に含まれるページのうちの、所定の重要条件を満足するページを重要ページとして特定する重要ページ特定部102と、上記特定された重要ページを識別するためのページ識別情報と、当該重要ページを含む上記文書を識別するための文書識別情報と、を含む重要ページ特定情報を出力する重要ページ特定情報出力部103と、を備える。
(もっと読む)
トピック作成支援装置、トピック作成支援方法およびトピック作成支援プログラム
【課題】トピック作成の作業負担を軽減し、且つ、トピックの質を均質化すること。
【解決手段】トピック作成支援装置1は、ニュース記事情報記憶手段2から見出しを構成する見出し情報を抽出し、抽出された見出し情報を文節で区切って、複数の文節要素に分割する。そして、トピック作成支援装置1は、分割された各文節要素に対して、少なくとも品詞の特性或いは品詞の活用に応じて予め定められた重み付け判定データに基づいて、重み付けを行い、重み付けされた文節要素のうち、重み付けの度合いが大きい文節要素を抽出する。そして、トピック作成支援装置1は、抽出された文節要素の文字数が13文字以下である場合には、抽出された文節要素を文章情報のトピック候補としてディスプレイ3に出力する。
(もっと読む)
関連語グラフ作成装置、関連語グラフ作成方法、関連語提供装置、関連語提供方法及びプログラム
【課題】概念階層を定義するシソーラスにコーパスに含まれる単語間の関係を定義するトピックグラフを組み合わせることができるようにする。
【解決手段】検索装置20は、単語の概念階層を定義するシソーラス11を記憶するシソーラスデータベース231、コーパスに含まれる単語間の関係を定義するトピックグラフ12を記憶するトピックグラフデータベース232、ディレクトリ検索に用いられるカテゴリの階層を定義するカテゴリグラフを記憶するカテゴリグラフデータベース233を備える。検索装置20は、カテゴリグラフ13に含まれるノードと、シソーラス11に含まれるノードとがリンクされ、カテゴリグラフ13に含まれるノードと、トピックグラフ12に含まれるノードとがリンクされるように、シソーラス11、カテゴリグラフ13、及びトピックグラフ12を組み合わせて、グラフ構造の関連語グラフ10を作成する。
(もっと読む)
81 - 100 / 3,390
[ Back to top ]