
Fターム[5B075NK34]の内容
検索装置 (67,127) | 検索キー情報 (8,147) | 検索キー情報の自動抽出 (2,419) | 自然言語解析による検索キーの抽出 (1,229) | 限定辞書 (43)
Fターム[5B075NK34]に分類される特許
1 - 20 / 43
管理装置、管理方法、及びプログラム
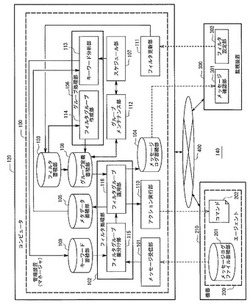
【課題】フィルタの優先度の設定を変更することなく、フィルタ処理の工数を低減し得る、管理装置、管理方法、及びプログラムを提供する。
【解決手段】管理装置100は、機器210から受信したメッセージのメタデータから、出現頻度が閾値以上となるメタデータをキーワードとして抽出するキーワード分析部113と、メッセージを選別するフィルタ群を、キーワードに関連する第1のフィルタとこれ以外の第2のフィルタとに分け、キーワード毎の第1のフィルタグループと第2のフィルタグループとを作成するフィルタグループ作成部114と、受信したメッセージのメタデータが、抽出されたキーワードと一致するか判定し、判定結果に基づいて、適用するフィルタグループを選択するフィルタグループ振分け部115と、受信したメッセージに対して、選択されたフィルタグループを適用する、フィルタグループ適用部116とを備える。
(もっと読む)
データ検証システムおよびデータ検証方法

【課題】データの妥当性のチェック処理を行う共通部品を用いてノンプログラミングでデータを検証する。
【解決手段】業務テーブル11は取引ごとに発生するトランザクションデータが登録された複数のテーブルを含む。関連マスタテーブル12は各取引において共通に使用されるマスタデータが登録された複数のテーブルを含む。チェック項目テーブル13は、業務テーブル11に含まれる各テーブル中のデータ項目ごとにそのデータ項目に登録されるデータが満たすべき条件を示すチェック仕様が登録されるテーブルである。標準チェック部品14は、業務テーブル11と関連マスタテーブル12からデータを抽出し、チェック項目テーブル13を参照して、業務テーブル11に含まれる各テーブルの各データ項目について、チェック仕様を満たすか否かを検証する。標準チェック部品14は、チェック結果を示す情報をチェック結果テーブル15に格納する。
(もっと読む)
管理装置、格納形式の決定方法、及びプログラム
【課題】管理対象となるユーザとロールとの関係が表現された状態を維持しつつ、TATの低下とメモリに格納される情報量の増大化とを抑制し得る、管理装置、格納形式の決定方法、及びプログラムを提供する。
【解決手段】予め定義されたロールに基づいて複数のユーザを管理する管理装置10は、ロール毎にユーザの識別子をメンバとして格納しているデータベース20から、検索条件に合致したロールに属するメンバを抽出する、ロール情報処理部11と、抽出されたメンバをロールメンバ情報として格納する、メモリ13と、メモリ13においてロールメンバ情報を格納する際の格納形式を、メンバについて予め設定されている条件とロールメンバ情報の内容とに基づいて、処理速度を優先した第1の格納形式、及び格納効率を優先した第2の格納形式のうちのいずれかに決定する、格納形式決定部12と、を備えている。
(もっと読む)
番組検索装置および番組検索方法
【課題】字幕データの有無に拘わらず、番組や番組内の所定シーンを適切に検索する。
【解決手段】番組検索装置420は、番組ストリームに含まれる字幕データまたは番組情報を抽出し、形態素に分割して、その形態素を許可ワードテーブルに登録するテーブル更新部180と、番組保持部464と、番組に関するテキストデータを取得すると共に、取得日時情報を関連付けるデータ取得部482と、テキストデータを形態素に分割し、分割した形態素が許可ワードテーブルに登録されていなければ、形態素を、予め定められた記号に置換するデータ加工部184と、保持された番組ストリームに、置換されたテキストデータと、取得日時情報との組をインデックスデータとして付与するインデックス付与部492と、キーワードとインデックスデータとに基づいて番組または番組内の所定シーンを抽出する番組抽出部494とを備える。
(もっと読む)
電子文書マスキングシステム
【課題】構造化されていない電子文書に対し、電子文書毎の公開レベルに対応して秘匿すべき情報を変更し、マスキング対象を絞ってマスキングする。
【解決手段】マスキング処理部101のマスキング対象判定部は、電子文書110の文書名により文書公開レベルDB106を検索して、各電子文書110についてマスキングする文字列の種別毎のマスキング要否情報を取得する。そして、マスキング対象判定部は、取得された要否情報がマスキングすることを指定している場合、マスキング対象判定辞書105に格納されているマスキング対象文字列の種別毎の文字列定義情報に基づいて電子文書110に含まれる各文字列がマスキング対象文字列であるか否かを判定し、マスキング対象文字列であると判定されたマスキング対象文字列をマスキングする。
(もっと読む)
書き込み情報収集システム、方法、およびプログラム
【課題】ソーシャルメディアから、所定の言語で記述された情報を収集すること。
【解決手段】複数の言語に対応するソーシャルメディアに書き込まれた書き込み情報の中から、所定の言語の書き込み情報を収集する書き込み情報収集システムは、所定の言語の文に含まれ、文中の他の語との関係を示す単語群が設定された設定ファイルを読み込む読み込み部30と、単語群の各単語に基づいて、ソーシャルメディアから書き込み情報を収集する収集部50と、収集した書き込み情報を記憶する書き込み情報記憶部42と、を備える。
(もっと読む)
語句解説装置および語句解説方法
【課題】文書中の特定のパターンをもった語句について自動的に解説を行うことができる語句解説装置および語句解説方法を提供する。
【解決手段】文字列の特定パターンと、文字列の特定パターンに対応するアドレス情報を記憶する記憶部と、外部から与えられる文字列の内、特定パターンをもつ文字列を検出する検出部と、検出部が検出した特定パターンに対応するアドレス情報が指定するウェブアプリケーションとネットワークを介して通信を行ない、ウェブアプリケーションから特定パターンをもつ文字列が含む語句の解説情報を取得する通信部を有する語句解説装置。
(もっと読む)
画像処理装置、画像処理方法、及び画像処理プログラム
【課題】画面に同一と認識されうるオブジェクトが複数存在する場合でも、ユーザーに対して適切な処理を促すことで、以後の検索処理においてユーザーの意思を反映させた検索を行なうことが可能な画像処理装置、画像表示方法、画像表示プログラムの提供を目的とする。
【解決手段】類似度判定により一致したオブジェクトに対して同一の付加情報を付与する画像処理装置であって、前記付加情報をもとに検索を行なう検索手段と、前記検索された画像データーの中に同一と認識されうるオブジェクトが複数表示されている場合、前記オブジェクトに関する付加情報を異なる表示形式で表示する付加情報表示手段と、前記付加情報の変更を受付けた場合に、前記付加情報を変更する表示変更手段と、を有する
(もっと読む)
文書分析装置及び文書分析方法
【課題】 文末表現のパターンマッチでは抽出できない表現であっても、特許文献から効果表現を高精度に抽出する。
【解決手段】 プロセッサと、前記プロセッサに接続されるメモリと、を備え、入力された特許文献の文の中から効果表現を抽出する文書分析装置は、効果要素判定制御部と、尺度要素判定制御部と、対象要素判定制御部と、効果表現特定部と、構成要素判定結果記憶部と、を備え、前記特許文献中の文の中から、前記効果要素判定制御部は、効果要素である単語を特定し、前記尺度要素判定制御部は、前記効果要素の判定結果を用いて、尺度要素である単語を特定し、前記対象要素判定制御部は、前記効果要素と、前記尺度要素の判定結果と、を用いて、対象要素である単語を特定し、前記効果表現特定部は、前記与えられた特許文献の文の中から効果表現を特定する。
(もっと読む)
住所データベース構築装置および住所データベース構築方法
【課題】未登録部が住所データベースなしでは読取り困難な場合にも効率よく住所データベースを構築・更新することができる住所データベース構築装置および住所データベース構築方法を提供する。
【解決手段】住所情報が記載された郵便物や帳票等の紙葉類を住所情報に基づき区分処理する紙葉類処理装置において、郵便物や帳票等の紙葉類に記載された住所情報を利用して住所データベースを構築する住所データベース構築装置において、住所情報の一部の認識に成功し残りの部分の認識に失敗した場合、その画像を蓄積しておき、あらかじめ定められた所定のタイミングで、その蓄積された画像の中から未登録データの記載されている可能性の高い画像を検出して表示し、この表示された画像に基づき認識に失敗した部分の住所情報を入力し、この入力された住所情報を住所データベースに登録する。
(もっと読む)
文書分類装置、文書分類方法、プログラムおよび記憶媒体
【課題】事前準備作業および保守作業に関する人的負荷が少なく、精度良く文書を分類できる文書分類装置等を提供する。
【解決手段】グループ化処理21は、評価表現として用いられる単語である評価単語のリスト(評価単語リスト31)、および分類済の学習用文書32に基づいて、学習用文書32に含まれる評価単語をグループ化して、評価単語グループ41を出力する。分類スコア算出処理22は、学習用文書32、評価単語グループ41を入力し、評価単語グループ41ごとに、未分類文書を分類するための分類スコアを算出し、分類スコア付評価単語グループ42を出力する。文書分類処理23は、未分類文書33を入力し、未分類文書33に含まれる評価単語が属する評価単語グループ41を特定し、特定した評価単語グループ41の分類スコアに基づいて、未分類文書33を分類し、分類結果43を出力する。
(もっと読む)
情報処理装置、情報処理方法およびプログラム
【課題】予め登録された複数の文書情報を含む事例情報を、複数の文書情報の内容に応じ
て適切なグループに分類すること。
【解決手段】各々に重要度が定められた複数の文書情報を含む事例情報を記憶する事例記
憶装置から事例情報を取得する取得手段と、事例情報が分類される複数のグループの各々
に対応したキーワードを記憶するキーワード記憶手段と、事例情報に含まれる文書情報を
解析して、各キーワードに対応する情報を文書情報の各々から抽出する抽出手段と、文書
情報の各々から抽出した情報と文書情報の各々に定められた重要度とに応じて、事例情報
に対応するキーワードを特定する特定手段と、取得手段によって取得された事例情報を、
特定手段によって特定されたキーワードに対応するグループに分類する分類手段とを具備
する。
(もっと読む)
情報処理装置、通信端末、興味情報提供方法および興味情報提供プログラム
【課題】人が興味を示す情報をその人が作成に関与したコンテンツを基にして簡易に取得できる情報処理装置、興味情報提供装置、興味情報提供方法およびプログラムを得ること。
【解決手段】文書データから抽出した動詞が人が興味語格納手段11に格納された興味語であるとき、情報処理装置10は、セット抽出手段12の抽出したその動詞とセットされた名詞をキーワードとして情報検索手段14で情報の検索を行う。興味語としての動詞と文脈上で対となる名詞を事前に登録する必要がない。
(もっと読む)
情報分類システム、情報分類方法及びプログラム
【課題】不要語・重要語を自動的に導出しクラスタリングを行なうことにより、利用者にとって有益な分類結果を生成する。
【解決手段】情報分類システムによれば、文書データにおける第一の特定範囲および第二の特定範囲のテキスト情報に関して、各特定範囲に含まれる各単語の相関関係に基づいて重要語または不要語を抽出する重要語・不要語抽出処理部と、記憶装置に記憶された各文書データについて各特定範囲の重要語または不要語に基づいてクラスタリングを行うクラスタ生成処理部とを実行する処理装置を備える。
(もっと読む)
録音装置およびインデックス情報付与方法
【課題】より安価な構成で音声ファイルにインデックス情報を迅速に付与することが可能な技術を提供する。
【解決手段】キーボイス登録部106は、キーボイス受付部105およびキーボイスインデックス・話者種別受付部104を介して、ユーザから受け付けたキーボイスデータおよびインデックス情報を、互いに対応付けてキーボイス記憶部102に記憶する。キーボイス特定部109は、録音制御部108による通話データの録音に際して、この通話データに含まれているキーボイスデータを特定し、特定したキーボイスデータに対応付けられてキーボイス記憶部102に記憶されているインデックス情報を、この通話データの録音により作成されて音声ファイル記憶部103に記憶された音声ファイルに関連付ける。
(もっと読む)
重要キーワード抽出装置及び方法及びプログラム
【課題】 今話題となっているキーワードや百科事典等で調べられやすいキーワードの自動判別が可能で、特定の分野に特化したキーワードを抽出する。
【解決手段】 本発明は、知識獲得サイト及びシステムとそのページビュー数を抽出して知識キーワード候補として知識キーワード候補辞書記憶手段に格納し、知識獲得サイトの前記ページビュー数の順位を用いて該知識獲得サイトの知識キーワード毎に第1の重要度を算出し、該知識キーワードと該第1の重要度を組にして知識キーワード重要度記憶手段に格納し、文書が入力されると、知識キーワード候補辞書記憶手段を参照して形態素解析した結果から知識キーワード候補を抽出し、抽出された知識キーワード候補に基づいて、知識キーワード重要度記憶手段を検索し、第1の重要度の高い順に知識キーワードを抽出し、出力する。
(もっと読む)
設計書作成支援装置、設計書作成支援方法、プログラムおよび設計書作成支援システム
【課題】設計書全体に散在する非機能要件を、簡易に抽出し、出力する。
【解決手段】設計書読込手段110が外部から設計書210を読み込み、関連情報検出手段120が、設計書読込手段110が読み込んだ設計書210から、非機能要件キーワードDB140に非機能要件として記憶されているキーワードを検出し、出力手段130が、関連情報検出手段120が検出した結果を出力する。
(もっと読む)
検索キーワード辞書に対する非検索キーワード辞書を用いた文章検索プログラム、サーバ及び方法
【課題】例えば予め登録されたキーワードによって違法・有害なカテゴリに属するか否かを判定する際に、違法・有害でない文章情報が、違法・有害なカテゴリに分類されることをできる限り減らすことができる文章分類プログラム、サーバ及び方法を提供する。
【解決手段】特定カテゴリに属さない複数の正当学習文章情報と、特定カテゴリに属する複数の不当学習文章情報とを蓄積した学習文章蓄積手段を有し、検索キーワードを含む学習文章情報を検索し、その検索キーワードに対する係り受けキーワードを抽出し、係り受けキーワード毎に、全ての学習文章情報の数に対する正当学習文章情報の数の正当割合を算出し、正当割合が所定閾値以上となる係り受けキーワードを非検索キーワードとして登録する非検索キーワード辞書を生成する。これにより、検索キーワードに対する係り受けキーワードとして非検索キーワードが含まれている文章情報は検索されないようにする。
(もっと読む)
単語の関連キーワードを決定する装置ならびにその動作制御方法およびその動作制御プログラム
【課題】ウェブ・ページに適したキーワードを決定する。
【解決手段】関連するキーワードを決定したい単語を入力する。入力された単語に関連するウェブ・ページが見つけられる。見つけられたウェブ・ページのメタ・タグに記述されているキーワード(プログラム言語,オブジェクト指向,教育,セミナー)が抽出される。入力された単語の専門辞書が登録されている辞書サーバに抽出されたキーワードが送信される。その辞書サーバに,送信されたキーワードが登録されていれば,そのキーワードは入力された単語に関連するキーワードと決定される。
(もっと読む)
専門用語抽出装置およびプログラム
【課題】コミュニティ内のメンバーの発言をもとに、一般用語を除外して個人を特徴づけるキーワードを抽出する。
【解決手段】専門用語抽出装置1は、投稿者の操作に応じて入力された文書を形態素解析する形態素解析部20と、文書に含まれる単語間、単語と投稿者との間、単語と該投稿者が属する投稿先グループとの間の偏りスコアを計算する偏りスコア計算部30と、偏りスコアの値応じて、文書に含まれている一般用語を抽出する一般用語抽出部40と、一般用語抽出部40により抽出された一般用語を文書から除いて、個人の特徴を示すキーワードを抽出するインデックス抽出部50と、を備える。
(もっと読む)
1 - 20 / 43
[ Back to top ]