
Fターム[5B013AA18]の内容
Fターム[5B013AA18]に分類される特許
1 - 20 / 87
データ処理装置およびデータ処理方法およびプログラム
【課題】演算部の演算開始タイミングを変化させてデータ処理を行うデータ処理装置を実現する。
【解決手段】メモリ400aは、先行して演算を実行する処理部200aが生成したデータを蓄積する。メモリ監視部450は、メモリ400aが蓄積するデータのデータ数を監視し、後続して演算を実行する処理部200bが演算に必要なデータ数が蓄積されたら、メモリ400aが蓄積するデータを処理部200bに出力させる。処理部200bはデータが出力されるタイミングで演算を開始し、データが出力されるタイミングの変化に対応して、処理部200bの演算開始タイミングが変化する。
(もっと読む)
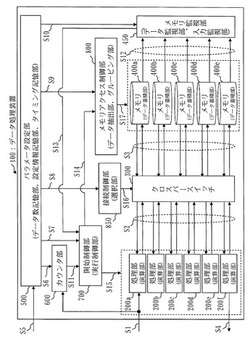
画像処理装置及びプログラム

【課題】画像データの処理において、分岐処理要素の追加が要求された場合に生じるメモリ量増加または処理速度低下の低減を図る。
【解決手段】末端処理要素となっている分岐処理要素Exを対象にN個の分岐処理要素Eyの追加が要求された場合に、分岐可能条件が満足されていれば、制御部は、分岐処理要素Exの前段の画像処理要素Ezの後段に「N−1」個の分岐処理要素Eyを連結する(S402)。一方、分岐可能条件が満足されていなければ、制御部は、分岐処理要素Exの後段にN個の分岐処理要素Eyを連結する(S403)。
(もっと読む)
情報処理装置、情報処理方法
【課題】各プロセッサ間で効率的に演算結果を共有可能な情報処理装置を提供する。
【解決手段】プログラムを記憶するプログラム記憶手段11と、コア毎の演算結果を記憶する演算結果記憶手段45と、コア数分の命令の命令セットを実行順にプログラム記憶手段から読み出し一次記憶部に記憶する命令読み出し手段21と、命令セットに含まれる命令を各コアの命令キューに記憶する命令配信手段32と、一次記憶部に記憶された第一の命令セットに含まれる命令を第一のコアが演算した演算結果を演算対象とする命令が第一の命令セットよりも後に実行される第二の命令セットに含まれ第一のコアと異なる第二のコアが実行するか否かを判定する命令依存関係判定手段33と、命令依存関係判定手段が第二のコアが第二の命令セットに含まれる命令を実行すると判定した場合第一のコアの演算結果記憶手段の値を第二のコアの演算結果記憶手段に複写する複写手段34と、を有する。
(もっと読む)
プロセッサシステム及び半導体集積装置
【課題】処理速度の低下を最低限に抑えかつ従来技術に比較して消費電流の変動を抑える。
【解決手段】プロセッサシステム1は、プログラムメモリ2に格納された複数の命令コードを任意の順序で連続して実行する。テーブルメモリ53は、各命令コードと各命令コードの実行時の消費電流量との関係を示す消費電流量テーブルを格納する。電流変動抑制回路51は、消費電流量テーブルを参照して、連続する2つの命令コードの実行時の消費電流量の差の大きさが所定のしきい値以下になるように、上記連続する2つの命令コードのうちの一方の命令コードの実行時にプロセッサシステム1に流す補正消費電流を算出し、上記算出された補正消費電流量の補正消費電流をプロセッサシステム1に流すように、補正消費電流発生回路54を制御する。
(もっと読む)
ディジタル信号処理装置
【課題】積和演算の処理能力を向上する。
【解決手段】ディジタル信号処理装置は、複数のレジスタと、クロック信号に同期して時系列的に前記複数のレジスタにデータを格納するデータ転送部と、同じタイミングで前記複数のレジスタに格納されたデータに対して演算を実行する演算部とを備える。前記データ転送部は、与えられた命令に応じて、前記クロック信号の或るタイミングで前記複数のレジスタのうちの或るレジスタに格納された前記データを、次のタイミングで前記複数のレジスタのうちの指定された他のレジスタに格納するように転送する。SIMDによるフィルタ演算の処理能力を向上することができる。
(もっと読む)
演算装置
【課題】演算資源の利用効率を向上させるとともに、命令の処理に要する時間が増大することを防止可能な処理装置を提供する。
【解決手段】本実施形態の演算装置100は、プログラムメモリ21と、命令フェッチ部22と、デコード部24とを備える。プログラムメモリ21は、データメモリ40から所定のデータを読み出すメモリアクセス処理を、パイプライン処理の相互に異なるステージで実行する命令Aおよび命令Bを記憶する。命令フェッチ部22は、命令Aおよび命令Bを同時にフェッチする。デコード部24は、フェッチされた命令Aおよび命令Bを同時にデコードする。
(もっと読む)
情報処理装置、キャッシュ装置およびデータ処理方法
【課題】パイプラインを用いて処理を行う情報処理装置において、繰り返し必要とされるデータが情報処理装置から破棄されないように、置き換え制御を工夫しておこなうことで、より効率的な技術を提供する。
【解決手段】情報処理装置は、第1パイプラインと第2パイプラインと処理手段とリオーダ手段とを有する。第1パイプラインは、複数の第1ノードを有し、当該第1ノードに対して第1方向にある第1ノードへ当該第1ノードの保持する第1データを移動させ、第2パイプラインは、第1パイプラインの第1ノードの各々に対応する複数の第2ノードを有し、当該第2ノードに対して第1方向と逆の第2方向にある第2ノードへ当該第2ノードの保持する第2データを移動させ、処理手段が、第1データと第2データとを用いてデータ処理を行い、
リオーダ手段が、第2パイプラインの出力した第2データの属性情報に基づき、出力した第2データの何れかを保持し、保持した第2データを第2パイプラインに入力する。
(もっと読む)
サブワード実行を用いるVLIWベースのアレイプロセッサで条件付き実行をサポートする方法及び装置
【課題】複合条件に基づくサブワード並列実行をサポートする。
【解決手段】汎用フラグ(ACF)は階層を使用して定義され、エンコードされる。加えられた各ビットは、前の機能性のスーパーセットを提供する。条件の組合せを用いて、複合条件に基づく条件付き分岐の順次シリーズを回避することができ、次いで複合条件を条件付き実行のために使用することができる。フラグの数を変えることによって、条件付きオペレーションの並列性は、例えばVLIW実行での単一の処理からオクタル処理まで、かつ処理要素のアレイにわたって広範に変化することができる。異なるプロセッサ中で生成された条件に基づいて1つのプロセッサ中の条件付き実行を指定することを可能にして、多数のPEは、条件情報を同時に生成することができる。多数のプロセッサアレイ中の各プロセッサは、異なるユニットをそれらのACFに基づいて条件付きで独立に動作させることができる。
(もっと読む)
演算割当装置、演算割当方法及び演算割当プログラム
【課題】複数の演算器をアレイ状に組合せ、演算器間の接続をセレクタで切り替えることにより、演算器の構成を切り替えて動作させる再構成可能な演算装置に対して、人手による設計を介在させることなく、結線が可能な演算の割り当てをすることを目的とする。
【解決手段】複数の演算器を有する演算ブロックを複数備える演算装置であって、各演算ブロックにおける演算器間の結線と演算ブロック間の結線とを切り替え可能な演算装置に対して、一連の演算を各演算ブロックに割当可能な単位に分割し、分割した演算をそれぞれ異なる演算ブロックの演算器に割り当てる。
(もっと読む)
プロセッサ構成設定をオーバーライドする方法
【課題】プロセッサの構成を、実行中にユーザレベルで変更し、パフォーマンスを向上させる。
【解決手段】プロセッサ機構に対応するオーバーライドレジスタのエントリを、そのプロセッサ機構に対するプロセッサ構成設定をオーバーライドするようにセットし、そのエントリを使用してプロセッサ機構に対するプロセッサ構成設定をオーバーライドする方法を含む。エントリを、たとえばユーザレベルアプリケーションでセットしてもよい。
(もっと読む)
情報処理装置
【課題】加算及び論理の組み合わせ以外の演算に対して演算器カスケードの遅延時間の増大を抑えることが可能な情報処理装置を提供する。
【解決手段】情報処理装置は、複数の演算器と、複数の命令を複数の演算器に対して同時並列に発行する命令発行部とを含み、複数の演算器の少なくとも1つの演算器は、シフト演算を実行するシフト回路と、2つのシフト命令のシフト数を加減算するシフト数生成回路とを含み、シフト数生成回路により求めたシフト数に応じてシフト回路によるシフト演算を実行することにより、データ依存関係のある2つのシフト命令を1回のシフト演算で実行する。
(もっと読む)
画像処理装置、画像形成システム及び画像処理プログラム
【課題】 複数のDRPがパイプライン処理方式によって実行する場合に、上位制御装置からDRPの識別がつくように各DRPに識別番号が割り付けられ得る画像処理装置を提供する。
【解決手段】 入力された印刷ジョブに基づく画像処理を複数のDRP61〜68にパイプライン処理方式によって実行させる場合に、複数のDRP61〜68の個数に基づいて、識別番号をこれらのDRPに割り付ける識別番号割付部32aと、複数のDRP61〜68の中の最終段のDRP68が、画像処理の処理結果を外部に出力する印刷データ出力部13と接続されているか否かに基づいて、識別番号割付部32aによる割付処理を変更する割付処理第1変更部32bと、印刷データ出力部13と接続されていない場合に、複数のDRP61〜68が1枚の基板にのみ設置されているか否かに基づいて、識別番号割付部32aによる割付処理をさらに変更する割付処理第2変更部32cとを有する。
(もっと読む)
改善された計算アーキテクチャ用パイプライン加速器、関連システム、並びに、方法
【課題】プロセッサに基づくマシンの意思決定を為す能力を、ハードウェアに組み込まれたパイプラインに基づくマシンのナンバークランチング速度と組み合わせることを可能とする新しい計算アーキテクチャを実現する。
【解決手段】パイプライン加速器44に組み込まれたパイプライン回路は、データを受信し、前記データをメモリにロードし、メモリからデータを検索し、検索されたデータを処理し、そして処理されたデータを外部ソースに提供するように動作できる。加えて、パイプライン回路は、受信されたデータを処理することもできる。パイプライン加速器がピア-ベクトル・マシン40の一部としてのプロセッサと結合されている場合、メモリはパイプライン回路とプロセッサが実行するアプリケーションとの間におけるデータの転送を補助する。
(もっと読む)
演算処理装置、情報処理装置及び演算処理装置のパイプライン制御方法
【課題】 パイプライン部の負荷分散を効率的に行う演算処理装置を提供することを目的とする。
【解決手段】 入力される第1の命令を実行する第1のパイプライン部と、入力される第2の命令を実行する第2のパイプライン部と、第1のパイプライン部が第1の命令を完了できない場合又は第2のパイプライン部が第2の命令を完了できない場合に、完了できない第1の命令又は第2の命令を登録する登録部と、第1のパイプライン部と第2のパイプライン部とのうち、負荷が低いパイプライン部を決定する決定部と、登録部に登録された命令を、決定部が決定したパイプライン部に入力する入力部とを有する。
(もっと読む)
信号処理装置
【課題】所望の処理性能を満足した上で、低消費電力化を図ることができるようにする。
【解決手段】各ロジック部11における許容処理時間と各ロジック部11の処理時間を比較し、その比較結果を参照して、複数のロジック部11間の接続箇所毎に、挿入されているフリップフロップ12を省いて、その接続箇所における前段のロジック部11と後段のロジック部11を直結するか否かを判定するパス長判定部を設け、セレクタ13がパス長判定部により直結する旨の判定がなされた接続箇所では、挿入されているフリップフロップ12を省いて、その接続箇所における前段のロジック部11と後段のロジック部11を直結する。
(もっと読む)
情報処理装置、情報処理方法及び情報処理プログラム
【課題】動作クロックが向上してビジーフラグの更新が遅れる場合でも、パイプライン演算器の使用効率を低下させずに処理できる情報処理装置を提供する。
【解決手段】第1命令部202は、第1命令をパイプライン処理実行部へ発行し、第1命令の情報である命令発行確定信号を第2命令部203へ出力する。第2命令部203は、第1命令よりも優先順位の低い第2命令を格納する命令発行キューと、命令発行確定信号に基づいて第1命令の演算器使用サイクル数が1であると判定した場合、処理サイクル数1信号を出力する直前命令処理数認識部と、処理サイクル数1信号を受け取り、命令発行抑止信号を出力しないように制御する命令発行抑止信号生成部とを備える。第2命令部203は、第1クロックで命令発行抑止信号を出力しないことによって、第1クロックに連続する第2クロックで、パイプライン処理実行部へ第2命令を発行する。
(もっと読む)
メモリ・ボトルネックが無い、低エネルギー消費で高速計算機
クロック信号を生成するクロック発生回路を有する制御装置(111)、及び、クロック信号に同期した演算論理動作を実行するALU(112)を含むプロセッサ(11)と、それぞれ一組の情報群を格納したメモリユニットのアレイ、このアレイの入力端子及び出力端子を有し、情報をメモリユニットのそれぞれに格納し、且つ、クロック信号に同期して、ステップごとに、出力端子の方向に転送し、格納された情報をプロセッサ(11)に能動的に逐次出力し、ALU(112)が演算論理動作を、格納された情報により実行可能であり、更に、命令の転送の場合には、プロセッサ(11)に向かう命令の流れのみを一方向に規定して、ALU(112)の処理の結果が入力されるマーチング主記憶装置(31)とを備える計算機システムである。  (もっと読む)
(もっと読む)
共用メモリ配線を有する暗号化プロセッサ
【課題】さまざまな秘密鍵および公開鍵の暗号化アルゴリズムを処理するようプログラム可能な暗号化チップを提供する。
【解決手段】暗号化チップは、演算処理装置のパイプラインを含み、該演算処理装置の各々は、秘密鍵アルゴリズム内の1ラウンドを処理することが可能である。データは、該演算処理装置間で、デュアルポートメモリを介して転送される。中央処理装置は、単一サイクルのオペレーションで、グローバルメモリからの非常に幅の広いデータ語を処理することができる。加算器回路は、比較的小さい複数の加算器回路を使用することによって簡素化され、合計およびキャリが複数サイクルでループバックされる。乗算器回路は、非常に幅の広い中央処理乗算器となるよう連結することができるように、より小さい演算処理装置乗算器を適用することによって、複数の演算処理装置と中央処理装置との間で共用することができる。
(もっと読む)
デッドロックを起こさないパイプライン処理のためのシステム及び方法
【課題】デッドロック無くグラフィック処理を増大させる。
【解決手段】実行ユニットのパイプライン結果(例えば、テクスチャーパイプライン結果)用の記憶スペースを提供する。この記憶スペースにより、テクスチャーユニットを利用して情報を記憶することができ、一方、レジスタファイルの対応する位置が他のスレッドへの再割当てのために使用できるようになるので、複数のスレッドの処理を増大させることができる。更に、要求の数を制限し、要求のセットのうちの各要求を完了するのに使用可能なリソースがない限り、その要求のセットが発せられないようにすることにより、デッドロックを防止する。
(もっと読む)
大命令幅プロセッサにおける処理効率の向上
1つ以上の処理ユニット(40)と、実行パイプライン(32)と、制御回路(28)とからなるプロセッサ(20)。実行パイプラインは、少なくとも段階を成す第1と第2のパイプラインステージを有し、パイプラインの連続するサイクルの中で処理ユニットにより遂行される動作を特定するプログラム命令が、第1のパイプラインステージによりメモリから取得され、そして前記第2のパイプラインステージに運ばれ、第2のパイプラインステージは処理ユニットに対し特定の動作を遂行するようにさせる。制御回路は、パイプラインの第1のサイクルにおいて第2のパイプラインステージ内に存在するプログラム命令が、パイプラインの次のサイクルにおいて再び実行されると判定した時に、前記実行パイプラインに対し、前記メモリから前記プログラム命令を再取得することなく、前記パイプラインステージの1つの中の前記プログラム命令を再使用させるように接続される。 (もっと読む)
1 - 20 / 87
[ Back to top ]