
Fターム[5B091BA03]の内容
Fターム[5B091BA03]の下位に属するFターム
定型文 (96)
Fターム[5B091BA03]に分類される特許
1 - 20 / 218
コーパス変換装置、コーパス変換方法、およびプログラム
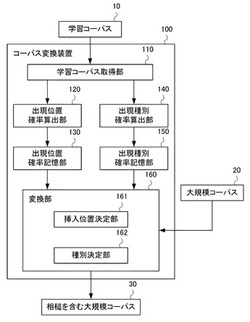
【課題】大規模な書き言葉コーパスを相槌を含む大規模なコーパスに変換すること。
【解決手段】コーパス変換装置100は、相槌を含む学習コーパス10の文を取得する学習コーパス取得部110と、コーパス取得部110で取得した文に基づいて、文長毎に、文中の各位置の相槌の出現確率を算出する出現位置確率算出部120と、算出した出現確率を文長および文中の位置に対応つけて記憶する出現位置確率記憶部130と、学習コーパス取得部110で取得した文に基づいて、相槌の種別毎に、文中の各位置の相槌の出現確率を算出する出現種別確率算出部140と、算出した出現確率を相槌の種別および文中の位置に対応つけて記憶する出現種別確率記憶部150と、出現位置確率記憶部130と出現種別確率記憶部150とに基づいて、大規模コーパス30の文に相槌を挿入し、相槌を含む大規模なコーパスを構築する変換手段と、を備える。
(もっと読む)
文変換装置およびそのプログラム

【課題】大量の文例によることなく、入力される文の文法構造を利用して、平易な文に変換することのできる文変換装置を提供する。
【解決手段】係り受け解析部は、文データを入力し前記文データの係り受け関係を解析し係り受け構造データを出力する。修飾句認定部は、係り受け構造データに基づき文データに含まれる修飾句を抽出するとともに、属性認定用辞書を参照することによって、抽出された修飾句ごとの属性を認定する。対象修飾句判定部は、修飾句認定部によって認定された属性に基づいて、修飾句が変換対象の修飾句か否かを判定する。長さ判定部は、修飾句の長さに応じて変換対象とするか否かを判定する。文変換部は、文変換規則記憶部から読み出した文変換規則に基づいて、変換対象と判定された修飾句を文に変換して出力する。文短縮部は、変換対象とした修飾句に対応して元の文データを短縮する。
(もっと読む)
機械翻訳装置、機械翻訳方法および機械翻訳プログラム
【課題】原言語文の多様性に対応することができる機械翻訳装置を低コストで開発することである。
【解決手段】本実施形態の機械翻訳装置は、第1言語による原言語文を第2言語による目的言語文に翻訳する機械翻訳装置であって、原言語文変換手段と翻訳手段と命題文変換手段とを備える。原言語文変換手段は、第1言語による原言語文から表現素性を抽出し、前記原言語文を、前記表現素性を含まない原言語命題文に変換する。翻訳手段は、前記原言語命題文を前記第2言語による目的言語命題文に翻訳する。命題文変換手段は、前記表現素性に基づいて、前記目的言語命題文を第2言語による目的言語文に変換する。
(もっと読む)
ガイド装置付きカメラおよびガイド付き撮影方法
【課題】 コミュニケーションをとる相手の使用言語が不明の場合であっても言語を判定することのできるガイド装置およびガイド方法を提供する。
【解決手段】 画像記録時に、時計情報や設定したキーワード情報等の関連情報を画像に関連付けを行なう。また表情等によりステップS45において関連付けの候補を選択し、後述するステップS17で選択したフレーズ等の言語情報の関連付けを行なう。次に、関連付けを行なう情報が言語情報か否かの判定を行なう(S7)。判定の結果、言語情報ではない場合には、スキップして次のステップS9に進み、言語情報の場合には、その言語を翻訳する(S8)。すなわち、被写体20の使用言語でも関連付け情報が添付されるように翻訳を行なう。続いて、画像データの記録を行う(S9)。
(もっと読む)
電子ペン・システム、コンピュータ装置、端末及びプログラム
【課題】電子ペンで記入されたストロークにより表わされる第1言語の文字列の適切な配置状態を維持したまま、翻訳した第2言語の文字列を表示させる。
【解決手段】コンピュータ装置3は、電子ペンから受信したストローク情報を第1言語の文字列の文字情報として認識し、認識された第1言語の文字列を表示する表示枠を、そのサイズ及び配置を認識し、認識された文字情報、並びに、認識された表示枠のサイズ及び配置を含む情報を端末4へ送信する。端末4は、コンピュータ装置3から送信されてくる情報を取得し、取得された情報のうち、文字情報により表わされる第1言語の文字列を、第2言語の文字列に翻訳し、第2言語への翻訳後の文字列を表示枠に対応する枠に、文字サイズを調整して表示させる。
(もっと読む)
テキストセグメンテーションのための方法、コンピュータプログラム製品およびシステム
【課題】テキストのさまざまな特徴を十分に考慮して、テキストを複数のテキストセグメントにセグメント化する方法およびシステムを提供する。
【解決手段】方法は、テキストの複数の分割点のうちの1以上の分割点に対応する1以上の入力ラベルをユーザから受信することを含む。テキストの複数の分割点は1以上のセグメントヒューリスティックをテキストに適用することによって取得される。ユーザによって提供される1以上の入力ラベルは、テキストの複数の分割点をラベル付けするために用いられる。ラベル付けに応答して検証が実行されて、複数の分割点のうちのある分割点が妥当な分割点であるかどうかが特定される。その後、検証に基づいて、妥当な分割点の組が複数の分割点のうちの1以上の分割点で更新される。分割点の組は複数のセクションを認識するためのテキストのセグメント化を可能にする。
(もっと読む)
プログラム及び情報処理装置
【課題】文中で単語が持つ役割に関係して異なることを考慮に入れた、同意関係ないし含意関係の判断を行う。
【解決手段】単語の表す概念、または単語そのものに対して、関連し得る述語と、当該述語との意味上の関係を表す意味関係情報と、当該単語が述語とともに現れるときに当該単語が文中で持つ役割を表す役割情報とを互いに関連づけて保持し、処理対象となる一対の文について、一方の文に含まれる単語と、役割情報が共通する少なくとも一つの単語、または役割情報が共通する概念に対応する少なくとも一つの単語が、他方の文に含まれるか否かを解析し、当該解析手段の解析の結果に基づき、一対の文が、互いに意味が同じ同意関係、または、一方の処理対象文の意味が、他方の処理対象文の意味を含む含意関係にあるか否かを判定する。
(もっと読む)
翻訳装置、翻訳プログラムおよび翻訳方法
【課題】各翻訳部品を整合性のとれた自然な文に組み合わせること。
【解決手段】翻訳装置100は、翻訳対象となる文章を、複数の構造部品に分割し、各構造部品のパターンに対応する文法によって機械翻訳することで、複数の翻訳部品を作成する。そして、翻訳装置100は、翻訳部品の主要部を特定し、主要部を変数に置き換えた検索キーおよび主要部をそのままにした検索キーを作成する。翻訳装置100は、主要部を変数に置き換えた検索キーよりも、変数に置き換えていない検索キーのほうが優位になるように、検索キーに重みをつける。翻訳装置100は、各検索キーを利用して、コーパスデータ103dを検索し、ヒット数と検索キーの重みに基づいて、翻訳候補を評価する。
(もっと読む)
情報処理装置、自然言語解析方法、プログラムおよび記録媒体
【課題】 係り受け構造を有する照会パターンに対する文のマッチング・スコアを演算すること。
【解決手段】 本発明の情報処理装置100は、解析対象の文150と、照会パターン160と、上記文内の言語単位間の係り易さを指標する指標値170とを入力として取得する入力部110と、文が照会パターンにマッチする程度を指標するマッチングのスコアを、上記照会パターン160に含まれる各係り受け関係が対応付けられる各指標値を少なくとも変数とする関数で表して演算するスコア演算部120とを含む。スコア演算部120は、上記照会パターンの部分構造と文の範囲との対応付けを試行して、上記関数の部分演算結果を、再利用するため記憶領域130に格納しながら、この部分構造および範囲の内部に関して再帰的に演算することによって、上記スコアを算出する。
(もっと読む)
用語対訳抽出装置、用語対訳抽出方法、および用語対訳辞書の生産方法
【課題】従来、正しい用語対訳を自動抽出する場合、学習データや対訳辞書が必要であった。
【解決手段】対訳データベースから1以上の品詞情報パターンに合致する1以上の対訳フレーズを取得する対訳フレーズ取得部と、対訳フレーズ取得部が取得した1以上の対訳フレーズから、第一言語の用語と用語に対応する第二言語の用語の組の候補である1以上の用語対訳候補を取得する用語対訳候補取得部と、2以上の異なる方法により、2以上の各用語対訳候補に対して、スコアを算出し、2以上のスコアを取得するスコア算出部と、2以上のスコアを用いて、2以上の用語対訳候補のうちの一部を選択して蓄積する用語対訳蓄積部とを具備する用語対訳抽出装置により、正しい用語対訳を自動抽出する場合、学習データや対訳辞書が不要である。
(もっと読む)
機械翻訳装置、方法およびプログラム
【課題】翻訳結果を得るまでの時間を短縮できるとともに、信頼度の高い機械翻訳結果を得ることができる機械翻訳装置を提供する。
【解決手段】言い換え文生成手段81は、入力されたテキスト文と同一の言語でそのテキスト文の内容を示す別の表現へ言い換えた1つまたは複数の言い換え文を生成する。機械翻訳手段82は、言い換え文を翻訳後の言語である目的言語へと機械翻訳する。翻訳信頼度決定手段83は、目的言語へ翻訳された言い換え文の信頼度を示す翻訳信頼度を決定する。言い換え文特定手段84は、言い換え文生成手段81が生成した言い換え文の中から、翻訳信頼度に基づいて言い換え文の候補を抽出し、候補の中から翻訳の対象とする言い換え文である翻訳対象言い換え文を特定する。
(もっと読む)
文書処理装置及びプログラム
【課題】曖昧文を検出する際に、過剰検出や不適切な指摘内容の発生を低減させ、曖昧文の検出精度を向上できる。
【解決手段】実施形態の構文解析手段は、前記入力を受け付けた文を構文解析し、構文解析結果を得る。実施形態の抽出手段は、この構文解析結果に基づいて、前記場合に該当する文の構文解析結果から係り受け元、複数の係り受け先を含む係り受け情報を抽出する。実施形態の関係情報補正手段は、前記構文解析結果及び前記関係情報補正ルールに基づいて、前記係り受け情報が前記第1乃至第4の関係のいずれかに該当するか否かを検査すし、該当する係り受け情報に対して、前記関係情報補正ルールに規定された補正処理を行う。実施形態の指摘情報生成手段は、前記関係情報補正手段による処理の結果に基づいて、前記第1乃至第4の関係のいずれにも該当しないとき、前記曖昧文である旨を指摘する指摘情報を生成し、この指摘情報を出力する。
(もっと読む)
文章入力支援システム、文章入力支援装置、参照情報作成装置及びプログラム
【課題】利用者による操作入力に基づく作成中の文について、その続きに入力されることが予測される候補を提示するに際し、文が有する係り受け関係の情報を用いて候補となる語を提示する。
【解決手段】テキスト分割部32が、テキスト取得部31により得られた作成中(編集中)の文を形態素解析して形態素単位の語(文字列)に分割し、構文・意味解析部33がテキスト分割部32により得られた各語の係り関係及び意味役割を解析し、補完候補評価部34が、構文・意味解析部33による解析結果(文字入力位置の前の語に対する他の語の係り関係及び意味役割の関係)に基づいて、各種スコアDB12を参照して補完入力候補となる候補語を検索すると共に各候補語のスコアを算出し、補完候補提示部36が、補完候補評価部34により得られた候補語をスコア順に提示する。
(もっと読む)
言語モデル学習装置、言語モデル学習方法、言語解析装置、及びプログラム
【課題】事前に与えた基準を守りつつ、それと異なる新しい文字列又は記号列を高精度に分割する。
【解決手段】識別モデルパラメータ更新部25によって、NPYLMをCRFに変換し、変換したCRFの各エッジの重みと、CRFにおける対応するエッジの重みとを用いて第1の統合モデルを作成し、第1の統合モデルを、教師ありデータに基づいて学習する。生成モデルパラメータ更新部26によって、CRFをSemi−Markov CRFに変換し、Semi−Markov CRFの各エッジの重みとNPYLMの対応するエッジの重みとを用いて第2の統合モデルを作成し、第2の統合モデルを、教師なしデータに基づいて学習する。収束判定部27によって所定の収束条件を満たしたと判定されるまで、識別モデルパラメータ更新部25による更新と生成モデルパラメータ更新部26による更新とを交互に繰り返す。
(もっと読む)
文書処理装置及びプログラム
【課題】 目的語と述語が離れている文の検出精度を向上させる。
【解決手段】 実施形態の言語解析手段は、前記入力を受け付けた文を言語解析し、言語解析結果を得る。実施形態の抽出手段は、前記言語解析結果から前記文の目的語と述語を抽出する。実施形態の距離診断手段は、前記抽出された目的語と述語との前記文内での距離が予め設定された基準よりも大きいか否かを診断する。実施形態の述語省略診断手段は、前記距離診断手段による診断の結果、距離が大きい場合、前記抽出された目的語と前記言語解析手段による言語解析結果と前記述語省略診断ルールとに基づいて、当該目的語に対して述語が省略されている場合に該当するか否かを診断する。実施形態の第1の指摘情報生成手段は、前記述語省略診断手段による診断の結果、該当しない場合、前記目的語と前記述語とが離れている旨の指摘情報を生成し、この指摘情報を出力する。
(もっと読む)
トピック作成支援装置、トピック作成支援方法およびトピック作成支援プログラム
【課題】トピック作成の作業負担を軽減し、且つ、トピックの質を均質化すること。
【解決手段】トピック作成支援装置1は、ニュース記事情報記憶手段2から見出しを構成する見出し情報を抽出し、抽出された見出し情報を文節で区切って、複数の文節要素に分割する。そして、トピック作成支援装置1は、分割された各文節要素に対して、少なくとも品詞の特性或いは品詞の活用に応じて予め定められた重み付け判定データに基づいて、重み付けを行い、重み付けされた文節要素のうち、重み付けの度合いが大きい文節要素を抽出する。そして、トピック作成支援装置1は、抽出された文節要素の文字数が13文字以下である場合には、抽出された文節要素を文章情報のトピック候補としてディスプレイ3に出力する。
(もっと読む)
ファイルフォーマット、サーバ、電子コミックのビューワ装置および電子コミック生成装置
【課題】電子コミックにおいて、オリジナルの言語のセリフ、およびオリジナルの言語のセリフから任意の言語に変換されたセリフの文字列を過不足なく吹き出し領域内に配置可能にするファイルフォーマットを提供する。
【解決手段】ユーザ端末は、スクロールビューまたはコマビューのいずれであっても、ファイルフォーマットの吹き出し領域の情報に基づき、各吹き出し内の台詞を示す第1のテキスト情報を表示でき、オリジナルの言語のセリフ、およびオリジナルの言語のセリフから任意の言語に変換されたセリフの文字列を吹き出し領域に過不足なく配置することができる。
(もっと読む)
翻訳装置、翻訳システム、翻訳方法および翻訳プログラム
【課題】翻訳精度を向上する翻訳装置、翻訳システム、翻訳方法および翻訳プログラムを提供する。
【解決手段】翻訳装置100は、複数の翻訳結果に含まれる単語または単語列の対応関係を、当該単語または単語列を訳語とする原文中の単語または単語列とから決定する対応照合部102と、対応関係にある複数の単語または単語列を比較する比較部104と、比較した結果を統合する結果統合部106と、を備える。
(もっと読む)
文書処理装置、方法、及びプログラム
【課題】異なる言語の一方の文章から他方の文章には含まれない新しい情報を自動的に抽出することにより、共同支援システムにより記述された記事の編集者を支援する。
【解決手段】英語の記事(各文ei)及び中国語の記事(各文cj)を同一の言語に翻訳し、翻訳後の英語の記事の各文ei’と、翻訳後の中国語の記事の各文cj’との類似度を、ei’とcj’との全ての組み合わせについて計算し、各文ei’から最大類似度が最小の文からN個の文を抽出して、対応する翻訳前の英語の文に、新しい情報を含む文であることを示すフラグ「+1」を付与する。英語及び中国語の各文をノード、ノード間の関係を類似度に応じた重み付きエッジで表したグラフを作成し、フラグ「+1」の英語の文を表すノードにラベル1、その他に0を付与し、ラベル伝播により付与されたラベルが最大のノードに対応する中国語の文の前または後を、挿入位置として決定する。
(もっと読む)
音声翻訳装置、方法、及びプログラム
【課題】円滑なコミュニケーションを実現できる。
【解決手段】音声翻訳装置は、入力部、音声認識部、感情認識部、平静文生成部、翻訳部、補足文生成部、及び音声合成部を含む。入力部は、第1言語の音声を音声信号に変換する。音声認識部は、音声信号を音声認識処理し文字列を生成する。感情識別部は、文字列がどの感情種別を含むかを識別して1以上の感情種別を含む感情識別情報を得る。平静文生成部は、感情に伴って語句が変化した非平静語句と、非平静語句に対応しかつ感情による変化を伴わない平静語句とを対応付けたモデルより、文字列に第1言語の非平静語句が含まれる場合、第1言語の非平静語句を対応する第1言語の平静語句に変換した平静文を生成する。翻訳部は、平静文を第2言語に翻訳した訳文を生成する。補足文生成部は、感情識別情報の感情種別を第2言語で説明する補足文を生成する。音声合成部は、訳文と補足文とを音声信号に変換する。
(もっと読む)
1 - 20 / 218
[ Back to top ]