
Fターム[5B045DD12]の内容
マルチプロセッサ (2,696) | メモリシステム、ファイル管理 (299) | キャッシュメモリ、バッファメモリ (44)
Fターム[5B045DD12]の下位に属するFターム
データ一致 (5)
Fターム[5B045DD12]に分類される特許
1 - 20 / 39
異なる複数の優先度レベルのトランザクション要求をサポートする集積回路内における処理リソース割振り
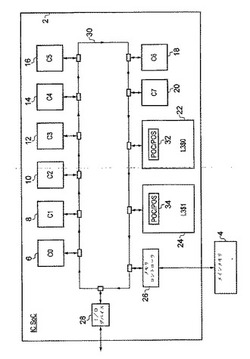
【課題】異なる複数の優先度レベルのトランザクション要求をサポートする集積回路内における処理リソース割振りを実現すること。
【解決手段】集積回路2は、複数のトランザクションソース6、8、10、12、14、16、18および20を含み、トランザクションソースは、関連付けられたPOC/POS30および34を各々が有する共有キャッシュ22および24とリングベースの相互接続30を介して通信し、要求サービング回路として働く。要求サービング回路は、異なる複数のトランザクションに割り振ることができる処理リソース36のセットを有する。これらの処理リソースは、動的に、または静的に割り振ることができる。静的割振りは、選択アルゴリズムに依存して行うことができる。この選択アルゴリズムは、入力変数のうちの1つとしてサービス品質値/優先度レベルを使用することができる。
(もっと読む)
分散共有メモリ管理システム、分散共有メモリ管理方法、および分散共有メモリ管理プログラム

【課題】メモリを共有する異なるノードにおけるメモリ資源・通信資源の使用効率を高める。
【解決手段】固有メモリに格納されたデータ値を更新し、更新された値が予め設定された共通初期値と異なる場合に更新された値と該値の固有メモリにおけるアドレスを送出する計算ノードと、共有メモリに格納されたデータを共通初期値で初期化するデータ初期化機能と、計算ノードから更新データが送り込まれた場合に前記更新データに基づき前記共有メモリにおける対応するアドレスのデータを前記更新値へと更新する共有メモリデータ更新機能を有するメモリ管理装置を備える。
(もっと読む)
マルチプロセッサおよびそれを用いた画像処理システム
【課題】データの共有やデータ転送のバッファリングを容易に行なうことが可能なマルチプロセッサを提供すること。
【解決手段】複数の共有ローカルメモリ5−0〜5−(n−1)のそれぞれが、複数のプロセッサユニットPU0〜PU(n−1)(1−0〜1−(n−1))の中の2つのプロセッサに接続されており、複数のプロセッサユニットPU0〜PU(n−1)(1−0〜1−(n−1))と複数の共有ローカルメモリ5−0〜5−(n−1)とがリング状に接続される。したがって、データの共有やデータ転送のバッファリングを容易に行なうことが可能となる。
(もっと読む)
データ処理装置及びデータ処理方法
【課題】 データ処理の領域を分割して複数のプロセッサに並列処理させる際に、分割の最小単位を小さくする。
【解決手段】 データ処理装置が、第一のデータ処理を複数のプロセッサに並列処理させ、並列処理されたデータを記憶部に格納する際に、複数のプロセッサのデータキャッシュのサイズに基づいて記憶部のアドレスを変換して格納する。そして、記憶部に格納されたデータを読み出し、読み出したデータに対して第二のデータ処理を行う。
(もっと読む)
共有キャッシュメモリ装置
【課題】2個のプロセッサに、より高速に連携した処理を行わせることが可能な共有キャッシュメモリ装置を提供する。
【解決手段】共有キャッシュメモリ装置を、第1プロセッサが生成して第2プロセッサが利用するデータを記憶するための幾つかの監視対象記憶領域をデータメモリ部33に確保する機能、管理対象記憶領域毎に第1プロセッサによるデータの書き込みが行われたか否かを管理する機能、データの書き込みが完了していない監視対象記憶領域上のデータを要求するリード要求を受信したときに、その監視対象記憶領域へのデータの書き込みが第1プロセッサにより行われるのを待機してから、当該リード要求に応答する機能を有する装置として構成しておく。
(もっと読む)
情報処理装置、情報処理方法、及びプログラム
【課題】ネットワークに接続されているハードディスク等の記録媒体を用いて、容易に仮想記憶領域を構築する。
【解決手段】プロセッサ41は、仮想記憶領域上に割り当てられている仮想アドレスに、ネットワーク22上に存在する記憶部のネットワーク22上の位置を示すネットワークノード情報と、記憶部の物理アドレスとを対応付けて保持しているアドレス変換モジュールに基づいて、仮想アドレスを、対応するネットワークノード情報及び物理アドレスに変換し、ネットワークIF45は、プロセッサ41により得られたネットワークノード情報及び物理アドレスに基づいて、ネットワーク22上の記憶部が有する複数の記憶領域のうち、物理アドレスが表す記憶領域にアクセスする。本発明は、例えば、ネットワークを介してハードディスク等と接続されている情報処理装置に適用できる。
(もっと読む)
マルチプロセッサシステムおよびマルチプロセッサシステムのプログラム
【課題】 マルチプロセッサシステムの計算処理の効率を向上させる。
【解決手段】 マルチプロセッサシステムは、第1メモリと、第1メモリに接続され、第1メモリに記憶されたデータを用いて処理を実施する処理部とを有している。処理部は、第2メモリと、データおよび処理の結果である処理データの少なくとも一方を第1メモリと第2メモリとの間で転送するデータ転送を実施する第1プロセッサと、第1メモリと第2メモリとの間でのデータ転送と処理とを切り替え可能に実施する第2プロセッサと、第2メモリに転送されたデータを用いて、処理を実施する第3プロセッサとを有している。
(もっと読む)
マルチコアプロセッサアーキテクチャにおけるデータ記憶およびアクセス
キャッシュに記憶されたデータブロックを送るためのシステムに関する技術が一般に記載されている。本明細書中に記載される幾つかの実施例では、システムが第1のタイルの第1のプロセッサを備えてもよい。第1のプロセッサは、データブロックの要求を発生させるのに有効であり、前記要求がデータブロックのための宛先タイルを識別する宛先識別子を含み、宛先タイルが第1のタイルと異なる。幾つかの実施例のシステムは、要求を受けるのに有効な第2のタイルを更に備えてもよく、第2のタイルは、データブロックを含むデータタイルを決定するのに有効であるとともに、要求をデータタイルへ送るのに有効である。幾つかの実施例のシステムは、第2のタイルから要求を受けるのに有効なデータタイルを更に備えてもよく、データタイルはデータブロックを宛先タイルへ送るのに有効である。  (もっと読む)
(もっと読む)
マルチコアシステム
【課題】プロセッサ間ネットワークの特定のルータに負荷が集中することを軽減したマルチコアシステムを提供する。
【解決手段】プロセッサ間ネットワーク11は、各プロセッサエレメントPE0〜PE9から発せられたアクセス及び各プロセッサエレメントPE0〜PE9宛のデータを中継する複数のルータR00〜R23と、各プロセッサエレメントPE0〜PE9からのリードアクセスに応じて、アクセス対象のデータを要求元のプロセッサエレメント宛に送信する共有キャッシュメモリ12と、を備え、各ルータR00〜R23は、他のルータ又はプロセッサエレメントへ転送したデータを保持するルータ内キャッシュ機構C00〜C23と、リードアクセスが転送されてきた際にアクセス対象のデータをルータ内キャッシュ機構C00〜C23に保持している場合には、当該データを読み出して要求元のプロセッサエレメント宛に送信する手段と、を備える。
(もっと読む)
SIMDベクトルの同期
プロセッシングデバイス内のデコーダによって、第1記憶ロケーション、第2記憶ロケーション及び第3記憶ロケーションの間の複数のデータ要素に対するベクトル比較/交換オペレーションを規定する単一命令をデコードする段階と、プロセッシングデバイス内の実行ユニットによって実行するために、単一命令を発行する段階と、単一命令の実行に応答して、第1記憶ロケーションからのデータ要素と、第2記憶ロケーションにおける対応するデータ要素とを比較する段階と、一致が存在するかに応じて、第1記憶ロケーションからのデータ要素を、第3記憶ロケーションからの対応するデータ要素で置き換える段階とを実行することによって、ベクトル比較/交換オペレーションが実行される。 (もっと読む)
汎用使用のための処理ユニット内部メモリ
【解決手段】
汎用使用のための内部メモリを有するグラフィクス処理ユニット(GPU)及びそのアプリケーションがここに開示される。そのようなGPUは、第1の内部メモリと、第1の内部メモリに結合される実行ユニットと、第1の内部メモリを他の処理ユニットの第2の内部メモリに結合するように構成されるインタフェースと、を含む。第1の内部メモリは積層ダイナミックランダムアクセスメモリ(DRAM)又は埋め込みDRAMを備えていてよい。インタフェースは第1の内部メモリをディスプレイデバイスに結合するように更に構成されていてよい。GPUは第1の内部メモリを中央処理ユニットに結合するように構成される別のインタフェースを含んでいてもよい。またGPUはソフトウエアにおいて具現化され且つ/又はコンピューティングシステム内に含まれていてよい。
(もっと読む)
プロセッサ、サーバシステム、プロセッサ追加方法およびプロセッサ追加プログラム
【課題】 サーバシステムに動的にプロセッサを追加する際に、該プロセッサが初期化処理のためのメモリを持たなくても信頼性を保ちながら追加することができるプロセッサ、サーバシステム、プロセッサ追加方法およびプロセッサ追加プログラムを提供する。
【解決手段】 起動されると、プロセッサの信頼性の診断のためのプログラムをキャッシュメモリに読み出して実行する第1の初期化手段と、組み込み先パーティションに属するプロセッサから、所定のメモリ領域と自プロセッサとの間の通信経路が設定された旨の通知を受けると、当該メモリ領域にキャッシュメモリの信頼性の診断のためのプログラムを読み出して実行する第2の初期化手段とを備える。
(もっと読む)
インターフェース装置、演算処理装置、インターフェース生成装置、および回路生成装置
【課題】演算装置同士を最小の記憶素子数で接続することが可能で、キャッシュメモリに記憶するデータ数を最小にしても確実にアドレス指定によるデータ転送を行えるようにする。
【解決手段】バッファに保存した書込みデータを書込みアドレスの順序に並び替えてストリームデータとして出力するストリーム変換装置130と、キャッシュメモリ140と、読出しに関するアドレス情報で指定されたデータがキャッシュメモリに既にロードされているかを判定し、ロードされていない場合には、ロード信号を出力し、ロードアドレスを出力する制御装置150と、ロードアドレスを用いて、読出しアドレスで指定されたデータがキャッシュメモリのどの記憶素子に保存されているかを求め、求めた値をキャッシュアドレスとしてキャッシュメモリに出力し、キャッシュメモリから入力されたキャッシュデータを読出しデータとして出力するアドレス変換装置160と、を有する。
(もっと読む)
ヘテロジニアス処理ユニット間での不均一メモリアクセスのためのチップセットサポート
【課題】第2のプロセッサに関連付けられたメモリに第1のプロセッサがアクセスすることを可能にするための方法を提供すること。
【解決手段】この方法は、第1のプロセッサから、NUMAデバイスのためのMMIOアパーチャを含む第1のアドレスマップを受け取るステップと、第2のプロセッサから、ハードウェアデバイスのためのMMIOアパーチャを含む第2のアドレスマップを受け取るステップと、第1のアドレスマップと第2のアドレスマップを組み合わせることによってグローバルアドレスマップを生成するステップと、第1のプロセッサからNUMAデバイスに送られたアクセス要求を受け取るステップと、第1のアクセス要求と変換テーブルとに基づいて、メモリアクセス要求を生成するステップと、グローバルアドレスマップに基づいて、メモリアクセス要求をメモリにルーティングするステップとを含む。
(もっと読む)
マルチコアプロセッサ,制御方法および情報処理装置
【課題】特別な管理や制御を行なうことなく、効率的にプロセッサコアにタスクを処理させることができるようにする。
【解決手段】第1のプロセッサコア11が、第1のタスクの処理に際して第2のタスクに関する処理要求を行なう際に、第1のプロセッサコア11により用いられるメモリ領域31に第2のタスクに関する情報を格納するとともに、複数のプロセッサダイ10にそれぞれそなえられた各第2のプロセッサコア12に対して割込通知を行ない、割込通知を受けた第2のプロセッサコア12が、第2のプロセッサコア12と同一のプロセッサダイ10上にそなえられた第1のプロセッサコア11によって用いられるメモリ領域31に対してそれぞれアクセスを行なう。
(もっと読む)
単一パステセレーション
【課題】 テセレーションシェーダープログラムを実行するための改良されたシステム及び方法を提供する。
【解決手段】 グラフィックプロセッサを通して単一パスでテセレーションを実行するシステム及び方法は、グラフィックプロセッサ内の処理リソースを、異なるテセレーションオペレーションを実行するためのセットへと分割する。頂点データ及びテセレーションパラメータは、メモリに記憶されるのではなく、1つの処理リソースから別の処理リソースへ直接ルーティングされる。それ故、表面パッチ記述がグラフィックプロセッサに与えられ、そしてメモリに中間データを記憶せずに、グラフィックプロセッサを通して単一の非中断パスでテセレーションが完了される。
(もっと読む)
プロセッサ
【課題】高性能なネットワーキングおよび通信アプリケーション等の新しい技術を利用できると同時に高性能機能性も備えるプロセッサを提供する。
【解決手段】プロセッサは、それぞれがデータキャッシュおよび命令キャッシュを持っている複数のマルチスレッドプロセッサコアを備えている。データスイッチ相互接続はプロセッサコアのそれぞれに接合されておりプロセッサコア間で情報を手渡すように構成されている。メッセージネットワークはプロセッサコアおよび複数の通信ポートのそれぞれに接合されている。データスイッチ相互接続がプロセッサコアのそれぞれにそれぞれのデータキャッシュによって接合されており、メッセージングネットワークがプロセッサコアのそれぞれにそれぞれのメッセージステーションによって接合されている。
(もっと読む)
マルチコアシステム、車両用ゲートウェイ装置
【課題】ゾーン毎のCPUコア数を可変なマルチコアプロセッサシステムであって、ゾーン間のデータ保護を向上させたマルチコアシステム及び車両用ゲートウェイ装置を提供すること。
【解決手段】1以上のコアを有する複数の固定コア群11A、11B、及び、複数のコアを有するプールコア群12、を有するマルチコアシステム100において、固定コア群11A、11Bはそれぞれ専用メモリ13A、13Bと接続され、プールコア群12は全ての専用メモリ13A、13Bと接続されており、プールコア群12の0以上のコアAは固定コア群11Aと協働し、コアAと異なるプールコア群の0以上のコアBは固定コア群11Bと協働し、コアA及びコアBと異なるプールコア群の1以上のコアRは固定コア群Aと固定コア群Bを中継する、ことを特徴とする。
(もっと読む)
マルチプロセッサシステム
【課題】並列処理用のマルチプロセッサにおいて、価格性能比を改善し、高まりつつある半導体集積度にスケーラブルな性能向上を達成する。
【解決手段】CPUと、分散共有メモリと、ローカルデータメモリと、を備える複数のプロセッシングエレメントと、前記各プロセッシングエレメントに接続される集中共有メモリと、を備えるマルチプロセッサであって、前記各プロセッシングエレメントに割り当てられたタスク間で共通に使用されるデータが、前記各タスクで必要とされるとき以前に、データの消費先の前記プロセッシングエレメントの前記分散共有メモリへ転送され、前記集中共有メモリは、粗粒度並列処理において条件分岐に対応するために使用されるダイナミックスケジューリングにおいて、プログラムの実行時までどのCPUにより使用されるかが決まっていないデータを格納する。
(もっと読む)
マルチプロセッサシステムおよびマルチプロセッサシステムの同期方法
【課題】高効率なバリア同期処理を実現可能なマルチプロセッサシステムを提供する。
【解決手段】各プロセッサCPU#0〜#7内に、バリアライトレジスタBARWとバリアリードレジスタBARRを設け、専用の配線ブロックWBLK3を用いて各BARWを各BARRに配線する。例えば、CPU#0の1ビットのBARWは、WBLK3を介してCPU#0〜#7に含まれる8ビットの各BARRの1ビット目に接続され、CPU#1の1ビットのBARWは、WBLK3を介してCPU#0〜#7に含まれる8ビットの各BARRの2ビット目に接続される。例えば、CPU#0は、自身のBARWに情報を書き込むことでCPU#1〜#7に同期待ちを通知し、自身のBARRを読むことでCPU#1〜#7が同期待ちか否かを認識する。したがって、バリア同期処理に伴い、特殊な専用命令は不要であり、また高速に処理を行うことができる。
(もっと読む)
1 - 20 / 39
[ Back to top ]