
Fターム[5B045AA01]の内容
Fターム[5B045AA01]に分類される特許
1 - 20 / 51
画像音声信号処理装置及びそれを用いた電子機器
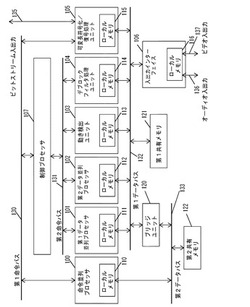
【課題】 MPEG−4 AVCの符号化/復号処理のような、大量のデータ処理量が要求される画像処理に対して、高性能で、高効率な画像処理が行える信号処理装置及びそれを用いた電子機器を提供する。
【解決手段】 信号処理装置は、命令並列プロセッサ100、第1データ並列プロセッサ101、第2データ並列プロセッサ102、及び、専用ハードウェアである動き検出ユニット103とデブロックフィルタ処理ユニット104と可変長符号化/復号処理ユニット105とを備える。この構成により、処理量の多い画像圧縮伸張アルゴリズムの信号処理において、ソフトウェアとハードウェアで負荷が分散され高い処理能力と柔軟性を実現した信号処理装置、及びそれを用いた電子機器を提供出来る。
(もっと読む)
画像処理装置、画像形成装置及びプログラム

【課題】画像データに対する非線形処理の効率を向上させることができる画像処理装置、画像形成装置及びプログラムを提供する。
【解決手段】画像データの一部の画素値と、該画像データの一部とは異なる部分の画素値とを比較する比較手段と、前記比較手段による比較の結果に応じて、前記画像データに非線形処理を施す非線形処理手段とを有する。前記非線形処理手段は、前記比較手段による比較の結果、前記画像データの一部の画素値と、該画像データの一部とは異なる部分の画素値とが同じである場合、前記画像データの一部と、該画像データの一部とは異なる部分とに同じ非線形処理を施す。
(もっと読む)
マルチプロセッサおよびそれを用いた画像処理システム
【課題】データの共有やデータ転送のバッファリングを容易に行なうことが可能なマルチプロセッサを提供すること。
【解決手段】複数の共有ローカルメモリ5−0〜5−(n−1)のそれぞれが、複数のプロセッサユニットPU0〜PU(n−1)(1−0〜1−(n−1))の中の2つのプロセッサに接続されており、複数のプロセッサユニットPU0〜PU(n−1)(1−0〜1−(n−1))と複数の共有ローカルメモリ5−0〜5−(n−1)とがリング状に接続される。したがって、データの共有やデータ転送のバッファリングを容易に行なうことが可能となる。
(もっと読む)
データ処理装置及びデータ処理方法
【課題】 データ処理の領域を分割して複数のプロセッサに並列処理させる際に、分割の最小単位を小さくする。
【解決手段】 データ処理装置が、第一のデータ処理を複数のプロセッサに並列処理させ、並列処理されたデータを記憶部に格納する際に、複数のプロセッサのデータキャッシュのサイズに基づいて記憶部のアドレスを変換して格納する。そして、記憶部に格納されたデータを読み出し、読み出したデータに対して第二のデータ処理を行う。
(もっと読む)
グラフィックスプロセッサ
【課題】メモリボトルネックによる性能低下を抑制する
【解決手段】グラフィックスプロセッサは、複数の画素データそれぞれの処理を並列して行う複数のプロセッサコアと、複数のプロセッサコアにより共有されるレジスタと、レジスタを制御するレジスタ制御部と、画素データを保持する画素保持メモリとを備える。レジスタは、画素毎に、画素データと前記画素データに対応する画素座標データとを保持する。レジスタ制御部は、画素座標データを検索キーにレジスタを検索する検索部を含む。
(もっと読む)
情報処理装置、情報処理方法、およびプログラム
【課題】リングバスの実行効率を向上する。
【解決手段】リングバスにおいて、モジュールは、パケットを受信する受信部と、受信されたパケットに含まれるデータが、モジュールが有する処理モジュールが処理する処理データでか、処理モジュールの設定を内部に含まれるコマンドにより変更する設定データかを判定する判定部と、設定データであると判定された場合、設定データの内部に含まれるコマンドの種類を示すコマンド種別が、モジュールへ設定データを書き込む書込みモードと、当該モジュールが保持する既設定データを読み出す読出しモードと、既設定データを読み出した後に設定データを書き込む入替えモードとの何れかを判別する判別部と、コマンド種別に基づいてパケット送信間隔を決定する決定部と、パケット送信間隔をタイマに設定する設定部と、パケットを送信する送信部と、を備える。
(もっと読む)
データ処理装置及びデータ処理方法
【課題】入力画像の種類や画像内の処理位置による性能変動が少なく、均一の高い処理性能をもつデータ処理装置を提供する。
【解決手段】部分データに対する前段のステージでの処理結果に応じて当該部分データに対する後段のステージでの処理を実行するか否かが決定されるデータ処理を、各ステージに複数の処理モジュールを分配し、ステージ間及び少なくとも1つのステージ内において複数の部分データを並列に処理するように複数の処理モジュールを接続する接続部を有する。データ処理装置は、各ステージについて、後段のステージに処理を実行させる処理結果が得られた率を通過率として検出し、この通過率に基づいて各ステージで処理されるデータ量に対する処理時間を取得し、この処理時間が均一になるように各ステージに分配する処理モジュールの個数を決定する。そして、決定された分配にしたがって、接続部による複数の処理モジュールの接続状態を変更する。
(もっと読む)
信号制御装置及び信号制御方法
【課題】2つのCPUがデュアルポートRAMに同じタイミングで読出し又は書込みを行う場合に、データ信号を正しく読出すこと。
【解決手段】信号制御装置4は、第1及び第2のCPUがデュアルポートRAM5に書き込むアドレスの衝突を検出するアドレス衝突検出部14を備える。また、アドレスの衝突が検出された場合に、デュアルポートRAM5に書込みを行う第1又は第2のCPUのいずれかに設けられたバッファメモリに、衝突したアドレスから読出したデータ信号を保存する制御を行う制御部13を備える。また、第1及び第2のCPUの読出し可能状態又は書込み可能状態に応じて、データ信号の読出し元であるレジスタ又はバッファメモリを切替えて、読出し可能状態となるCPUに読出した前記データ信号を出力するマルチプレクサ15a,15bを備える。
(もっと読む)
画像処理装置、画像形成システム及び画像処理プログラム
【課題】 パイプライン処理方式とリコンフィグ処理方式のうち、画像処理に要する時間が短い方の処理方式で複数のDRPを稼動させる画像処理装置、画像形成システム及び画像処理プログラムを提供することを目的とする。
【解決手段】 入力された印刷ジョブの画像情報の画素数に基づいて、リコンフィグ処理方式によって画像処理する場合に要する第1処理時間とパイプライン処理方式によって画像処理する場合に要する第2処理時間とを算出する処理時間算出部32aと、処理時間算出部32aにより算出された第1処理時間と第2処理時間のいずれか短い時間の処理方式によって、複数のDRP61〜66を稼動させる稼動制御部32bと、を有する。
(もっと読む)
並列信号処理装置
【課題】データ転送におけるレイテンシーの遅れや、データ転送機構以外の回路の増大を伴うことなく、演算器の並列度を高めても、急激な回路規模の増大を抑えることができるようにする。
【解決手段】演算器1−1〜1−nが、自己が接続されているローカル共有バス2に接続されている共有メモリ3から隣接している他の演算器1の演算結果を読み出して、その演算結果に対する所定の演算処理を実施し、その演算処理の演算結果を上記ローカル共有バス2に接続されている上記共有メモリ3以外の共有メモリ3に書き込むように構成する。
(もっと読む)
データ処理装置及びそのデータ処理方法
【課題】
リングバスに接続された複数の処理モジュールにより各種処理を実行する構成において、アクセス遅延を起因とした処理速度の低下がある。
【解決手段】
データ処理装置は、リング状に接続され、所定の順番に従ってデータを処理する複数のモジュールと、データの処理に用いるパラメータを格納する共有メモリとを有する。ここで、モジュールは、共有メモリから取得したパラメータを格納する格納手段と、他のモジュールから受信したデータが自モジュールで処理すべきデータであるか否かを識別する識別手段と、識別手段により自モジュールで処理すべきと識別されたデータの処理に必要なパラメータが格納手段に格納されていない場合、共有メモリに対してパラメータの取得を要求する要求手段と、要求手段により共有メモリに要求したパラメータを必要とするデータを他のモジュールへ送信する送信手段と、当該パラメータを用いてデータを処理する処理手段とを具備する。
(もっと読む)
画像処理装置
【課題】複数のプロセッサ要素を1次元に結合してなる分散メモリ型プロセッサアレイを備えた画像処理装置により、1行の画素数がプロセッサ要素数より多い画像を処理する場合の効率向上を図る。
【解決手段】画像処理プロセッサ100は、複数個のプロセッサ要素をリング状に1次元に結合してなる分散メモリ型プロセッサアレイ120を備え、処理対象の画像の1行の画素数がプロセッサ要素数より大きいときに、該画像を折り畳んでプロセッサ要素のローカルメモリに格納する。各プロセッサ要素のメモリアクセス制御部は、ローカルメモリアクセスにより画像の所定の行に含まれる画素に対する読出要求があった際に、ローカルメモリに格納された、上記所定の行の全ての画素をローカルメモリから読み出すことが可能である。なお、ローカルメモリアクセスは、プロセッサアレイ120内部に生じるメモリアクセスである。
(もっと読む)
複数の処理モジュールを有する並列処理回路を備えるデータ処理装置、およびその制御方法
【課題】複数の処理モジュールがリング状のバスに接続されたデータ処理装置において、異なる順番で処理する複数のパイプライン処理を複数の処理モジュールに設定する場合、処理順序を変更した場合でも、複数のモジュールとその間のバスを流れるデータ量を調節し、効率的なデータ処理が可能となるデータ処理装置を提供する。
【解決手段】パイプライン処理上で後段のモジュールがデータを受信できるように、パイプライン処理上で前段のモジュールが自身の処理したデータの送信間隔を制御する。
(もっと読む)
データ処理装置
【課題】互いに他のデータフローの処理を妨害することを防止できるようにする。
【解決手段】複数のデータ処理部がリング状のバスに接続され、前記複数のデータ処理部にて予め設定された順序でデータ処理を行うデータ処理装置であって、前記データ処理装置の外部にデータを出力する複数のデータ出力部を備え、前記複数のデータ出力部のいずれかにより、処理済みデータを前記リング状のバスの外に出力するようにして、複数のデータフローを1つずつ逐次的に処理するよりも処理速度が向上することができるようにする。
(もっと読む)
汎用使用のための処理ユニット内部メモリ
【解決手段】
汎用使用のための内部メモリを有するグラフィクス処理ユニット(GPU)及びそのアプリケーションがここに開示される。そのようなGPUは、第1の内部メモリと、第1の内部メモリに結合される実行ユニットと、第1の内部メモリを他の処理ユニットの第2の内部メモリに結合するように構成されるインタフェースと、を含む。第1の内部メモリは積層ダイナミックランダムアクセスメモリ(DRAM)又は埋め込みDRAMを備えていてよい。インタフェースは第1の内部メモリをディスプレイデバイスに結合するように更に構成されていてよい。GPUは第1の内部メモリを中央処理ユニットに結合するように構成される別のインタフェースを含んでいてもよい。またGPUはソフトウエアにおいて具現化され且つ/又はコンピューティングシステム内に含まれていてよい。
(もっと読む)
画像形成装置
【課題】画像形成装置において、不揮発性メモリを2つのCPUで共有させると共に、2つのCPUから不揮発性メモリへのアクセスを簡単な回路で調整できるようにする。
【解決手段】画像形成プロセス制御を行う第1CPU1と、通信制御を行う第2CPU2と、第1CPU1及び第2CPU2で共有するEEPROM4と、第1CPU1及び第2CPU2の一方を不揮発性メモリ4に直接アクセス可能とするセレクタ3とを設ける。そして、第1CPU1と第2CPU2との間で通信可能とし、通常状態では、第1CPU1がEEPROM4に直接アクセス可能とするとともに、第2CPU2は、第1CPU1を介してEEPROM4にアクセス可能とする。一方、第1CPU1が作動を停止した省電力状態又は第1CPU1が動作異常状態では、セレクタ3によって第2CPUがEEPROM4に直接アクセス可能となるようする。
(もっと読む)
リングバスを用いたデータ処理装置、データ処理方法およびプログラム
【課題】 リングバスに接続されたデータ処理装置において、複数のデータ処理ストリームを投入した場合や、処理回路内部でデータ量が増減してしまうケースが存在する際に発生し得る、デッドロックや、リングバスの実効効率の低下を軽減する必要がある。
【解決手段】 リングバスの動作速度を、データ処理にかかる動作速度よりも早くすることにより、リングバスを周回するデータによるデータ出力抑制の機会を減らし、処理効率の低下を抑制する。
(もっと読む)
ヘテロジニアスマルチコアプロセッサ
【課題】プロセッサコアとプロセッサエレメント間におけるデータ授受のためのオーバーヘッドを短縮するとともに、演算能力の向上させる。
【解決手段】プロセッサエレメント13は、各プロセッサコア2−A,2−B,2−Cからキャッシュ禁止に設定され、プロセッサコアおよび入出力インタフェース回路11から直接アクセス可能に設定され、入出力インタフェース回路11からメインメモリ17を介さずに直接転送された入力データおよびプロセッサエレメントの演算結果である出力データを格納するローカルメモリ14と、ローカルメモリ14とメインメモリ17との間でDMA転送するDMAC15とを備え、プロセッサエレメントは出力データをメインメモリ17へDMA転送後に転送完了の割り込みをプロセッサコアに通知し、プロセッサコアはこの通知に基づき次の処理を実行する。
(もっと読む)
データ処理装置、印刷システムおよびプログラム
【課題】CPUとGPUとの間で、大量のデータを効率良く処理する。
【解決手段】複数の処理を非同期で並列に実行可能なデバイス3と、このデバイス3との間でデータの授受を行うホスト2とを有し、ホスト2には、システムメモリ12内にデバイス3との間でデータ転送を行うためメモリ領域が確保され、デバイス3は、ホスト2からのデータを処理している間に並列してメモリ領域へのアクセスを行ってデータ転送を行い、ホスト2では、デバイス3に転送するデータを3以上に分割し、分割された2番目以降のデータについて、デバイス3で前回のデータが処理されている間に、メモリ領域への書き込みを行う。
(もっと読む)
データ処理装置およびデータ処理方法またはプログラム
【課題】 保留パケットの発生を抑える事により、リングバスの占有率を下げてデッドロックを回避し、かつ処理順序の変更が可能なデータ処理装置を実現する。
【解決手段】 リングバスと処理部の間を接続する通信部内にバッファを設け、enable信号により通信部と処理部のデータ転送を制御することにより、保留パケットの発生を抑え、リングバスの占有率を下げてデッドロックを抑制する。
(もっと読む)
1 - 20 / 51
[ Back to top ]