
Fターム[5B075NK50]の内容
検索装置 (67,127) | 検索キー情報 (8,147) | 検索キー情報の格納形態 (1,488) | 構造化 (1,350) | その他の構造化 (47)
Fターム[5B075NK50]に分類される特許
1 - 20 / 47
Nグラム検索のための転置インデックスの生成方法および生成装置、当該転置インデックスを用いた検索方法および検索装置、ならびに、コンピュータプログラム
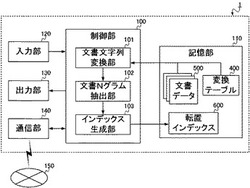
【課題】検索漏れを抑えるのに好適な転置インデックスの生成方法等を提供する。
【解決手段】生成装置1は、複数の文書データ(文書データ群500)のそれぞれを、所定の変換規則に基づいて、変換文書データに変換する文書文字列変換部101と、変換された複数の文書データに含まれる文字列から、「N文字の文字列であるNグラム(Nは自然数)」を抽出する文書Nグラム抽出部102と、抽出されたNグラムと、変換文書データ中における当該Nグラムの出現位置と、を構成要素とする転置インデックス600を生成するインデックス生成部103と、を備えることを特徴とする。
(もっと読む)
情報管理装置、情報管理方法、及びプログラム

【課題】検索条件によって定義されたグループのメンバ情報における不整合の発生を抑制しつつ、検索結果キャッシュの更新処理時間の短縮化を図り得る、情報管理装置、情報管理方法、及びプログラムを提供する。
【解決手段】情報管理装置100は、検索条件で定義されたグループのメンバを検索する検索処理部12と、検索結果をビットマップ形式でインデックス情報として記憶する検索結果記憶部20と、グループ毎に、定義に関連する属性をグループ属性情報として記憶するグループ属性記憶部32と、メンバの属性情報が変更された場合に、グループ属性情報に基づいて、変更された属性情報の属性と同一の属性に関連するグループを選択し、属性情報が変更されたメンバが、選択されたグループの定義を満たしているかどうかの判定の結果に応じて、インデックス情報における選択されたグループに対応する部分を更新する検索結果更新処理部33と、を備えている。
(もっと読む)
文書画像データベースの登録方法および検索方法
【課題】文書画像データベースの大規模化に伴って顕在化するLocally Likely Arrangement Hashing (LLAH) のメモリ効率の問題、および、特徴量の識別性の問題を解決する改善手法を提供する。LLAH は高いロバスト性を実現するために、必要メモリ量が多く、また、大規模化に対処するには、特徴量の識別性・安定性が十分でないという側面がある。
【解決手段】以下の3 点の改良を施す。第1は、ハッシュに保存する特徴点をサンプリングすることによる必要メモリ量の削減である。第2は、特徴量の次元数を増加させることによる識別性向上である。第3は、特徴量のうち冗長性のある次元を削除することによる安定性向上である。
(もっと読む)
高精度な類似検索システム
【課題】高精度な類似検索を実現する。
【解決手段】
pivot決定部によって登録用データからpivotを決定し、生データを取得し、前記生データから特徴量を抽出し、前記特徴量同士の距離或いは類似度としてスコアを計算し、前記pivotに対する前記スコアを用いて索引用ベクトルを生成し、前記索引用ベクトル同士の距離或いは類似度としてΔスコアを計算し、学習用データを用いて、回帰係数を含むnon−pivot毎のパラメータを学習し、検索用データと前記non−pivotとの前記Δスコアと前記回帰係数を用いて、ロジスティック回帰により事後確率の大きい順に前記non−pivotの選択順序を決定し、前記検索用データと前記登録用データとの前記スコアを基に、検索結果を出力する。
(もっと読む)
電子機器、人物相関図出力方法、人物相関図出力システム
【課題】電子書籍コンテンツの内容にあった人物相関図を表示し、視覚的にも楽しみたいというユーザの要求があった。また、視覚的に表示された内容がコンテンツ本文のどこに書いてあるかを知りたいというユーザ要求があり、これらを解決する電子機器の提供が課題となっていた。
【解決手段】実施形態の電子機器は、電子書籍コンテンツの本文に係る情報から、登場人物の視覚化に係る情報である人物視覚化情報と、前記登場人物間の関連に係る情報である人物関連情報と、前記人物視覚化情報または前記人物関連情報あるいはその両方の前記電子書籍コンテンツの本文に係る情報の参照先に係る情報である本文参照情報を解析する情報解析手段を備える。また、前記解析された人物視覚化情報と人物関連情報に基づいて、前記登場人物間の相関を示す人物相関図を出力する人物相関図出力手段を備える。
(もっと読む)
検索プログラム、検索装置、および検索方法
【課題】ブルームフィルタを用いた検索の検索速度の高速化を図ること。
【解決手段】(B)は、ブルームフィルタ列BF(p)の転置を示している。転置する場合、各ブルームフィルタbf(p−1)〜bf(p−4)の同一位置のビットを集めて、同一位置ごとに集められたビット列を、ビット位置順に配列させる。(C)において、ブルームフィルタ列BF(p)の場合は、4個のブルームフィルタbf(p−1)〜bf(p−4)内の4ビット目と8ビット目を参照するため、8(=4×2)のメモリアクセスが必要となる。一方、転置ブルームフィルタ列tBF(p)の場合、転置ブルームフィルタtbf(p−4),tbf(p−8)を抽出するという2回のメモリアクセスとそのAND演算により判定することが可能となる。したがって、メモリアクセス頻度が低減され、検索速度が高速化することとなる。
(もっと読む)
検索機能付きファイルストレージ装置及びプログラム
【課題】大幅に小さな空間に文書とその索引の情報を収容できるファイルシステムとプログラムを提供する。
【解決手段】ファイルシステム制御部と、構成情報ファイルシステムとを有する検索機能付きファイルストレージ装置において、ファイルシステム制御部が、N-gramインデクスの作成に使用された原始ファイルの構成文字列を、その配列順に重複なくかつ抜けなく再構成できるように、N-gramインデクスの各項目を表す符号の一部を配列した構成ファイルを生成する。
(もっと読む)
検索装置、検索方法および検索プログラム
【課題】文書データの特性によらず、効率よく全文検索を実行すること。
【解決手段】検索装置は、パターンファイル110a、第1のインデックス110b、第2のインデックス110cを記憶する記憶部110と、判定部120と、検索部130とを有する。判定部120は、検索キーワードを受け付け、検索キーワードとパターンファイル110aとを基にして、第1のインデックス110bを用いて検索を行うのか、第2のインデックス110cを用いて検索を行うのかを判定する。検索部130は、判定部120の判定結果に基づいて、第1のインデックス110bまたは第2のインデックス110cを用いて文書データの検索を実行する。
(もっと読む)
地点検索装置及びプログラム
【課題】入力された検索語と前方一致するキーワードを有する候補施設名の件数を迅速に表示することが可能となる地点検索装置を提供する。
【解決手段】入力手段によって入力される検索語及び該検索語の読みと前方一致するキーワードを有する候補施設名の件数が、該検索語の読みの文字列が属する50音の行の組み合わせに関連付けられて件数記憶手段に予め記憶されている。そして、入力手段によって検索語が入力された場合には、件数記憶手段から該検索語の読みの文字列が属する前記50音の行の組み合わせに関連付けられて記憶されている該検索語に対応する候補施設名の件数を取得して表示する。
(もっと読む)
データベース管理方法、データベース管理装置及びデータベース管理プログラム
【課題】あるユーザアプリケーションについて、問い合わせ結果を求める際の性能が良いアクセスパスを生成するためのインデクスを追加、変更又は削除する際に、他のユーザアプリケーションに対応するアクセスパスに影響を与えないことを実現する。
【解決手段】データベース管理装置のプロセッサが、複数のインデクスをグループ化することによりインデクスグループを作成し、インデクスグループの指定されたアクセス要求を受け付け、インデクスグループに含まれるインデクスの中から問い合わせ結果を求める際の性能が最も良いと判断したインデクスを選択し、当該インデクスを利用してアクセスパスを生成する。
(もっと読む)
任意の実数群から探索点の最近傍値を探索する方法
【課題】任意の実数群から探索点の最近傍値を高速に探索する。
【解決手段】実数群(x[1],x[2],x[3]…x[n])から、探索点qの最近傍値を探索する方法であって、探索用データベースを作るステップと、探索データベースを探索するステップとを含む。探索用データベースは、実数群の区間(x[1]〜x[n])をバケットで隙間無くかつ等間隔でm個に区分したバケット列を有する。各バケットには、バケット番号と、その中に含まれる実数の個数であるバケットサイズとが記憶される。各バケットには、バケットサイズがゼロでなくかつ当該バケットに最も近いバケットのバケット番号を示すラストフィルドバケットが記憶される。探索ステップは、探索点qが属するバケットを計算し、そのバケットのバケットサイズが0でない場合、当該バケット内から最近傍値を計算する。バケットサイズが0の場合、ラストフィルドバケットから最近傍値を計算する。
(もっと読む)
地点検索装置及びプログラム
【課題】名称リストを展開するメモリ容量の増大を抑止することができると共に、検索を高速で行い、応答性の低下を防止することが可能となる地点検索装置を提供する。
【解決手段】「分割単位」と、施設名の読みを記憶する「読み」と、「施設名」とから構成された施設名データテーブルを施設名DB27に格納している。「分割単位」には、1文字の平仮名から成る分割文字列、又は、長大ワードに対して1文字の平仮名が付加されて構成された特定分割文字列が記憶されている。「読み」には、「分割単位」の分割文字列又は特定分割文字列と前方一致するキーワードを含む施設名の読みが記憶されている。「施設名」には、検索対象となる施設名が、施設名の読みに対応して記憶されている。そして、CPU41は、検索語と前方一致する分割文字列又は特定分割文字列が記憶された「分割単位」内の全施設名の「読み」を順番に読み出して、全文検索を行う。
(もっと読む)
地点検索装置及びプログラム
【課題】名称リストを展開するメモリ容量の増大を抑止することができると共に、検索を高速で行い、応答性の低下を防止することが可能となる地点検索装置を提供する。
【解決手段】「分割単位」と、施設名の読みを記憶する「読み」と、「施設名」とから構成された施設名データテーブルを施設名DB27に格納している。「分割単位」には、施設名の読みを構成するキーワードと前方一致する平仮名が、50音順に1文字以上記憶されている。「読み」には、各「分割単位」に記憶される平仮名と前方一致するキーワードを含む施設名の読みが記憶されている。「施設名」には、検索対象となる目的地を表す施設名が、施設名の読みに対応して記憶されている。そして、CPU41は、検索語と前方一致する平仮名が記憶された「分割単位」内の全施設名の「読み」を施設名データテーブルから順番に読み出して、全文検索を行う。
(もっと読む)
カップルドノードツリーのインデックスキー挿入/削除方法
【課題】探索経路スタックを用いないカップルドノードツリーのインデックスキー挿入/削除方法を提供する。
【解決手段】ノード対の挿入位置を決定するに際して、挿入するインデックスキーによる検索を再度開始するとともに、各リンク先ノードであるブランチノードの弁別ビット位置が検索結果キーとのビット列比較で異なるビット値となる先頭のビット位置より下位の位置関係にあるか順次判定し、ブランチノードの弁別ビット位置がビット列比較で異なるビット値となる先頭のビット位置より下位の位置関係にあると判定するとそのブランチノードをノード対の挿入位置とする。削除処理においては、リンク元の配列番号の退避領域を利用する。
(もっと読む)
情報処理システムおよび情報処理装置
【課題】構造化データおよび非構造化データの適切な伝送処理を行なう。
【解決手段】構造化文書作成クライアント10において、画像の参照情報を含む構造化文書が構造化文書編集UI部11への入力操作により更新された場合で、既にハッシュキャッシュ部14に保存された元の画像のハッシュ値と更新後の構造化文書の画像のハッシュ値とが一致するとハッシュ一致判別部15による判別が判別した場合、更新された構造化文書の画像が更新されていないと判別して、当該更新された構造化文書をサーバ通信部12により構造化文書サーバ20に送信する一方で、更新後の構造化文書の画像は送信しない。構造化文書サーバ20は、文書DB40に保存される構造化文書のうち、受信した構造化文書の構造化文書URIで示される構造化文書を当該受信した構造化文書に更新する。
(もっと読む)
データベース処理方法、データベース処理システム及びデータベースサーバ
【課題】データベース処理システムにおいて、データの入出力に要する時間を短縮する。
【解決手段】受け付けられた問合せ要求に基づいてデータを出力する計算機と、当該データを格納する記憶装置を備えるストレージシステムと、を含むデータベース処理システムで、記憶装置には、データの格納位置を示すインデックスが格納され、インデックスは、複数の部分インデックスによって構成され、記憶装置に格納されたデータは、当該データの格納位置に基づいてグループ化されて、複数のデータグループを構成し、部分インデックスは、データグループに含まれるデータの格納位置を示し、計算機は、データの問合せ要求を受け付け、部分インデックスを取得し、データの問合せ要求及び取得された部分インデックスに基づいて、要求されたデータが格納された位置を特定し、特定された位置に格納されたデータの取得要求をストレージシステムに送信する。
(もっと読む)
コード列検索装置、検索方法及びプログラム
【課題】任意のコード列の検索を行うことができ、従来よりも短時間で作成することのできる索引のデータ構造を求め、それを用いたコード列検索手法を提供する。
【解決手段】検索対象のコード列を1コードずつ重複させて複数ブロックに分割し、分割されたコード列ブロックに対してコード毎のコードIDの範囲を格納したコード別ID範囲表と各コードIDの次に位置する次コードIDを格納したID関係表を作成し、コード別ID範囲表から検索コード列を構成するコードのコードIDの範囲を読み出し、検索コード列の先頭コードのコードID範囲に含まれるコードIDに対応して格納された次コードIDをID関係表から読み出し、該次コードに対応して格納された次コードIDを順次ID関係表から読み出すとともに、ID関係表から読み出した次コードIDがコード別ID範囲読出表から読み出したコードIDの範囲に含まれるか照合する。
(もっと読む)
構造化文書管理装置、及び方法
【課題】構造化文書の構造情報を含む索引であっても適切に圧縮することができる構造化文書管理装置、及び方法を提供する。
【解決手段】索引解析部36が、テキスト情報から分割した語彙毎に、スキーマ識別情報及び識別情報を対応付けた索引情報の個数が閾値を超えた場合に、当該個数分のスキーマ識別情報であるスキーマ識別情報群、及び当該個数分の識別情報である識別情報群毎の分布を解析し、第1圧縮部38が、スキーマ識別情報群の分布解析の結果、所定数を超えるスキーマ識別情報が、スキーマ識別情報と、スキーマ識別情報が属するグループを識別可能なグループ識別情報と、当該グループ内においてスキーマ識別情報を識別可能なグループ内識別情報とを対応付けて記憶する第1ルール記憶部55に記憶されているスキーマ識別情報に一致する場合に、スキーマ識別情報群をグループ識別情報及びグループ内識別情報を用いて圧縮する。
(もっと読む)
情報探索用データ構造、情報探索用記録装置、及び情報探索装置
【課題】本発明は係る事情に鑑みてなされたものであり、上記の記録すべき関連の量を極力減少させ、コンピュータの記憶装置の容量とその記録を行うための人的労力を大幅に減少させる。
【解決手段】ある分類に対する上位分類という概念を用い、複数の選択項目のいくつかをグループ化して記録するとともに、そのグループのうちのどの1つの選択項目が選択された場合でも共通して後に表示される後選択項目を該グループと関連付けて記憶させておくことにより、記録する必要のある関連の数を低減させる。
(もっと読む)
検索装置及びその制御方法、並びにコンピュータプログラム
【課題】アクセス権を考慮した高速の検索を行い、かつアクセス権変更があった場合も迅速に反映される検索方式を提案する。
【解決手段】検索装置であって、文書と、各文書に対する1または複数のユーザからなる1以上のユーザグループのアクセス権に関するアクセス権情報とを格納する文書データベースと、文書データベースを検索するための検索索引を、文書のそれぞれと関連づけて登録する検索索引テーブルと、検索指示を受け付ける受付手段と、アクセス権情報に変更があるか否かを判定する判定手段と、検索索引テーブルを用い、判定手段における判定結果に基づいて文書を検索する検索手段とを備える。
(もっと読む)
1 - 20 / 47
[ Back to top ]